


Optimizing SQL for data sets is relevant no matter the size of the data set, but it’s especially crucial when dealing with large unstructured data.
Ignoring optimization can lead to issues like slow query execution, high resource consumption and potential data loss. By optimizing SQL, you manage the performance of your database in terms of speed and space efficiency, allowing faster data retrieval from larger tables within shorter time frames.
4 SQL Query Optimization Techniques for Large Data Sets
- Avoid using
SELECT*. - Choose the correct
JOINoperation: These include left join, inner join, right join and outer join. - Use common table expressions.
- Manage data retrieval volume with
LIMITandTOP.
Whether you’re a seasoned SQL developer or preparing for an upcoming SQL interview, these insights ensure your database will operate with unparalleled efficiency.
How to Choose the Right Database Index
When considering database indexing, both clustered and non-clustered indexes play a crucial role in determining your database’s performance. The precision and strategic implementation of these indexes are vital aspects that significantly impact the overall efficiency of your database system. It’s important to know when to use each type of index to maximize the benefits they bring.
Clustered Indexes
A clustered index organizes the data rows on the disk to mirror the index’s order. This leads to highly efficient data retrieval for columns that are frequently accessed. Think of it like a well-organized bookshelf where every book is exactly where you expect it to be. However, a table can only have one clustered index, so it’s crucial to apply it judiciously. It’s best to apply it to columns that are frequently searched for, and the data is largely unique.
To implement a clustered index on a database table, follow these steps:
- Select the table and column(s) for the index based on query usage and data distribution.
- Review current indexes to avoid conflicts with the new clustered index; adjust or remove as needed.
- Use the appropriate SQL command based on your database management system (DBMS).
- Verify the index’s creation and impact on query performance.
-- SQL Server
CREATE CLUSTERED INDEX IX_Country ON Customers (Country);Consider scheduling index creation during off-peak hours to minimize disruptions and assess the effects on data operations.
Non-clustered Indexes
Non-clustered indexes act as a sophisticated directory that points to the data located in a different spot from the table’s actual data storage. These indexes allow for the creation of multiple reference points, each fine-tuned for specific query optimizations. Think of non-clustered indexes as creating a network of swift shortcuts to your data.
It’s most useful for columns that have a wide range of values and are infrequently updated. While non-clustered indexes are generally more versatile than clustered indexes, they do come with some trade-offs. For example, they require more storage space and can potentially slow down data inserts and updates.
To implement a non-clustered index on a database table, here are the recommended steps:
- Identify the table and column(s) that will benefit most from a non-clustered index, considering the columns used in
WHEREclauses or asJOINpredicates. - Evaluate existing indexes to ensure the new index will complement rather than conflict with them.
- Use the specific SQL syntax for creating a non-clustered index according to your DBMS.
- After implementing the index, monitor query performance and adjust the index as necessary to optimize speed and resource usage.
-- SQL Server
CREATE NONCLUSTERED INDEX IX_Country ON Customers (Country);Creating and managing indexes requires careful planning and ongoing evaluation for efficient performance. Regularly review and adjust your indexing strategy to maintain optimal database performance as data grows and query requirements change.
The main difference between clustered and non-clustered indexes is in how data is physically organized on disk. Clustered indexes reorder data rows, while non-clustered indexes point to data locations. Both types are crucial for optimizing SQL with large data sets and efficient data retrieval.
Optimizing Text Column Indexing
Beyond the classic index types, there’s a specialized approach for text columns: full-text search indexes. Optimizing text columns with these indexes elevates your database’s search capabilities beyond simple pattern matching, enabling complex searches through large volumes of text with remarkable ease. It’s essential to harness the full potential of these text-specific indexes to ensure that your database remains as responsive as the speed of thought.
You can implement this by creating a full-text index on your database table, which indexes text columns based on the words and phrases they contain. This allows for faster search results when looking for specific words or phrases in large blocks of text, with minimal overhead.
-- Create a table to store articles
CREATE TABLE articles (
article_id INT PRIMARY KEY,
article_content TEXT
);
-- Insert some sample articles into the table
INSERT INTO articles (article_id, article_content) VALUES
(1, 'Breaking news'),
(2, 'Global news'),
(3, 'Local news');
-- Create a full-text index on the 'article_content' column
CREATE FULLTEXT INDEX idx_article_content ON articles (article_content);
-- Query using full-text search
SELECT * FROM articles WHERE MATCH(article_content) AGAINST('global');
-- Query using full-text search with additional conditions
SELECT * FROM articles WHERE MATCH(article_content) AGAINST('news' IN BOOLEAN MODE);Full-text indexes use a process called tokenization to break down text into smaller units, making it easier and faster for databases to search through. This feature enables the full-text index to function as an inverted index.
To optimize text column indexing further, you can also specify additional parameters such as stop words and language-specific word breakers. Stop-words are commonly occurring words that do not add value to the search results, such as "the", "a", and "and". By specifying a list of stop words, the full-text index can exclude these words from the indexing process, resulting in more accurate and efficient search results.
An effective indexing strategy is not merely about implementing indexes; it’s about executing the correct indexing for the task at hand. As a best practice, remind yourself of this guiding principle: Index with intention and accessibility to your data will follow.
Query Optimization Techniques
Efficient queries are the lifeblood of high-performance databases, and mastering this can lead to significant improvements in retrieval speed and resource utilization.
Whether you’re wrangling basic pulls or orchestrating complex data symphonies with multiple joins, savvy query crafting can dramatically reduce response times and system load.
Avoid using SELECT *
Let’s adopt a strategic approach akin to an expert chess player. Instead of the indiscriminate approach of `SELECT *`, which essentially sweeps up all columns irrespective of their immediate utility, Instead, focus on selecting only the essential columns. This targeted selection is like executing a well-planned move that ensures your query performs with optimal speed and efficiency.
Choose the Correct JOIN Operation
When it comes to JOIN Operations, envision them as delicate stitches that bind tables together in a cohesive unit. The key lies in selecting the right type of join — LEFT, RIGHT, OUTER or INNER — to ensure your data’s integrity and query performance remain flawless. It’s a precise choice, much like selecting the correct thread for fabric, that can make or break the outcome.
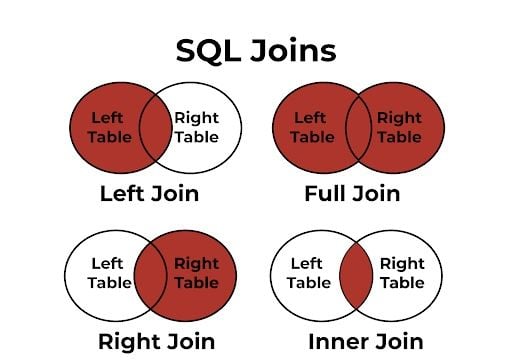
Left Join Example
A left join returns all rows from the left table (employees) and the matching rows from the right table (departments). If there is no match, NULL values are returned for the right table columns.
SELECT
employees.employee_id,
employees.employee_name,
employees.department_id,
departments.department_name
FROM
employees
LEFT JOIN departments ON employees.department_id = departments.department_id;
Inner Join Example
An inner join returns only the rows where there is a match in both tables based on the specified condition.
SELECT
employees.employee_id,
employees.employee_name,
employees.department_id,
departments.department_name
FROM
employees
INNER JOIN departments ON employees.department_id = departments.department_id;
Right Join
A right join returns all rows from the right table (departments) and the matching rows from the left table (employees). If there is no match, NULL values are returned for the left table columns.
SELECT
employees.employee_id,
employees.employee_name,
employees.department_id,
departments.department_name
FROM
employees
RIGHT JOIN departments ON employees.department_id = departments.department_id;
Outer Join
An outer join returns all rows when there is a match in either the left or right table. If there is no match, NULL values are returned for the columns of the table without a match.
SELECT
employees.employee_id,
employees.employee_name,
employees.department_id,
departments.department_name
FROM
employees FULL
OUTER JOIN departments ON employees.department_id = departments.department_id;
Use Common Table Expressions
Subqueries in a large data set can introduce a maze of complexities. Instead, familiarize yourself with common table expressions. Common table expressions (CTEs) enhance the readability of your SQL statements and present a more orderly alternative streamlining performance.
CTE Example
CTE is a named temporary result set that you can reference within a SELECT, INSERT, UPDATE or DELETE statement. It helps simplify complex queries and makes them more readable.Let’s use the same employees and departments tables for this example:
WITH EmployeeDepartmentCTE AS (
SELECT
employees.employee_id,
employees.employee_name,
employees.department_id,
departments.department_name
FROM
employees
INNER JOIN departments ON employees.department_id = departments.department_id
) -- Query using the CTE to filter employees in a specific department
SELECT
*
FROM
EmployeeDepartmentCTE
WHERE
department_name = 'IT';
Manage Data Retrieval Volume With Limit and TOP
Think of ‘LIMIT’ and ‘TOP’ clauses as your database’s velvet rope. They’re the discerning gatekeepers that ensure only the necessary data makes it through, preventing your server from becoming overwhelmed with excess rows.
Limit and Offset Example
-- Selecting rows 6 to 10 from the employees table
SELECT employee_id, employee_name, department_id
FROM employees
LIMIT 5 OFFSET 5;
Performance Monitoring and Fine-Tuning
Diving into the world of performance monitoring is like being a detective. You’re on the hunt for clues that’ll reveal the bottlenecks slowing down your SQL queries.
This involves tirelessly working in the background to detect and flag any performance dips as they occur. Picture setting up a state-of-the-art dashboard that immediately alerts you to even the slightest hiccup in query performance. This level of vigilance is crucial for maintaining an eagle-eyed watch over your database’s health.
Union Operators
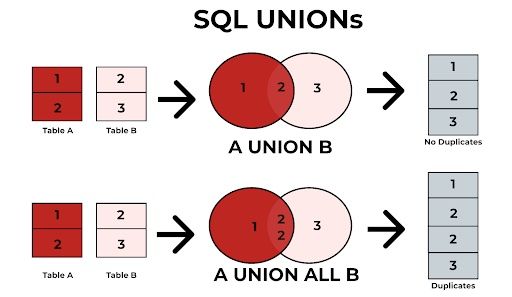
When you need to stitch together results from multiple select statements, your go-to stitch has been `UNION`. But, there’s a twist—switch over to `UNION ALL` and watch the performance of your queries soar. Unlike `UNION`, which painstakingly removes duplicates causing overhead, `UNION ALL` is like a free-flowing river, combining results swiftly without the additional baggage of checking for duplicates. `UNION ALL` trusts your data’s originality and doesn’t second-guess it, leading to faster results.
UNION ALL Example
-- Combining the current employees and former employees using UNION ALL
SELECT employee_id, employee_name, department_id
FROM employees
UNION ALL
SELECT former_employee_id, former_employee_name, former_department_id
FROM former_employees;
‘EXISTS’ vs. ‘IN’
When affirming the existence of data, prefer ‘EXISTS’ over ‘IN’ for a more efficient query operation. The ‘EXISTS’ predicate halts upon the first encounter, akin to a quick glance to confirm the presence, whereas ‘IN’ can unnecessarily extend the search. This strategic choice can significantly expedite query run times.
Example of EXISTS
-- Checking if there are employees in the 'IT' department
SELECT department_name
FROM departments
WHERE EXISTS (
SELECT 1
FROM employees
WHERE employees.department_id = departments.department_id
AND employees.department_id = 'IT'
);In this example, the outer query selects the department_name from the departments table. The EXISTS clause is used in the WHERE clause to check if there are any employees in the ‘IT’ department. The subquery returns a result of 1 if there are such employees, and the EXISTS condition is satisfied.
Mastering the nuances of SQL performance tuning is a journey that requires a meticulous approach to data management and an understanding of the vast array of optimization techniques available.
Just as a finely tuned instrument can elevate performance to new heights, a well-optimized database can dramatically enhance your application’s responsiveness and efficiency. Whether you’re navigating the data currents in a professional capacity or gearing up for a SQL interview, the dedication to optimizing your SQL abilities will surely pay off in the fast-paced technological arena we operate in today.



