

Term frequency-inverse document frequency (TF-IDF) is a natural language processing (NLP) technique that’s used to measure the importance of different words in a sentence. It cancels out the incapabilities of the bag of words technique, which is good for text classification or for helping a machine learning model read words.
Term Frequency-Inverse Document Frequency (TF-IDF) Explained
TF-IDF is a natural language processing (NLP) technique that’s used to evaluate the importance of different words in a sentence. It’s useful in text classification and for helping a machine learning model read words.
In this article, we’ll explore how to create a TF-IDF model in Python from scratch. Here’s what we’ll cover in the article:
- Terminology
- Term frequency(TF)
- Document frequency (DF)
- Inverse document frequency (IDF)
- TF-IDF Implementation in Python
TF-IDF Terms to Know
Below are the terms you’ll need to understand to create a TF-IDF model.
- t — term (word).
- d — document (set of words).
- N — count of corpus.
- corpus — the total document set.
What Is Term Frequency (TF) in TF-IDF?
Suppose we have a set of English text documents and wish to rank which document is most relevant to the query, “Data Science is awesome!” One way to start out is to eliminate documents that don’t contain all three words: “Data,” “is,” “Science” and “awesome,” but this still leaves too many documents. To further distinguish them, we might count the number of times each term occurs in each document. The number of times a term occurs in a document is called its term frequency.
The weight of a term that occurs in a document is simply proportional to the term frequency.
TF Formula
tf(t,d) = count of t in d / number of words in d
What Is Document Frequency in TF-IDF?
Document frequency (DF) measures the importance of a document in a whole set of corpus. This is very similar to TF. The only difference is that TF is a frequency counter for a term t in document d, whereas DF is the count of occurrences of term t in the document set N. In other words, DF is the number of documents in which the word is present. We consider one occurrence if the term consists in the document at least once. We don’t need to know the number of times the term is present.
DF Formula
df(t) = occurrence of t in documents
What Is Inverse Document Frequency (IDF) in TF-IDF?
While computing TF, all terms are considered equally important. However, certain terms, such as “is,” “of,” and “that,” may appear a lot of times but have little importance. We need to weigh down the frequent terms while scaling up the rare ones. When we compute IDF, an inverse document frequency factor is incorporated, which diminishes the weight of terms that occur very frequently in the document set and increases the weight of terms that rarely occur.
IDF is the inverse of the document frequency, which measures the informativeness of term t. When we calculate IDF, it will be very low for the most occurring words, such as stop words like “is.” That’s because those words are present in almost all of the documents, and N/df will give a very low value to words like that.
This finally gives us what we want, a relative weightage:
idf(t) = N/df
Now, there are few other problems with the IDF. If you have a large corpus, say 100,000,000, the IDF value explodes. To avoid this, we take the log of IDF.
During the query time, when a word that’s not in the vocabulary occurs, the DF will be 0. Since we can’t divide by 0, we smoothen the value by adding 1 to the denominator.
And that’s the final formula.
IDF Formula
idf(t) = log(N/(df + 1))
How Does TF-IDF Work?
TF-IDF is a measure used to evaluate how important a word is to a document in a collection or corpus. There are many different variations of TF-IDF, but for now, let’s concentrate on the basic version.
TF-IDF Formula
tf-idf(t, d) = tf(t, d) * log(N/(df + 1))
How to Create a TF-IDF Model in Python
To make a TF-IDF model from scratch in Python, let’s imagine these two sentences from a different document:
first_sentence: “Data Science is the sexiest job of the 21st century”.second_sentence: “machine learning is the key for data science”.
1. Create the TF Function
First, we have to create the TF function to calculate total word frequency for all documents.
As usual, we should import the necessary libraries:
import pandas as pd
import sklearn as sk
import mathNext, let’s load our sentences and combine them together in a single set:
first_sentence = "Data Science is the sexiest job of the 21st century"
second_sentence = "machine learning is the key for data science"
#split so each word have their own string
first_sentence = first_sentence.split(" ")
second_sentence = second_sentence.split(" ")#join them to remove common duplicate words
total= set(first_sentence).union(set(second_sentence))
print(total)
Output:
{'data', 'Science', 'job', 'sexiest', 'the', 'for', 'science', 'machine', 'of', 'is', 'learning', '21st', 'key', 'Data', 'century'}
Now, lets add a way to count the words using a dictionary key-value pairing for both sentences:
wordDictA = dict.fromkeys(total, 0)
wordDictB = dict.fromkeys(total, 0)
for word in first_sentence:
wordDictA[word]+=1
for word in second_sentence:
wordDictB[word]+=1Then, we put them in a dataframe and view the result:
pd.DataFrame([wordDictA, wordDictB])
Now, let’s write the TF function:
def computeTF(wordDict, doc):
tfDict = {}
corpusCount = len(doc)
for word, count in wordDict.items():
tfDict[word] = count/float(corpusCount)
return(tfDict)
#running our sentences through the tf function:
tfFirst = computeTF(wordDictA, first_sentence)
tfSecond = computeTF(wordDictB, second_sentence)
#Converting to dataframe for visualization
tf = pd.DataFrame([tfFirst, tfSecond])
And this is the expected output:

That’s all for the TF formula.
2. Eliminate the Stop Words
Now, let’s talk about how to eliminate stop words, which are the most commonly occuring words that don’t give any additional value to the document vector. Removing these will increase computation and space efficiency.
nltk library has a method to download the stop words. So, instead of explicitly mentioning all the stop words ourselves, we can just use the nltk library and iterate over all the words and remove the stop words. There are many efficient ways to do this, but I’ll just give a simple method.
Here’s a sample of a stop words in the English language:

This is the code you can use to download stop words and remove them.
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtered_sentence = [w for w in wordDictA if not w in stop_words]
print(filtered_sentence)
Output:
['data', 'Science', 'job', 'sexiest', 'science', 'machine', 'learning', '21st', 'key', 'Data', 'century']
3. Create the IDF Function
Now that we’ve finished the TF section, let’s move onto the IDF part:
def computeIDF(docList):
idfDict = {}
N = len(docList)
idfDict = dict.fromkeys(docList[0].keys(), 0)
for word, val in idfDict.items():
idfDict[word] = math.log10(N / (float(val) + 1))
return(idfDict)
#inputing our sentences in the log file
idfs = computeIDF([wordDictA, wordDictB])
4. Calculate TF-IDF
And now that we’ve implemented the idf formula, let’s finish with calculating the TF-IDF:
def computeTFIDF(tfBow, idfs):
tfidf = {}
for word, val in tfBow.items():
tfidf[word] = val*idfs[word]
return(tfidf)
#running our two sentences through the IDF:
idfFirst = computeTFIDF(tfFirst, idfs)
idfSecond = computeTFIDF(tfSecond, idfs)
#putting it in a dataframe
idf= pd.DataFrame([idfFirst, idfSecond])
print(idf)
Output:

That was a lot of work. But it’s handy to know if you’re asked to code TF-IDF from scratch in the future.
How to Create a TF-IDF Model Using Sklearn?
It’s a lot easier to create a TF-IDF model using the Sklearn library than doing it from scratch. Let’s look at the example below:
#first step is to import the library
from sklearn.feature_extraction.text import TfidfVectorizer
#for the sentence, make sure all words are lowercase or you will run #into error. for simplicity, I just made the same sentence all #lowercase
firstV= "Data Science is the sexiest job of the 21st century"
secondV= "machine learning is the key for data science"
#calling the TfidfVectorizer
vectorize= TfidfVectorizer()
#fitting the model and passing our sentences right away:
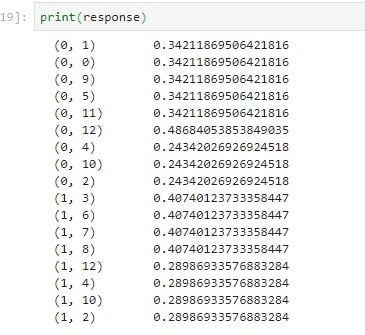
response= vectorize.fit_transform([firstV, secondV])
And this is the expected output:
In this post, we’ve covered how to use Python and a NLP technique known as term frequency-inverse document frequency (TF-IDF) to summarize documents. We used Sklearn along with nltk to accomplish this task.


