

SQL (Structured Query Language) is a programming language used to manage data in relational databases. It is used to retrieve, manipulate, and analyze the data stored there. SQL allows users to easily filter, aggregate, and join data from multiple tables, making it a powerful tool for data exploration and analysis.
SQL is an essential tool for data analysts, data scientists, data engineers, and business intelligence analysts. Additionally, many business intelligence and data visualization tools use SQL as their primary means of querying data, so proficiency in SQL is necessary for working with them effectively.
If you’re interviewing for any of these roles, you’ll need to demonstrate your knowledge of SQL by writing queries or answering questions related to SQL syntax and database design. You will also be asked how to optimize the SQL query for better performance and design concepts such as normalization and primary keys. Interviewers are also interested in knowing your experience with specific SQL-related tools or database engines. So, this article will cover some of the most commonly asked SQL questions in interviews. As a note, all the queries listed in the examples below are written in Microsoft SQL Server.
Common SQL Interview Questions
- What are the set operators in SQL?
- What is cross join in SQL?
- How to fetch alternate records from the table.
- What is the difference between the RANK() and DENSE_RANK() functions in SQL?
- What are stored procedures? Why do we need them?
- How to find duplicate records.
- What would happen without an index in an SQL table?
- SQL challenge — Find customers who bought all products.
- Explain the differences between views and tables in SQL.
- SQL challenge — Find the third-highest employee salary in the table.
How to Prepare for an SQL Interview
Here are some skills to make sure you brush up on ahead of your interview.
- SQL syntax and commands: Brush up on the basics of SQL syntax, including
SELECT,FROM,WHERE,GROUP BYandJOINclauses. Practice writing queries to retrieve data from a database and perform various data manipulation tasks. - Database design principles: Familiarize yourself with database design concepts such as normalization, primary keys and foreign keys. Be able to explain how to design a database schema that is efficient and normalized.
- Understand the performance considerations: Understand how to optimize SQL queries for performance and be able to explain how indexes, partitioning and other techniques can improve query performance.
- Data Analysis task: Understand the concepts of data analysis like aggregate functions, filtering, sorting and joining. Be able to explain how to use SQL to perform basic data analysis tasks.
- Real-life scenarios: Practice answering real-world SQL interview questions and be prepared to explain how you would approach solving a specific problem. Many third-party websites are available to practice such skills like Leetcode and Hackerrank.
- Understand Database Engine: If the company you are interviewing with uses a specific database system, such as MySQL, Postgres, Oracle, or SQL Server, familiarize yourself with the unique features and syntax of that system. An SQL database engine is the software component responsible for managing and manipulating the data stored within the database. It is the underlying system that provides the functionality to create, read, update, and delete (CRUD) data in a structured manner. These include popular systems such as MySQL, Oracle and the Microsoft SQL Server.
1. What Are the Set Operators in SQL?
UNION
This operator combines the result set of two or more SELECT statements and returns only distinct rows. The number and the order of columns in the SELECT statements must be the same.
UNION ALL
This operator combines the result set of two or more SELECT statements and returns all rows, including duplicates. The number and the order of columns in the SELECT statements must be the same.
INTERSECT
This operator returns only the rows that are present in both result sets of the SELECT statements. The number and the order of columns in the SELECT statements must be the same.
MINUS
This operator returns only the rows that are present in the first SELECT statement but not in the second one. The number and the order of columns in the SELECT statements must be the same.
EXCEPT
This is an alternative name for MINUS operator. However, EXCEPT is used across a wider range of SQL databases while MINUS is more frequently used with Oracle.
2. What Is Cross Join in SQL?
A cross join, also known as a Cartesian product, is a type of join in SQL that returns the combination of every row from the first table with every row from the second table. The result is a table that contains the number of rows equal to the product of the number of rows in each of the joined tables. It’s best to exercise caution when using cross join since it can produce very large result sets that are difficult to process and lead to issues in performance.
The syntax for a cross join in SQL is:
SELECT column1, column2, ...
FROM table1
CROSS JOIN table2;In this example, the CROSS JOIN keyword is used to combine every row from table one with every row from table two. The result is a table that contains the number of rows equal to the product of the number of rows in table one and table two.
3. How to Fetch Alternate Records From the Table
Table Name: Weather
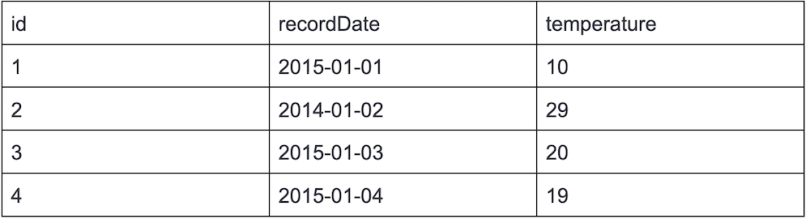
Answer
To fetch alternate records from the above table, we can use the ROW_NUMBER() function to assign a unique number to each row in the table and then use the modulo operator (MOD) to filter out every nth row.
SQL Query
WITH CTE AS (
SELECT *, ROW_NUMBER() OVER (ORDER BY id) as row_num
FROM Weather
)
SELECT *
FROM CTE
WHERE row_num % 2 = 0;This will return all rows with an even row number. To fetch every third row, you would change the query to WHERE row_num % 3 = 0, and so on.
4. What is the Difference Between the RANK() and DENSE_RANK() Functions in SQL?
The RANK() and DENSE_RANK() functions in SQL are used to assign a unique rank to each row within a result set based on the values in one or more columns.
The RANK() function assigns a unique rank to each row within a result set based on the values in one or more columns. If two or more rows have the same values in the specified column(s), they will receive the same rank, and the next rank will be skipped.
For example, if two rows have a rank of two, the next row will have a rank of four.
The DENSE_RANK() function also assigns a unique rank to each row within a result set based on the values in one or more columns. But in this case, if two or more rows have the same values in the specified column(s), they will receive the same rank, and the next rank will not be skipped.
For example, if two rows have a rank of two, the next row will have a rank of three.
Syntax for Rank Function
RANK() OVER ( [PARTITION BY partition_expression, ... ] ORDER BY sort_expression [ASC | DESC], ... )Syntax for Dense_Rank Function
DENSE_RANK() OVER ( [PARTITION BY partition_expression, ... ] ORDER BY sort_expression [ASC | DESC], ... )Both of these functions can be used along with the OVER() clause to specify the column(s) to base the ranking on and the sort order of the ranking.
5. What Are Stored Procedures? Why Do We Need Them?
A stored procedure is a pre-defined set of SQL commands that are saved and can be reused multiple times by a database management system. In simple terms, you can think of a stored procedure as a set of instructions that you can run on a database to accomplish a specific task.
The main reason why we use stored procedures is that they allow us to perform complex or repetitive tasks in a more efficient and organized way. Instead of writing and executing the same SQL commands over and over again, you can create a stored procedure once and then call it whenever you need to perform that specific task.
For example, let’s say you have a database that stores information about customer orders for an e-commerce website. You may need to frequently run a query that retrieves all the customer orders that were placed in the last 30 days. Instead of writing and running the same query every time you need that information, you can create a stored procedure that performs that query and then call it whenever you need the information.
Syntax
CREATE PROCEDURE getRecentOrders
AS
BEGIN
SET NOCOUNT ON;
SELECT * FROM orders
WHERE order_date >= DATEADD(day, -30, GETDATE());
ENDThis stored procedure is named getRecentOrders and it uses a SELECT statement to retrieve all columns from the orders table where the order_date is greater than or equal to 30 days ago (using the DATEADD function). The SET NOCOUNT ON statement is used to prevent the procedure from returning the number of rows affected by the SELECT statement.
We can execute this stored procedure by calling it using the EXEC command:
EXEC getRecentOrders;The syntax and structure of stored procedures may vary depending on the specific database management system.
Another benefit of stored procedures is that they can help to improve the security of your database. By using stored procedures, you can limit the access that users have to the underlying data tables, which can help to prevent unauthorized access and accidental data modification.
Stored procedures can also improve the performance of your database by reducing the amount of data that needs to be transferred between the database and the application. Stored procedures can also be used to minimize the number of database trips.
6. How to Find Duplicate Records
Table: Orders
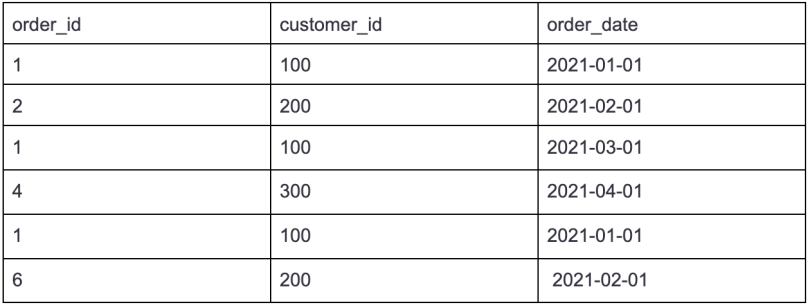
We can find duplicate records by using GROUP BY and HAVING clause
Syntax
SELECT order_id, customer_id, order_date, COUNT(*) as duplicate_count
FROM orders
GROUP BY order_id, customer_id, order_date
HAVING COUNT(*) > 1This query uses the GROUP BY clause to group the results by the order_id, customer_id, and order_date columns, and then uses the COUNT() function to return the number of rows in each group. The HAVING clause is used to filter the results to only include groups where the count is greater than one, which will return all the records that have duplicate values in the selected columns.
7. What Would Happen Without an Index in an SQL Table?
Without an index in an SQL table, searching for specific data within the table would be much slower. This is because the database management system (DBMS) would have to scan every row in the table to find the relevant data, rather than being able to quickly locate it using an index. This process is known as a full-table scan.
When a table is small, the difference in performance may not be significant. As the table grows in size, however, the difference in performance can become substantial. This can lead to slow query performance and may even cause the system to become unresponsive if the table is large enough.
Indexes speed up data retrieval by allowing the DBMS to quickly locate the data it needs. Each index is a separate data structure that stores a copy of the data from one or more columns in the table, along with a pointer to the location of the corresponding data in the table. This allows the DBMS to look up the data it needs in the index rather than having to scan the entire table.
8. SQL Challenge — Customers Who Bought All Products
Table: Customer (Reference: Leetcode)
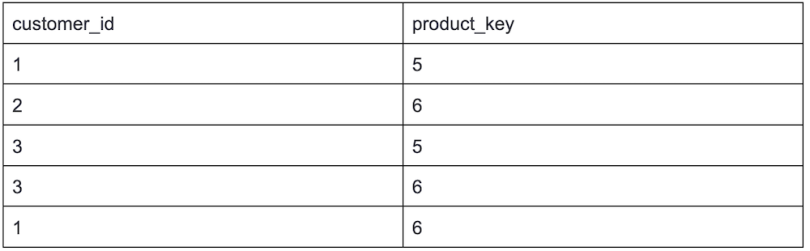
Table: Product
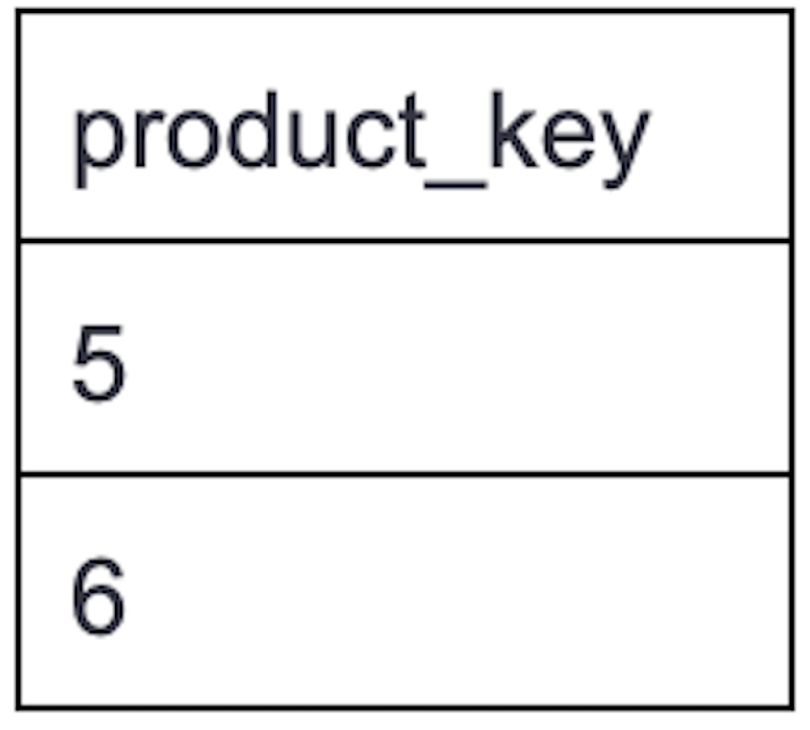
Write an SQL query to report the customer IDs from the Customer table that bought all the products in the Product table.
Expected Output

Answer — SQL Query
SELECT customer_id
FROM Customer
INNER JOIN Product ON Customer.product_key = Product.product_key
GROUP BY customer_id
HAVING COUNT(DISTINCT Product.product_key) = (SELECT COUNT(*) FROM Product)We can solve the above problem by using a combination of the INNER JOIN, GROUP BY, HAVING and COUNT aggregate functions.
The above query first joins the Customer table with the Product table on the product_key column. Then it groups the results by customer_id and counts the number of distinct product_keys that each customer bought.
Then it selects the customer_id from the joined table where the product_count is equal to the total number of products in the Product table. The COUNT(DISTINCT Product.product_key) ensures that a customer is only counted once for each unique product that they bought.
The query then uses a HAVING clause to filter out only those customers whose product_count matches the total number of products in the Product table.
9. Explain the Differences Between Views and Tables in SQL
In SQL, a table is a collection of data that is stored in a specific format, with rows and columns. Tables are used to store data that can be queried, updated and deleted. For example, an Employees table might have columns for ID, name, email, and salary, and each row in the table would represent a different employee.
A view, on the other hand, is a virtual table that is based on the result of an SQL query. A view does not store data itself, but instead references data from one or more tables and presents it in a specific format. For example, a Top_Salaries view might be created to only show the employees with the highest salaries from the Employees table. The view would not store any data itself, but would instead reference the data from the Employees table and present it in the desired format.
Another important difference between views and tables is that views can be read-only, meaning that you cannot insert, update or delete data from a view. Tables, on the other hand, can be updated and deleted.
In simple terms, a table is where the data is stored, and a view is a virtual table that references the data from one or more tables, allowing you to see the data in a specific format without changing the original data.
10. SQL Challenge — Find the Third-Highest Employee Salary in the Table
Table: Employee
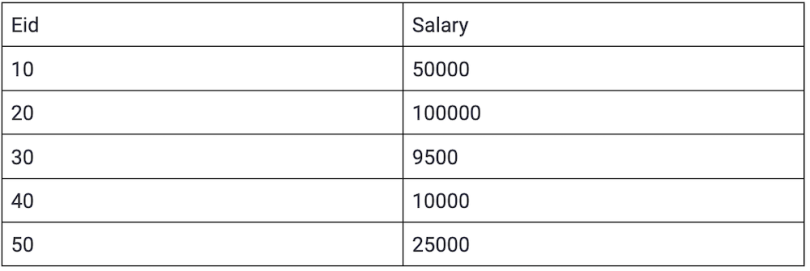
Answer — SQL Query
WITH CTE AS (
SELECT DISTINCT TOP 3 salary
FROM Employee
ORDER BY salary DESC
)
SELECT MIN(salary) AS third_highest_salary
FROM CTEThis query first uses a Common Table Expression (CTE) to select the top three distinct salaries from the Employee table, ordered by salary in descending order. The CTE is then used to select the minimum salary from that list of top three salaries, which is the third highest salary in the table. Here, the third highest salary is $25,000.
Frequently Asked Questions
What is SQL and why is it important?
Structured Query Language (SQL) is a programming language for analyzing and managing data in relational databases. It supports data exploration by simplifying the process of filtering, aggregating and joining data. This makes SQL a must-know skill for data-based professionals like data scientists and data analysts.
What are the most common SQL interview questions?
Common SQL interview questions may involve explaining what cross join is in SQL, demonstrating how to find duplicate records, naming the set operators in SQL and completing other basic tasks.
What are stored procedures and why are they useful?
In SQL, a stored procedure is a pre-saved set of instructions that can be run at any time to accomplish a repetitive or complicated task. This saves programmers from having to write the same commands repeatedly, instead calling a stored procedure whenever the same task comes up.


