

A technical interview is a type of job interview that focuses on evaluating a candidate’s technical expertise, knowledge and problem-solving skills in relation to a technical job position. It’s commonly used in the hiring process for careers like software engineering, information technology and data science.
What Is a Technical Interview?
A technical interview is a type of job interview that aims to evaluate a candidate’s technical expertise, problem solving and communication skills through coding exercises, system design discussions, whiteboard sessions and behavioral interview questions and more. It’s often used to assess candidates in careers like software engineering, IT and data science.
Technical interviews may include coding exercises, algorithmic problem-solving, system design discussions, whiteboarding sessions or hands-on tasks using relevant tools or technologies.
Technical interviews are often conducted in the following formats:
- Coding interviews
- System design interviews
- Behavioral and technical combination interviews
- Take-home assignments
- Technical presentations
7 Types of Technical Interview Questions
Depending on the particular function and industry, technical interview questions might be asked on a wide range of subjects to evaluate technical expertise and problem-solving. The following are a few examples of typical technical interview categories:
1. Coding and Programming
These inquiries evaluate an applicant's proficiency for using programming languages like Python, Java, C++ or JavaScript to write code and resolve issues. They could entail coding puzzles, data structures, algorithmic challenges or writing code to address a particular issue.
2. System Design
These inquiries test a candidate’s competence for large-scale system design and architecture. They frequently concentrate on the trade-offs, scalability, dependability, and performance of complex systems.
3. Data Structures and Algorithms
These types of questions test a candidate’s comprehension of various data structures and algorithms, including arrays, linked lists, stacks, queues, trees, and graphs, as well as sorting, searching, traversals and dynamic programming. Candidates may be required to analyze problems involving time and spatial complexity or to use these ideas in their solutions.
4. Database and SQL
These types of questions test a candidate's understanding of SQL queries, database design principles and database management systems. Candidates may be required to build database structures, write sophisticated queries or optimize queries for performance.
5. System Architecture
These kinds of questions concentrate on a system’s overall structure and its parts. They might go through issues like networking, distributed systems, cloud computing, security and scalability.
6. Testing and Debugging
These kinds of questions evaluate a candidate’s understanding of software testing principles, debugging methods and their aptitude for finding and resolving coding problems.
7. Web Development
The web technologies covered by these questions include HTML, CSS, JavaScript, frameworks like React or Angular, RESTful APIs and browser compatibility. The development or optimization of web applications, resolving front-end issues or debugging of web-related problems may be required of candidates.
20 Technical Interview Questions to Know
Technical interviews often include questions that test the candidate’s understanding of software and how software works. It’s important to be knowledgeable about both the coding language you’ll primarily be working in and the various development methodologies.
Common Technical Interview Questions
- Describe the concept of a binary search algorithm and its time complexity.
- What are the main differences between HTTP and HTTPS?
- Explain the concept of a linked list and its advantage over an array.
- What is the purpose of a code review in testing?
- What are the different programming languages used in web development?
- How does caching work in web development?
- How would you optimize low-performing SQL code?
- What is the role of a load-balancing system of architecture?
- What is horizontal scaling and how does it differ from vertical scaling?
- What is a service-oriented architecture (SOA)?
Here are some practice questions with answers to help you prepare.
1. Describe the Concept of a Binary Search Algorithm and Its Time Complexity.
Binary search is a divide-and-conquer algorithm used to efficiently search a sorted array. It repeatedly divides the search space in half until the target element is found or determined to be absent. The time complexity of binary search is O(log n), as the search space is halved with each comparison.
It significantly lowers the number of comparisons required to find an element by splitting the search space in half during each iteration. Large data sets benefit greatly from its outstanding efficiency due to its time complexity. The elegance of this algorithm rests in its capacity to quickly arrive at the intended outcome, highlighting the significance of algorithmic effectiveness in problem-solving.
The time complexity of binary search is O(log n), where n is the number of elements in the array. This is because the number of comparisons made by binary search is always log2(n). For example, if there are 10 elements in the array, binary search will make seven comparisons. If there are 100 elements in the array, binary search will make seven comparisons. Binary search is a very efficient search algorithm. It’s much faster than linear search, which compares each element in the array to the target value until a match is found. Binary search is also more efficient than other search algorithms, such as the jump search algorithm.
Example
Given an array of integers, find the index of the target element.
array = [1, 4, 6, 7,10, 12], target = 7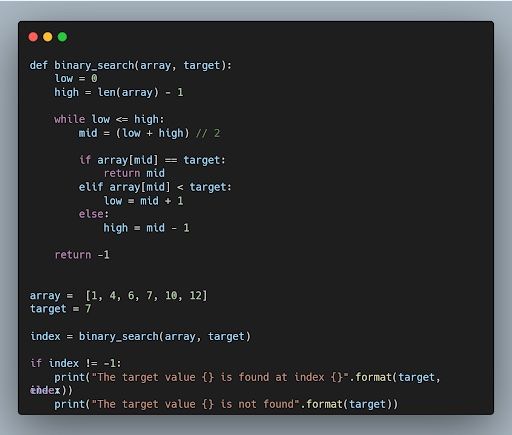
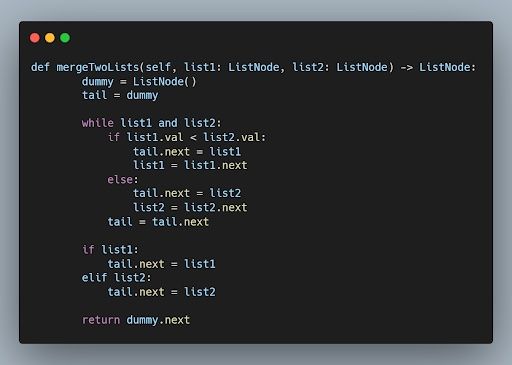
2. Explain the Concept of a Linked List and Its Advantages Over an Array.
A linked list is a data structure consisting of nodes, where each node contains a value and a reference to the next node. Unlike arrays, linked lists have dynamic size and can efficiently insert or delete elements at any position. However, linked lists have slower access times and require extra memory for storing references.
Linked lists are often used to represent data that isn’t sorted or that needs to be inserted or deleted frequently. This is because linked lists can be easily manipulated, without the need to shift other elements in the list.
Linked lists are helpful in situations requiring effective manipulation because elements can be added or removed without requiring significant data transfers. However, it's crucial to remember that linked lists have slower access speeds than arrays because they don't have contiguous memory storage and have more memory requirements for holding node references.
Here are some of the advantages of linked lists over arrays:
- Dynamic size: Linked lists can grow or shrink dynamically, without the need to pre-allocate memory.
- Efficient insertion and deletion: Insertion and deletion of elements in a linked list is very efficient, as it only requires updating the pointers of the affected nodes.
- Memory efficiency: Linked lists can be more memory efficient than arrays for storing data that is not sorted or that needs to be inserted or deleted frequently.
Example
You are given the heads of two sorted linked lists list1 and list2. Merge the two lists into one sorted list. The list should be made by splicing together the nodes of the first two lists. Return the head of the merged linked list.
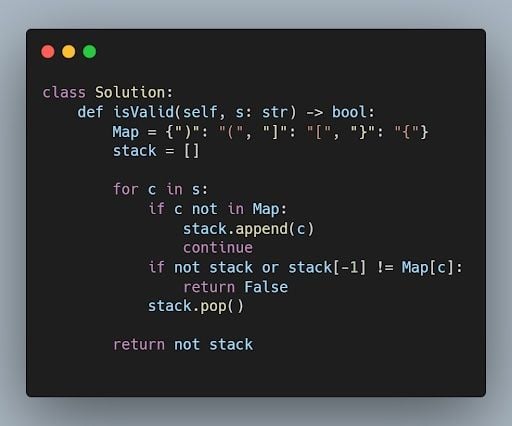
3. Describe the Difference Between a Stack and a Queue Data Structure.
A stack and a queue are both linear data structures, which means that they store data in a sequence. However, they differ in the way that they allow elements to be inserted and deleted. A stack is a last in first out (LIFO) data structure. This means that the last element that is inserted into a stack is the first element that is removed. Stacks are often used to implement recursion, which is a programming technique that allows a function to call itself.
A queue is a first in first out (FIFO) data structure. This means that the first element that is inserted into a queue is the first element that is removed. Queues are often used to implement tasks such as printing jobs or processing requests.
Example
Given a string s containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
Considering a given string of characters, 's', that only contains the letters '(', ')', '', '', '[', and ']', poses the task. It’s your task to validate the input string. In other words, you need to check to see if the string's bracket placement complies with the bracket pairing conventions. To make sure the sequence creates a well-balanced arrangement, it is necessary to verify that each opening bracket is accurately matched and closed by its corresponding equivalent.
4. What Are the Main Differences Between HTTP and HTTPS?
HTTP (hypertext transfer protocol) is an unsecured protocol used for transmitting data over the internet. HTTPS (HTTP secure) is a secure version of HTTP that encrypts data using SSL/TLS protocols, providing confidentiality and integrity. HTTPS is indicated by a padlock symbol in web browsers and is commonly used for secure transactions, such as online banking or e-commerce. However, there are some key differences between the two.
- Security: HTTP is not a secure protocol. This means that data transmitted over HTTP can be intercepted and read by anyone in between the sender and receiver. HTTPS, on the other hand, is a secure protocol. This means that data transmitted over HTTPS is encrypted and cannot be read by anyone in between the sender and receiver.
- Speed: HTTP is generally faster than HTTPS. This is because HTTPS requires additional encryption and authentication steps, which can add some overhead. However, the difference in speed is usually not significant.
- Use: HTTP is used for a wide variety of purposes, including browsing websites, downloading files, and streaming media. HTTPS is typically used for tasks that require a higher level of security, such as online banking, shopping, and email.
Here are some examples of websites that use HTTPS:
- Banking websites: Banks use HTTPS to protect customer data, such as account numbers and passwords.
- Shopping websites: Shopping websites use HTTPS to protect customer credit card information.
- Email services: Email services use HTTPS to protect user messages.
5. Describe the Purpose and Use Cases of Design Patterns in Software Development.
Design patterns are reusable solutions to commonly occurring problems in software design. They provide a structured approach to designing and organizing code, improving code maintainability, reusability and readability. Design patterns, such as Singleton, Factory and Observer, have specific use cases and can simplify complex software architectures. They are used to solve common problems that arise in software design, and they can help to improve the quality, maintainability and reusability of code.
There are many different types of design patterns, but they can generally be divided into three categories:
- Creational patterns deal with the creation of objects.
- Structural patterns deal with the structure of objects and how they interact with each other.
- Behavioral patterns deal with the behavior of objects and how they respond to events.
Some of the most common design patterns include:
- Factory patterns provide a way to create objects without specifying their concrete type.
- Singleton patterns ensure that there is only one instance of a class in an application.
- Adapter patterns allow two incompatible classes to work together.
- Strategy patterns allow objects to change their behavior at runtime.
- Observer patterns allow objects to subscribe to events and be notified when those events occur.
6. How Would You Design a Scalable System for Handling High Traffic and Large Amounts of Data?
Scalable systems can be achieved through techniques like load balancing (distributing traffic across multiple servers), horizontal scaling (adding more servers), caching frequently accessed data, using distributed databases and employing techniques like sharding or partitioning to handle large data volumes. There are many ways to design a scalable system for handling high traffic and large amounts of data. Here are some of the most common approaches:
- Use a distributed architecture. A distributed architecture breaks down the system into smaller components that can be scaled independently. This makes it easier to add more capacity as needed.
- Use a caching layer. A caching layer stores frequently accessed data in memory, which can improve performance by reducing the number of times the database needs to be accessed.
- Use a load balancer. A load balancer distributes traffic across multiple servers, which can improve performance by preventing any single server from becoming overloaded.
- Use a content delivery network (CDN). A CDN stores static content, such as images and JavaScript files, in multiple locations around the world. This can improve performance by delivering content to users from a server that is close to them.
- Use a database that is designed for scalability. There are many different types of databases, and some are better suited for scalability than others. For example, NoSQL databases are designed to store large amounts of data without requiring a lot of processing power.
7. What Is the Difference Between Unit Testing and Integration Testing?
Unit testing focuses on testing individual components or units of code in isolation, while integration testing verifies the interaction between multiple components to ensure they work together correctly. Both testing are performed at different stages of the development process.
Individual pieces of code are tested in unit testing, a sort of software testing, to make sure they function as expected. Individual functions, classes, or modules can all be considered units of code. The developer who created the code being tested usually creates unit tests, and they frequently make use of a unit testing framework. Unit testing is typically performed first, followed by integration testing. This allows developers to identify and fix bugs early in the development process, when they are easier to find and fix.
Integration testing is a type of software testing where individual units of code are combined and tested as a group to ensure that they work together correctly. Integration tests are typically written by a software tester, and they often require the use of a test harness. The main difference between unit testing and integration testing is the level of granularity at which they are performed. Unit testing focuses on individual units of code, while integration testing focuses on how individual units of code interact with each other.
Here are some additional benefits of unit testing and integration testing:
- Increased quality: Unit testing and integration testing can help to identify and fix bugs early in the development process, when they are easier to find and fix. This can help to improve the overall quality of the software.
- Reduced development time: By identifying and fixing bugs early, unit testing and integration testing can help to reduce the amount of time spent debugging later in the development process. This can lead to shorter development cycles and faster time to market.
- Reduced costs: Unit testing and integration testing can help to reduce the costs associated with software development. This is because they can help to prevent bugs from reaching production, which can save money on bug fixing and customer support.
Example
A unit test for a function that adds two numbers together might check to make sure that the function returns the correct value for different input values. An integration test for a system that allows users to add items to a shopping cart might check to make sure that the items are added to the cart correctly when the user clicks the “add to cart” button.
Unit testing verifies particular pieces of code to make sure they work as intended. Testing an addition function, for instance, verifies that it is accurate regardless of the input. The effectiveness of integrated pieces is evaluated through integration testing.
8. What Are Some Common Software Testing Methodologies?
Software testing methodologies are the strategies, processes, or environments used to test software. They encompass everything from unit testing individual modules, integration testing an entire system or specialized forms of testing such as security and performance. There are many different software testing methodologies, some of the most common methodologies include:
Waterfall Model
The waterfall model is a linear, sequential approach to software development. Testing is typically conducted at the end of the development process, after all of the requirements have been defined and the code has been written.
For example, a company that is developing a new enterprise software application might use the waterfall model. The company would first define the requirements for the application, then design the application, write the code, and test the application at the end of the development process.
Agile Model
The agile model is an iterative, incremental approach to software development. Testing is conducted throughout the development process, in short cycles known as sprints. This allows for early detection of defects and changes to be made quickly.
For example, a startup that is developing a new mobile app might use the agile model. The team would start by creating a minimum viable product (MVP) and then release it to users for feedback. The team would then iterate on the app based on the feedback, adding new features and fixing bugs.
Iterative Model
The iterative model is a hybrid approach that combines elements of the waterfall and agile models. Testing is conducted throughout the development process, but it is not as frequent as in the agile model.
For example, a government agency that is developing a new website might use the iterative model. The agency would first develop a prototype of the website, then test it with users to get feedback.
DevOps
The DevOps approach is a culture and methodology that emphasizes the collaboration between development, operations, and security teams. Testing is an integral part of the DevOps process and is conducted throughout the development lifecycle.
For example, a large retailer that is developing a new e-commerce platform might use the DevOps approach. The retailer would have a dedicated team of developers, operations engineers, and security engineers who would work together to develop and test the platform.
9. What Is the Purpose of a Code Review in Testing?
Code reviews are conducted to ensure that the code meets quality standards, follows best practices, and is free from bugs and potential issues. They help identify defects early in the development process. A developer's code is examined by another developer or a team of developers during a code review process. A code review is performed to identify problems in the code, enhance its readability and maintainability and make sure it complies with the project's specifications.
In testing, code reviews can be used to:
- Find bugs that unit tests may have missed. Unit tests are good at finding errors in individual units of code, but they can't always find errors that occur when multiple units of code interact with each other. Code reviews can help to find these types of errors.
- Improve the code’s readability and maintainability. Code that is easy to read and maintain is less likely to have errors. Code reviews can help to improve the readability and maintainability of code by identifying and fixing issues such as poor naming conventions, inconsistent coding styles, and complex logic.
- Ensure that the code meets the project’s requirements. Code reviews can help to ensure that the code meets the project's requirements by identifying and fixing any gaps or inconsistencies between the code and the requirements.
Software quality can be raised with the help of code reviews. Code reviews can assist in preventing problems from entering production and enhancing the overall quality of the software by identifying errors, enhancing readability and maintainability, and making sure the code complies with project objectives.
10. What Are the Different Programming Languages Used for Web Development?
The most popular programming languages for web development are:
11. What Is the Difference Between Front-End and Back-End Development?
Front-end development focuses on building the user interface and user experience of a website or application using technologies like HTML, CSS and JavaScript. Back-end development involves building the server-side logic and database interactions using languages like Python, Ruby or Java.
Front end includes tasks such as designing the layout, creating the graphics, and coding the functionality. Back end includes tasks such as writing code, managing databases and configuring servers.
For example, a front end developer might be responsible for designing the layout of a website, creating the graphics and images for the website, and adding animations and interactivity to the website. A back end developer might be responsible for developing the code that allows users to log in to a website, add items to a shopping cart, or make a purchase.
12. Explain the Concept of AJAX and Its Significance in Web Development.
Asynchronous JavaScript and XML (AJAX) is a technique used to send and retrieve data from a server asynchronously without reloading the entire web page. It allows for dynamic content updates, improved user experience, and reduced server load.
AJAX is a powerful tool that can be used to create more interactive and responsive web applications. It can be used to do things like:
- Update the contents of a web page without reloading it. This can be used to create live updates, such as news feeds or stock tickers.
- Get user input without reloading the page. This can be used to create forms that are more responsive and user-friendly.
- Send data to the server without reloading the page. This can be used to do things like submit forms or start a new session.
Here are some of the benefits of using AJAX in web development:
- Improved user experience
- Reduced bandwidth usage
- Increased flexibility
Overall, AJAX is a powerful technology that may be utilized to build online applications that are more responsive, dynamic, and effective. It's critical for web developers to comprehend how AJAX functions and how to apply it to enhance web apps.
13. How Does Caching Work in Web Development?
Caching involves storing certain web resources (such as images, stylesheets or JavaScript files) in the browser or on intermediate servers to improve page loading speed. It reduces the need to re-download resources, resulting in faster subsequent visits or requests. It’s a technique that stores frequently accessed data in a temporary location so that it can be accessed faster.
In web development, caching is used to store static content, such as images, CSS files, and JavaScript files, so that they do not have to be retrieved from the server each time a user requests a page. This can significantly improve the performance of a website, especially for pages that are frequently visited.
There are two main types of caching in web development:
- Browser caching is when the browser stores a copy of a web page in its local cache. This allows the browser to load the page more quickly the next time the user visits it.
- Server caching is when a web server stores a copy of static content in its memory. This allows the web server to serve the content more quickly to users.
14. Explain the Difference Between SQL and NoSQL Databases.
SQL databases are relational databases, which means that data is stored in tables that have rows and columns. Each row represents a single record and each column represents a single piece of data about that record. SQL databases use structured queries to access data. Structured queries are written in a language called SQL, which stands for structured query language. SQL queries are used to select, insert, update and delete data from tables.
NoSQL databases are non-relational databases, which means that data is not stored in tables. NoSQL databases use a variety of data models, including document, key-value and graph. Document databases store data in documents, which are similar to JSON objects. Key-value databases store data in key-value pairs, where the key is a unique identifier and the value is any type of data. Graph databases store data in a graph, which is a network of nodes and edges.
Here are some examples of SQL and NoSQL databases:
- SQL: MySQL, PostgreSQL, Oracle and Microsoft SQL Server.
- NoSQL: MongoDB, Cassandra, DynamoDB and Redis.
15. How Would You Optimize a Slow-Performing SQL Query?
To optimize a slow SQL query, you can consider various approaches such as indexing appropriate columns, rewriting the query using efficient joins or subqueries, minimizing the number of returned rows and ensuring the proper use of database statistics. Here are some steps you can take to optimize a slow SQL query:
- Analyze the query execution plan: Use the database’s query execution plan analyzer or EXPLAIN statement to understand how the database is executing the query. Look for any full table scans, inefficient joins, or other costly operations.
- Index optimization: Ensure that the relevant columns used in WHERE, JOIN and ORDER BY clauses are indexed appropriately. Indexes can significantly improve query performance by allowing the database to quickly locate the required data.
- Rewrite or refactor the query: Consider rewriting the query to use more efficient join types, subqueries, or conditional logic. Simplify the query by eliminating unnecessary calculations or redundant operations. Breaking complex queries into smaller, manageable parts can also improve performance.
- Limit the result set: If you only need a subset of data, use the LIMIT clause to retrieve a specific number of rows. This can reduce the amount of data that needs to be processed and transmitted, improving query performance.
16. Explain the ACID Properties in the Context of Database Transactions.
ACID stands for atomicity, consistency, isolation and durability. These properties ensure the reliability and integrity of database transactions. Let's delve into each property:
- Atomicity guarantees that a transaction is treated as a single, indivisible unit of work. It follows the "all or nothing" principle, meaning that either all the operations within a transaction are successfully completed, or none of them are.
- Consistency ensures that a transaction brings the database from one valid state to another valid state. It defines a set of rules or constraints that the database must adhere to.
- Isolation ensures that concurrent transactions do not interfere with each other. Each transaction is isolated from other transactions, allowing them to execute as if they were the only transaction running on the database.
- Durability guarantees that once a transaction is committed, its changes are permanent and will survive any subsequent failures, such as power outages or system crashes. The committed data is stored in non-volatile storage (such as a hard disk) to ensure its durability.
Together, the ACID properties ensure data integrity, reliability, and consistency in database transactions. They play a crucial role in maintaining the accuracy and reliability of data in various applications, such as financial systems, e-commerce platforms and enterprise-level applications.
17. What Is the Role of Load Balancing in System Architecture?
Load balancing distributes incoming network traffic across multiple servers or resources to improve performance, scalability, and availability. It ensures that no single server or resource is overloaded, optimizing resource utilization and preventing bottlenecks. In system architecture, load balancing is used to distribute traffic across multiple servers. This can improve performance by reducing the load on each server. It can also improve reliability by ensuring that if one server fails, the others can continue to handle traffic. And it can improve scalability by making it easy to add more servers as demand increases.
There are two main types of load balancing:
- Hardware load balancers: These are physical devices that sit in front of the servers and distribute traffic across them.
- Software load balancers: These are software applications that run on the servers and distribute traffic across them.
18. How Would You Design a System to Handle High Availability and Fault Tolerance?
To achieve high availability and fault tolerance, you can use techniques like redundancy, replication and failover mechanisms. For example, you can replicate critical components and deploy them across multiple servers or data centers. Use load balancers to distribute traffic, and implement automated failover mechanisms to seamlessly switch to backup resources in case of failures.
Designing a system to handle high availability and fault tolerance involves implementing strategies and technologies that minimize downtime and ensure continuous operation even in the face of failures. Here are some key considerations and approaches:
- Redundancy
- Load balancing
- Distributed architecture
- Replication and data synchronization
- Monitoring and automated recovery
- Regular testing and maintenance
- Scalability
By incorporating these strategies and techniques, a system can be designed to handle high availability and fault tolerance, ensuring uninterrupted operation even in the face of failures or adverse conditions.
19. What Is Horizontal Scaling, and How Does it Differ From Vertical Scaling?
Horizontal scaling is a technique for increasing the capacity of a system by adding more nodes. This is done by adding more servers to the system, each of which runs the same application. Horizontal scaling is a good option for systems that need to handle a large number of concurrent users or a large amount of data.
The main difference between horizontal and vertical scaling is that horizontal scaling adds more nodes to the system, while vertical scaling adds more resources to existing nodes. Horizontal scaling is a more scalable solution than vertical scaling, but it can be more complex to implement. Vertical scaling is a less scalable solution than horizontal scaling, but it is easier to implement.
The best approach to scaling a system depends on the specific needs of the system. If the system needs to handle a large number of concurrent users or a large amount of data, then horizontal scaling is the best option. If the system needs to handle a sudden increase in demand, then vertical scaling can be a good option.
Examples of horizontal scaling include:
- Adding more servers to a cluster
- Using a load balancer to distribute traffic across multiple servers
- Using a content delivery network (CDN) to cache static content
Examples of vertical scaling include:
- Upgrading the memory of a server
- Adding more CPU cores to a server
- Adding more storage to a server
20. What Is a Service-Oriented Architecture (SOA)?
Service-oriented architecture (SOA) is an architectural style that structures an application as a collection of loosely coupled services. Services are self-contained modules that perform specific functions and communicate with each other using standardized protocols. SOA promotes reusability, interoperability, and flexibility in system design.
Through established procedures, SOA services communicate and carry out certain duties. By enhancing system adaptability and reuse, SOA enables independent component evolution. It encourages the modular architecture of software, allowing for easy scaling and integration while maintaining resilience and flexibility.
Service-oriented architecture (SOA) is a software design approach that structures an application as a collection of loosely coupled services. These services communicate with each other via well-defined interfaces. SOA is a way of thinking about software architecture that emphasizes the composition of services.
SOA has several benefits, including:
- Reusability: Services can be reused in multiple applications, which can save time and money.
- Scalability: SOA applications can be scaled up or down easily, as needed.
- Interoperability: SOA applications can be easily integrated with other systems.
- Flexibility: SOA applications can be easily changed or updated.
How to Prepare for a Technical Interview
A technical interview involves technical expertise, problem-solving abilities and efficient preparation techniques. Here are some thorough procedures to assist you in getting prepared:
Understand the Job Requirements
Get acquainted with the job's qualifications and description. Review the main programming languages, frameworks, technical abilities and tools that were mentioned. This will help you prepare for the precise areas that are crucial for the position.
Review Core Technical Concepts
Refresh your memory of the core ideas connected to the work position. Data structures, algorithms, object-oriented programming concepts, database ideas, network protocols, operating systems and any other pertinent subjects that may fall under this category. To further your understanding, consult books, coding platforms or online tutorials.
Practice Coding Problems
Practicing coding challenges frequently asked in technical interviews will help you improve your problem-solving abilities. You can find coding challenges on websites like LeetCode, HackerRank and CodeSignal. Start with simpler questions and work your way up to more difficult ones. Understand the time and space complexity of your algorithms and take time to analyze and improve your solutions.
Practice Explaining Your Coding Process and Solutions
Explain your coding strategy in detail, laying out your plans before getting into the code. Walk logically through the answers, focusing on problem-solving strategies, trade-offs and optimization. Demonstrate adaptability in tackling various coding challenges and sensitivity to edge cases. This will help you showcase your technical expertise and ability to work with team members.
Review System Design Concepts
Study numerous system design concepts like scalability, dependability, availability, load balancing, caching and database design if the role requires conversations about system architecture. Learn the common architectures and design patterns for systems.
Research the Company and Industry
Learn more about the company’s offerings, services and technologies. Set up a Google Alert for the company or search the web for the most recent market developments or trends that are pertinent to the position. With this information, you’ll be able to demonstrate your enthusiasm for the business and tailor your responses to meet its technical needs.
Build Projects or Contribute to Open Source
To obtain experience, work on your own projects or contribute to open-source initiatives. This will show that you can use your technological expertise to solve problems in the real world. Keep track of your initiatives and be ready to talk about them in the interview.
Review Your Resume and Past Projects
Be prepared to talk about your resume and provide further details on any listed projects or experiences. Examine your prior efforts, successes and difficulties. Be prepared to describe the choices you made and the lessons you gained while emphasizing the technical components of your projects.
Prepare Questions to Ask
Research and prepare thoughtful questions to ask the interviewer about the company, team dynamics, technical challenges or any other relevant topics. This shows your genuine interest and engagement in the conversation.
Frequently Asked Questions
What are technical questions in an interview?
Technical questions in an interview are questions that evaluate technical knowledge and skills. They often cover topics like coding and programming, data structures and algorithms, databases, web development and more, and can involve hands-on exercises for candidates to demonstrate their technical abilities.
How do I prepare for a technical interview?
To prepare for a technical job interview, it can be helpful to:
- Understand the job requirements
- Review core technical concepts like programming, data structures and algorithms
- Practice coding questions and other mock technical questions
- Practice explaining your coding process
- Research the company and industry practices
What is considered a technical interview?
A technical interview is any job interview that assesses a candidate’s technical knowledge, problem-solving skills and overall communication. Technical interviews are common for software, data science, information technology and similar technical roles.


