

Multithreading and multiprocessing are two ways to achieve multitasking (think distributed computing) in Python. Multitasking is useful for running functions and code concurrently or in parallel, such as breaking down mathematical computation into multiple, smaller parts, or splitting items in a for loop if they are independent of each other.
Multithreading vs. Multiprocessing Defined
- Multithreading: This refers to the ability of a processor to execute multiple threads concurrently, where each thread runs a process.
- Multiprocessing: This refers to the ability of a system to run multiple processors in parallel, where each processor can run one or more threads.
This article will introduce and compare the differences between multithreading and multiprocessing, when to use each method and how to implement them in Python.
Here’s what we’ll cover:
- Multithreading vs. multiprocessing
- Multithreading as a Python function
- Multithreading as a Python class
- Multiprocessing as a Python function
Multithreading vs. Multiprocessing
Multithreading refers to the ability of a processor to execute multiple threads concurrently, where each thread runs a process.
Multiprocessing refers to the ability of a system to run multiple processors in parallel, where each processor can run one or more threads.
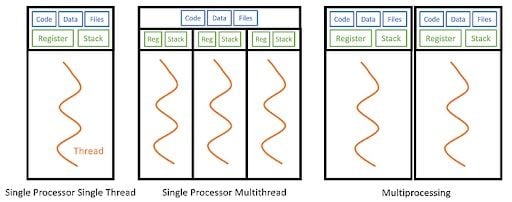
From the diagram above, we can see that in multithreading (middle diagram), multiple threads share the same code, data and files but run on a different register and stack. Multiprocessing (the right diagram) multiplies a single processor, replicating the code, data and files, which incurs more overhead.
Multithreading vs. Multiprocessing Advantages and Disadvantages
Multithreading is useful for IO-bound processes, such as reading files from a network or database since each thread can run the IO-bound process concurrently. Multiprocessing is useful for central processing unit (CPU)-bound processes, such as computationally heavy tasks since it will benefit from having multiple processors; similar to how multicore computers work faster than computers with a single core.
There is a difference between concurrency and parallelism. Parallelism allows multiple tasks to execute at the same time, whereas concurrency allows multiple tasks to execute one at a time in an interleaving manner.
Due to Python global interpreter lock (GIL), only one thread can be executed at a time. Therefore, multithreading only achieves concurrency and not parallelism for IO-bound processes. On the other hand, multiprocessing achieves parallelism.
Using multithreading for CPU-bound processes might slow down performance due to competing resources that ensure only one thread can execute at a time, and overhead is incurred in dealing with multiple threads.
On the other hand, multiprocessing can be used for IO-bound processes. However, the overhead for managing multiple processes is higher than managing multiple threads as illustrated above. You may notice that multiprocessing might lead to higher CPU utilization due to multiple CPU cores being used by the program, which is expected.
Multithreading as a Python Function
Multithreading can be implemented using the Python built-in library threading and is done in the following order:
- Create thread: Each thread is tagged to a Python function with its arguments.
- Start task execution.
- Wait for the thread to complete execution: Useful to ensure completion or ‘checkpoints.’
In the code snippet below, the steps above are implemented, together with a threading lock (Line 22) to handle competing resources which is optional in our case.
import os
import threading
import time
def task_sleep(sleep_duration, task_number, lock):
lock.acquire()
# Perform operation that require a common data/resource
lock.release()
time.sleep(sleep_duration)
print(f"Task {task_number} done (slept for {sleep_duration}s)! "
f"Main thread: {threading.main_thread().name}, "
f"Current thread: {threading.current_thread().name}, "
f"Process ID: {os.getpid()}")
if __name__ == "__main__":
time_start = time.time()
# Create lock (optional)
thread_lock = threading.Lock()
# Create thread
t1 = threading.Thread(target=task_sleep, args=(2, 1, thread_lock))
t2 = threading.Thread(target=task_sleep, args=(2, 2, thread_lock))
# Start task execution
t1.start()
t2.start()
# Wait for thread to complete execution
t1.join()
t2.join()
time_end = time.time()
print(f"Time elapsed: {round(time_end - time_start, 2)}s")
# Task 2 done (slept for 2s)! Main thread: MainThread, Current thread: Thread-67, Process ID: 6068
# Task 1 done (slept for 2s)! Main thread: MainThread, Current thread: Thread-66, Process ID: 6068
# Time elapsed: 2.03sThere are a few notable observations:
- Line 12–15: Processes run on different threads (Thread ID) but with the same processor (Process ID).
- Line 8: If
time.sleep(sleep_duration)were to be implemented between acquiring and releasing the lock instead, the threads will run sequentially and there will not be any time savings.
Multithreading as a Python Class
For users who prefer object-oriented programming, multithreading can be implemented as a Python class that inherits from threading.Thread superclass. One benefit of using classes instead of functions would be the ability to share variables via class objects.
The difference between implementing multithreading as a function rather than class would be in the first step, creating thread, since a thread is now tagged to a class method instead of a function. The subsequent steps to call t1.start() and t1.join() remain the same.
import time
class Sleep(threading.Thread):
def __init__(self, sleep_duration):
self.sleep_duration = sleep_duration
def sleep(self):
time.sleep(self.sleep_duration)
if __name__ == "__main__":
# Create thread
sleep_class = Sleep(2)
t1 = threading.Thread(target=sleep_class.sleep)
Multiprocessing as a Python Function
Multiprocessing can be implemented with Python built-in library multiprocessing using two different methods: Process and pool.
Process method is similar to the multithreading method above, where each process is tagged to a function with its arguments. In the code snippet below, we can see that the time taken is longer for multiprocessing than multithreading since there is more overhead in running multiple processors.
import multiprocessing
import os
import time
def task_sleep(sleep_duration, task_number):
time.sleep(sleep_duration)
print(f"Task {task_number} done (slept for {sleep_duration}s)! "
f"Process ID: {os.getpid()}")
if __name__ == "__main__":
time_start = time.time()
# Create process
p1 = multiprocessing.Process(target=task_sleep, args=(2, 1))
p2 = multiprocessing.Process(target=task_sleep, args=(2, 2))
# Start task execution
p1.start()
p2.start()
# Wait for process to complete execution
p1.join()
p2.join()
time_end = time.time()
print(f"Time elapsed: {round(time_end - time_start, 2)}s")
# Task 1 done (slept for 2s)! Process ID: 11544
# Task 2 done (slept for 2s)! Process ID: 23724
# Time elapsed: 2.81s
Pool method allows users to define the number of workers and distribute all processes to available processors in a first-in-first-out schedule, handling process scheduling automatically. The pool method is used to break a function into multiple small parts using map or starmap (line 19), running the same function with different input arguments. Whereas the process method is used to run different functions.
import multiprocessing
import os
import time
def task_sleep(sleep_duration, task_number):
time.sleep(sleep_duration)
print(f"Task {task_number} done (slept for {sleep_duration}s)! "
f"Process ID: {os.getpid()}")
if __name__ == "__main__":
time_start = time.time()
# Create pool of workers
num_cpu = multiprocessing.cpu_count() - 1
pool = multiprocessing.Pool(processes=num_cpu)
# Map pool of workers to process
pool.starmap(func=task_sleep, iterable=[(2, 1)] * 10)
# Wait until workers complete execution
pool.close()
time_end = time.time()
print(f"Time elapsed: {round(time_end - time_start, 2)}s")
# Task 1 done (slept for 2s)! Process ID: 20464
# Task 1 done (slept for 2s)! Process ID: 22308
# Task 1 done (slept for 2s)! Process ID: 20464
# Task 1 done (slept for 2s)! Process ID: 22308
# Task 1 done (slept for 2s)! Process ID: 20464
# Task 1 done (slept for 2s)! Process ID: 22308
# Task 1 done (slept for 2s)! Process ID: 20464
# Task 1 done (slept for 2s)! Process ID: 22308
# Task 1 done (slept for 2s)! Process ID: 20464
# Task 1 done (slept for 2s)! Process ID: 20464
# Time elapsed: 12.58sThe Python examples are skeleton code snippets that you can replace with your functions and you’re good to go.
Frequently Asked Questions
What is multithreading in Python?
Multithreading in Python is when a Python program has multiple threads (flows of code execution) happening at the same time. It’s used to run several tasks simultaneously and prevent one task from blocking another from executing, which can improve application performance and responsiveness. Multithreading is supported in Python and can be enabled using the built-in threading module.
Which is faster, multiprocessing or multithreading?
Multiprocessing is often faster for large, separate tasks, while multithreading can be faster for small, interconnected tasks.
What is multicore vs multiprocessor vs multithreading?
- Multicore: a combination of multiple computation units (known as cores) within one central processing unit (CPU). A CPU with two or more cores is a multicore processor.
- Multiprocessor: a single computer system with two or more CPUs.
- Multithreading: the ability of a processor to execute multiple threads at the same time and perform tasks simultaneously.
What is the difference between parallel processing and multithreading?
Parallel processing uses two or more processors simultaneously to handle multiple parts of a single (usually large) computing problem. Multithreading describes multiple threads running at the same time within one or more processors.


