

A non-relational database, also called a NoSQL database, stores data without requiring a fixed schema or table-based structure.
In a non-relational database, one piece of stored data might have different fields or attributes from the piece of data next to it in the same database.
Why Use a Non-Relational Database?
Non-relational databases are helpful when there are a lot of unknowns about exactly what data you need to store, or when there is a large volume of data that might hold different attributes but that you still need to compare side-by-side.
If you picture a spreadsheet of ice cream flavors, you know that each row is going to look approximately the same. There will be a column for the ice cream flavor name, a column for the brand, a column for the ingredients and so on. Each row in the spreadsheet will have some value for each of these columns.
A non-relational database doesn’t have to take this shape at all. One ice cream flavor entry might have information about its prize-winning recipe, another might have a list of celebrities who have listed that flavor as their favorite and a third might have tasting notes. In short, there is a lot more flexibility with storing data in a non-relational database.
Types of Non-Relational Databases
As we’ll see below, the term non-relational database actually encompasses four major types of database, which each work differently.
The four types are:
1. Graph Database
Each piece of data is stored as a node and relationships between nodes, called edges, are stored with equal importance. Graph databases are well suited to analyzing a large volume of data points that may seem unrelated and finding the relationships between those points. Some applications include financial institutions needing to detect fraud, healthcare providers who need to better understand disease trajectory and, of course, social networks to manage relationships between users. Neo4j is a popular graph database.
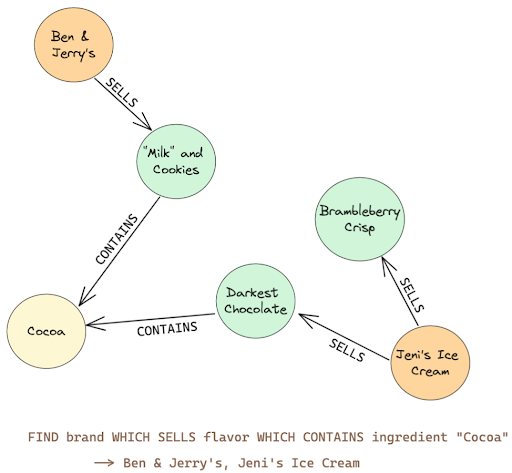
In the example above, we have some ice cream flavors, ingredients and brands mapped onto our graph. The relationships formed in the graph (CONTAINS, SELLS) are how we can traverse the graph, make connections and query our data. Depending on the tool you use, the query language will look a bit different, but you can see what a sample query might look like and what data it could return.
2. Key-Value Database
Each piece of data has a unique key that points to some value. The structure of this database is very similar in concept to a Javascript object or Python dictionary. Key-value databases do not enforce a schema at the database level, allowing flexible and diverse data structures. Since the latency is so low in key-value databases, they are best used for caching, message queues or managing user profiles, to name a few. Redis and Amazon DynamoDB are popular examples of key-value databases.
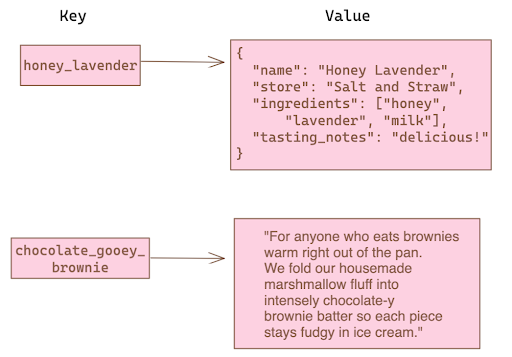
If we were to query our example database above with a key of honey_lavender, we would get back the whole JSON object that is its value. Querying for chocolate_gooey_brownie will return that entire description string.
3. Document-Oriented Database
Document databases are arguably the most multi-purpose databases of these four. Each piece of data is stored as a document, commonly in JSON, where the keys are exposed for querying. The shape of each document could be different. Each document can be of a different structure, but there is also an option to create groupings of documents called collections. These collections can be organized hierarchically, which creates ways to query the data relationally without losing flexibility.
Document databases are used in many different settings such as online shopping carts, gaming and content management. MongoDB and Amazon DynamoDB are popular examples of document-oriented databases. Amazon DynamoDB is a hybrid, so it’s considered both a key-value and document-oriented database.

As you can see in this example, the two documents have different structures and can hold different information. You can add or remove fields from any of the documents as needed.
4. Wide-Column Database
Each piece of data is stored in a table-like structure. Wide column databases are most similar to relational databases. The data can be unstructured though, and doesn’t need to have a rigid schema. Wide-column databases are almost like a hybrid of a key-value database and a relational database. Each piece of data is stored with a unique key that points to a series of column types that can vary from row to row.
This type of database is commonly used when there is a large number of data points with different column types. For example, records from an IoT device will have frequent entries but potentially different data types. Cassandra and HBase are popular options for wide column databases.
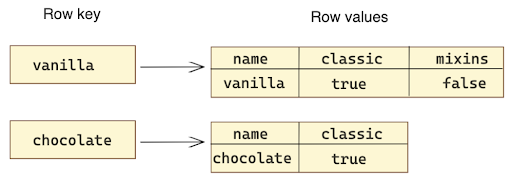
Even though the rows in this example have different values, they can still be in the same database.
Which Non-Relational Database Should I Use?
Just like any other tool you select for an application, it’s important to choose the right database in order to improve latency and stability while reducing complexity and cost. Future-proofing the application is also something to consider, as databases scale differently.
For example, many non-relational databases, especially key-value and wide-column databases, are designed for horizontal scaling and work well in distributed systems in comparison to relational databases. Scaling horizontally means adding more machines, whereas vertical scaling means adding more processing power to the existing machine.
With the advent of cloud infrastructure, which provides the ability to spin up additional servers relatively cheaply and easily, non-relational databases have a distinct advantage.
Relational vs. Non-Relational Databases
To better understand what a non-relational database is, it’s helpful to clarify what a relational database is. Relational databases are a way to store data that rely on each piece of that data being structured in a specific way (typically using tables like our hypothetical ice cream spreadsheet above). Each piece of data is like a row in a spreadsheet wherein we define the column types in advance and normalize the data, which means that each row has either an entry or a null value for each column.
In most relational database designs, distinct data entities are stored in separate, normalized tables to minimize redundancy and ensure data integrity. For instance, a hotel might use one table for guests and another for reservations. Each row in the guests table could include attributes such as guest_id, name and address. The reservations table might include reservation_id, stay_date and guest_id — with guest_id acting as a foreign key that references the guests table.
This relationship between tables, enforced through keys, allows relational databases to join data across different entities while maintaining a consistent schema. SQL (Structured Query Language) enables these joins and relies on the predefined schema to execute queries efficiently.
To retrieve all reservations associated with a particular guest, the database would perform a join between the guests and reservations tables using the guest_id. In contrast, a non-relational database might store all guest-related data — including reservations — within a single nested document, reducing the need for joins and potentially improving query performance in certain scenarios.
Frequently Asked Questions
What is a non-relational database?
A non-relational database, also known as a NoSQL database, is a type of data store that does not require a fixed schema and allows for flexible, varied data structures. Entries can differ in format and attributes, enabling storage of diverse data types without the constraints of table-based organization.
What are the main types of NoSQL databases?
- Graph databases: Store data as nodes and edges to represent relationships.
- Key-value databaseAssociate unique keys with values, often used for caching and user session data.
- Document-oriented databases: Organize data in flexible, semi-structured documents like JSON.
- Wide-column databases: Use table-like structures but allow varying columns across rows for high-volume, distributed data storage.
How do non-relational databases differ from relational databases?
Relational databases use predefined schemas and store data in normalized tables with rigid structures, requiring joins to relate data across entities.
Non-relational databases allow for more flexible data models, storing diverse data types together without joins, which can simplify data retrieval and improve scalability in distributed environments.


