
")
A recurrent neural network (RNN) is a type of neural network used for processing sequential data, and it has the ability to remember its input with an internal memory. RNN algorithms are behind the scenes of some of the amazing achievements seen in deep learning.
What Are Recurrent Neural Networks (RNNs)?
Recurrent neural networks (RNNs) are a class of neural networks that are helpful in modeling sequence data. Derived from feedforward networks, RNNs exhibit similar behavior to how human brains function. Simply put: recurrent neural networks produce predictive results in sequential data that other algorithms can’t.
In this post, we’ll cover the basic concepts of how recurrent neural networks work, what the biggest issues are and how to solve them.
What Are Recurrent Neural Networks (RNNs)?
Recurrent neural networks are a powerful and robust type of neural network, and belong to the most promising algorithms in use because they are the only type of neural network with an internal memory.
RNNs can remember important things about the input they received, which allows them to be very precise in predicting what’s coming next. This is why they’re the preferred algorithm for sequential data like time series, speech, text, financial data, audio, video, weather and much more. Recurrent neural networks can form a much deeper understanding of a sequence and its context compared to other algorithms.
Since RNNs are being used in the software behind Siri and Google Translate, recurrent neural networks show up a lot in everyday life.
How Do Recurrent Neural Networks Work?
To understand RNNs properly, you’ll need a working knowledge of “normal” feed-forward neural networks and sequential data.
Sequential data is basically just ordered data in which related things follow each other. Examples are financial data or a DNA sequence. The most popular type of sequential data is perhaps time series data, which is just a series of data points that are listed in time order.
Recurrent vs. Feed-Forward Neural Networks

RNNs and feed-forward neural networks get their names from the way they channel information.
In a feed-forward neural network, the information only moves in one direction — from the input layer, through the hidden layers, to the output layer. The information moves straight through the network.
Feed-forward neural networks have no memory of the input they receive and are bad at predicting what’s coming next. Because a feed-forward network only considers the current input, it has no notion of order in time. It simply can’t remember anything about what happened in the past except its training.
In an RNN, the information cycles through a loop. When it makes a decision, it considers the current input and also what it has learned from the inputs it received previously.
The two images below illustrate the difference in information flow between an RNN and a feed-forward neural network.

A usual RNN has a short-term memory. In combination with an LSTM they also have a long-term memory (more on that later).
Another good way to illustrate the concept of a recurrent neural network’s memory is to explain it with an example: Imagine you have a normal feed-forward neural network and give it the word “neuron” as an input and it processes the word character by character. By the time it reaches the character “r,” it has already forgotten about “n,” “e” and “u,” which makes it almost impossible for this type of neural network to predict which character would come next.
A recurrent neural network, however, is able to remember those characters because of its internal memory. It produces output, copies that output and loops it back into the network.
Simply put: Recurrent neural networks add the immediate past to the present.
Therefore, an RNN has two inputs: the present and the recent past. This is important because the sequence of data contains crucial information about what is coming next, which is why an RNN can do things other algorithms can’t.
A feed-forward neural network assigns, like all other deep learning algorithms, a weight matrix to its inputs and then produces the output. Note that RNNs apply weights to the current and also to the previous input. Furthermore, a recurrent neural network will also tweak the weights for both gradient descent and backpropagation through time.
Types of Recurrent Neural Networks
The main types of recurrent neural networks include one-to-one, one-to-many, many-to-one and many-to-many architectures.
While feed-forward neural networks map one input to one output, RNNs can map one to many, many-to-many (used for translation) and many-to-one (used for voice classification).
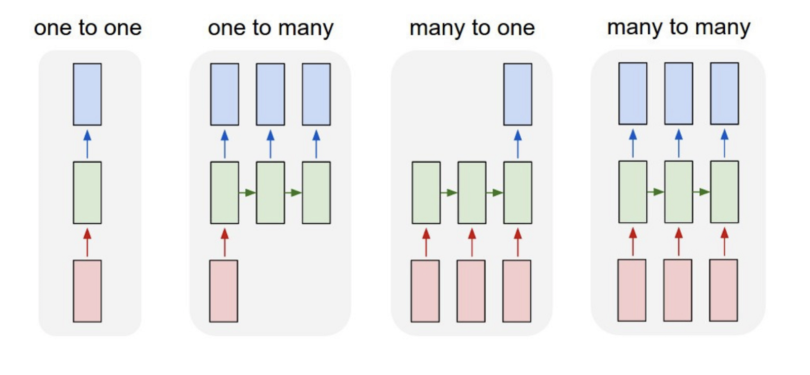
One-to-One
One-to-one RNN models have one input and one output. Also called a vanilla neural network, one-to-one architecture is used in traditional neural networks and for general machine learning tasks like image classification.
One-to-Many
One-to-many RNNs have one input and several outputs. This enables image captioning or music generation capabilities, as it uses a single input (like a keyword) to generate multiple outputs (like a sentence).
Many-to-One
A many-to-one model has several inputs and one output. Tasks like sentiment analysis or text classification often use many-to-one architectures. For example, a sequence of inputs (like a sentence) can be classified into one category (like if the sentence is considered a positive/negative sentiment).
Many-to-Many
Many-to-many models map several inputs to several outputs. Machine translation and name entity recognition are powered by many-to-many RNNs, where multiple words or sentences can be structured into multiple different outputs (like a new language or varied categorizations).
Benefits of Recurrent Neural Networks
The upsides of recurrent neural networks overshadow any challenges. Here are a few reasons RNNs have accelerated machine learning innovation:
- Extensive memory: RNNs can remember previous inputs and outputs, and this ability is enhanced with the help of LSTM networks.
- Greater accuracy: Because RNNs are able to learn from past experiences, they can make accurate predictions.
- Sequential data expertise: RNNs understand the temporal aspect of data, making them ideal for processing sequential data.
- Wide versatility: RNNs can handle sequential data like time series, audio and speech, giving them a broad range of applications.
Challenges of Recurrent Neural Networks
While RNNs have been a difference-maker in the deep learning space, there are some issues to keep in mind:
- Exploding gradients: This is when the algorithm, without much reason, assigns a stupidly high importance to the weights. Fortunately, this problem can be easily solved by truncating or squashing the gradients.
- Vanishing gradients: These occur when the values of a gradient are too small and the model stops learning or takes way too long as a result. Fortunately, it was solved through the concept of LSTM by Sepp Hochreiter and Juergen Schmidhuber.
- Complex training process: Because RNNs process data sequentially, this can result in a tedious training process.
- Difficulty with long sequences: The longer the sequence, the harder RNNs must work to remember past information.
- Inefficient methods: RNNs process data sequentially, which can be a slow and inefficient approach.
Backpropagation Through Time and Recurrent Neural Networks
To understand the concept of backpropagation through time (BPTT), you’ll need to understand the concepts of forward and backpropagation first. We could spend an entire article discussing these concepts, so I will attempt to provide as simple a definition as possible.
What Is Backpropagation?
In machine learning, backpropagation is used for calculating the gradient of an error function with respect to a neural network’s weights. The algorithm works its way backwards through the various layers of gradients to find the partial derivative of the errors with respect to the weights. Backprop then uses these weights to decrease error margins when training.
In neural networks, you basically do forward-propagation to get the output of your model and check if this output is correct or incorrect, to get the error. Backpropagation is nothing but going backwards through your neural network to find the partial derivatives of the error with respect to the weights, which enables you to subtract this value from the weights.
Those derivatives are then used by gradient descent, an algorithm that can iteratively minimize a given function. Then it adjusts the weights up or down, depending on which decreases the error. That is exactly how a neural network learns during the training process.
So, with backpropagation you try to tweak the weights of your model while training.
The image below illustrates the concept of forward propagation and backpropagation in a feed-forward neural network:

BPTT is basically just a fancy buzzword for doing backpropagation on an unrolled recurrent neural network. Unrolling is a visualization and conceptual tool, which helps you understand what’s going on within the network. Most of the time when implementing a recurrent neural network in the common programming frameworks, backpropagation is automatically taken care of, but you need to understand how it works to troubleshoot problems that may arise during the development process.
You can view an RNN as a sequence of neural networks that you train one after another with backpropagation.
The image below illustrates an unrolled RNN. On the left, the RNN is unrolled after the equal sign. Note there is no cycle after the equal sign since the different time steps are visualized and information is passed from one time step to the next. This illustration also shows why an RNN can be seen as a sequence of neural networks.

If you do BPTT, the conceptualization of unrolling is required since the error of a given time step depends on the previous time step.
Within BPTT the error is backpropagated from the last to the first time step, while unrolling all the time steps. This allows calculating the error for each time step, which allows updating the weights. Note that BPTT can be computationally expensive when you have a high number of time steps.
Long Short-Term Memory (LSTM) and Recurrent Neural Networks
Long short-term memory networks (LSTMs) are an extension for RNNs, which basically extends the memory. Therefore, it is well suited to learn from important experiences that have very long time lags in between.
What Is Long Short-Term Memory (LSTM)?
Long short-term memory (LSTM) networks are an extension of RNN that extend the memory. LSTMs are used as the building blocks for the layers of a RNN. LSTMs assign data “weights” which helps RNNs to either let new information in, forget information or give it importance enough to impact the output.
The units of an LSTM are used as building units for the layers of an RNN, often called an LSTM network.
LSTMs enable RNNs to remember inputs over a long period of time. This is because LSTMs contain information in a memory, much like the memory of a computer. The LSTM can read, write and delete information from its memory.
This memory can be seen as a gated cell, with gated meaning the cell decides whether or not to store or delete information (i.e., if it opens the gates or not), based on the importance it assigns to the information. The assigning of importance happens through weights, which are also learned by the algorithm. This simply means that it learns over time what information is important and what is not.
In a long short-term memory cell you have three gates: input, forget and output gate. These gates determine whether or not to let new input in (input gate), delete the information because it isn’t important (forget gate), or let it impact the output at the current time step (output gate). Below is an illustration of an RNN with its three gates:
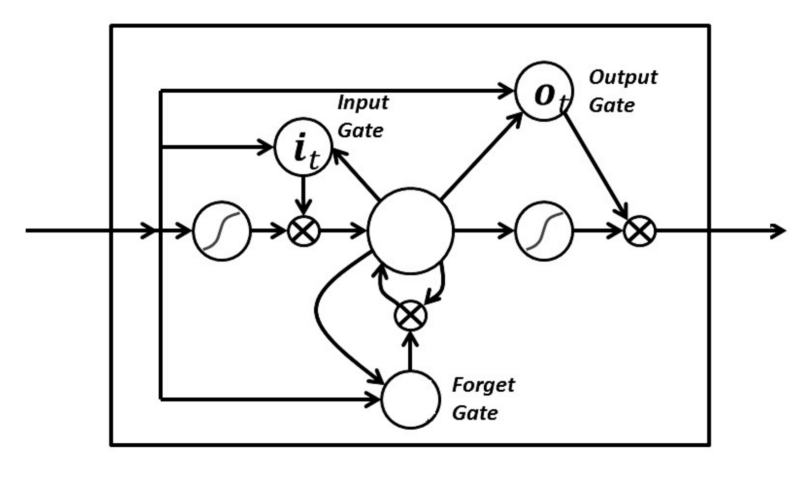
The gates in an LSTM are analog in the form of sigmoids, meaning they range from zero to one. The fact that they are analog enables them to do backpropagation.
The problematic issue of vanishing gradients is solved through LSTM because it keeps the gradients steep enough, which keeps the training relatively short and the accuracy high.
Frequently Asked Questions
What is a recurrent neural network?
A recurrent neural network (RNN) is a type of neural network that has an internal memory, so it can remember details about previous inputs and make accurate predictions. As part of this process, RNNs take previous outputs and enter them as inputs, learning from past experiences. These neural networks are then ideal for handling sequential data like time series.
What is the problem with recurrent neural networks?
Recurrent neural networks may overemphasize the importance of inputs due to the exploding gradient problem, or they may undervalue inputs due to the vanishing gradient problem. Both scenarios impact RNNs’ accuracy and ability to learn.
What is the difference between CNN and RNN?
Convolutional neural networks (CNNs) are feedforward networks, meaning information only flows in one direction and they have no memory of previous inputs. RNNs possess a feedback loop, allowing them to remember previous inputs and learn from past experiences. As a result, RNNs are better equipped than CNNs to process sequential data.


