

Recurrent neural networks (RNNs) are a type of artificial neural network designed to recognize patterns in sequences of data, such as text, speech or time series data. Unlike traditional feedforward networks, RNNs have loops that allow them to retain information from previous inputs, enabling them to remember context over time.
This makes them especially effective for tasks where the order and meaning of earlier data points influence later ones, like language modeling, machine translation and sequence prediction.
How Are Recurrent Neural Networks Used in Language Modeling?
In language modeling, recurrent neural networks (RNNs) are used to predict the next word in a sentence based on the words that came before. They process input text one word (or character) at a time, maintaining a memory of previous inputs through their internal hidden state. This enables the model to capture the sequential nature and context of language — understanding that “I went to the” is likely followed by a noun like “store” or “gym,” depending on the broader context.
In particular, RNNs are a core technology used for natural language processing (NLP), which sits at the intersection of computer science, artificial intelligence and linguistics. The goal of NLP is for computers to process or “understand” natural language in order to perform tasks that are useful, such as sentiment analysis, language translation, and question answering.
The first step to understanding recurrent neural networks and NLP is understanding the concept of language modeling.
Language Modeling in Recurrent Neural Networks
Language modeling is the task of predicting what word comes next. For example, given the sentence “I am writing a …”, the word coming next can be “letter”, “sentence”, “blog post” … More formally, given a sequence of words x(1), x(2), …, x(t), language models compute the probability distribution of the next word x(t+1).
Types of Language Models
N-Gram Model
The most fundamental language model is the n-gram model. An n-gram is a chunk of n consecutive words. For example, given the sentence “I am writing a …”, then here are the respective n-grams:
- Unigrams: “I”, “am”, “writing”, “a”
- Bigrams: “I am”, “am writing”, “writing a”
- Trigrams: “I am writing”, “am writing a”
- 4-grams: “I am writing a”
The basic idea behind n-gram language modeling is to collect statistics about how frequent different n-grams are, and use these to predict the next word. However, n-gram language models have the sparsity problem, in which we do not observe enough data in a corpus to model language accurately (especially as n increases).
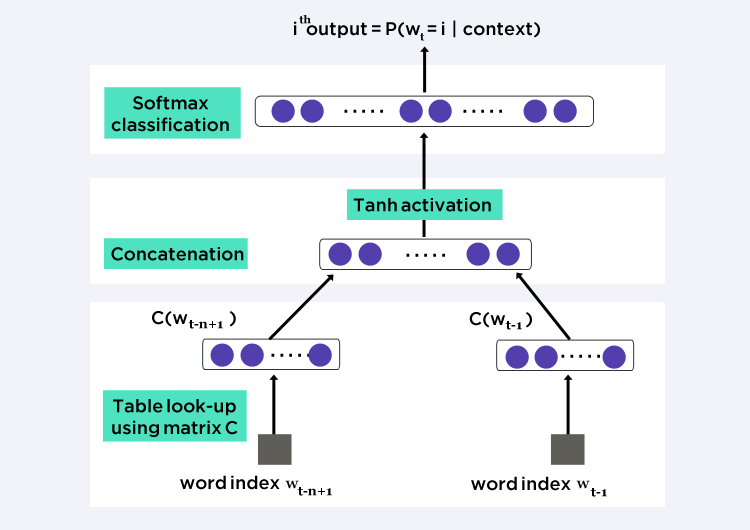
Figure reproduced from Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin, “A neural probabilistic language model,” Journal of machine learning research.
Window-Based Neural Language Model
Instead of the n-gram approach, we can try a window-based neural language model, such as feed-forward neural probabilistic language models and recurrent neural network language models. This approach solves the data sparsity problem by representing words as vectors (word embeddings) and using them as inputs to a neural language model. The parameters are learned as part of the training process. Word embeddings obtained through neural language models exhibit the property whereby semantically close words are likewise close in the induced vector space. Moreover, recurrent neural language models can also capture the contextual information at the sentence-level, corpus-level and subword-level.
How Recurrent Neural Networks Work
The idea behind RNNs is to make use of sequential information. RNNs are called recurrent because they perform the same task for every element of a sequence, with the output dependent on previous computations. Theoretically, RNNs can make use of information in arbitrarily long sequences, but empirically, they are limited to looking back only a few steps. This capability allows RNNs to solve tasks such as unsegmented, connected handwriting recognition or speech recognition.
RNN remembers everything. In other neural networks, all the inputs are independent of each other. But in RNN, all the inputs are related to each other. Let’s say you have to predict the next word in a given sentence, the relationship among all the previous words helps to predict a better output. In other words, RNN remembers all these relationships while training itself.
Recurrent Neural Networks Step-by-Step
RNN remembers what it knows from previous input using a simple loop. This loop takes the information from the previous time stamp and adds it to the input of the current time stamp. The figure below shows the basic RNN structure. At a particular time step t, X(t) is the input to the network and h(t) is the output of the network. A is the RNN cell which contains neural networks just like a feed-forward net.

This loop structure allows the neural network to take the sequence of the input. If you see the unrolled version below, you will understand it better:

First, RNN takes the X(0) from the sequence of input and then outputs h(0)which together with X(1) is the input for the next step.
Next, h(1) from the next step is the input with X(2) for the next step and so on. With this recursive function, RNN keeps remembering the context while training.
If you are a math nerd, many RNNs use the equation below to define the values of their hidden units:

Here, h(t) is the hidden state at timestamp t, ∅ is the activation function (either Tanh or Sigmoid), W is the weight matrix for input to hidden layer at time stamp t, X(t) is the input at time stamp t, U is the weight matrix for hidden layer at time t-1 to hidden layer at time t, and h(t-1) is the hidden state at timestamp t.
RNN learns weights U and W through training using back propagation. These weights decide the importance of the hidden state of the previous timestamp and the importance of the current input. Essentially, they decide how much value from the hidden state and the current input should be used to generate the current input. The activation function ∅ adds non-linearity to RNN, thus simplifying the calculation of gradients for performing back propagation.
Types of Recurrent Neural Networks
Over the years, researchers have developed more sophisticated types of RNNs to deal with this shortcoming of the standard RNN model. Let’s briefly go over the most important ones:
Bidirectional RNNs
Bidirectional RNNs are simply composed of 2 RNNs stacking on top of each other. The output is then composed based on the hidden state of both RNNs. The idea is that the output may not only depend on previous elements in the sequence but also on future elements.
Long Short-Term Memory Networks
Long short-term memory (LSTM) networks are quite popular these days. They inherit the exact architecture from standard RNNs, with the exception of the hidden state. The memory in LSTMs (called cells) take as input the previous state and the current input. Internally, these cells decide what to keep in and what to eliminate from the memory. Then, they combine the previous state, the current memory, and the input. This process efficiently solves the vanishing gradient problem.
Gated Recurrent Unit Networks
Gated recurrent unit networks extend LSTM with a gating network generating signals that act to control how the present input and previous memory work to update the current activation, and thereby the current network state. Gates are themselves weighted and are selectively updated according to an algorithm.
Neural Turing Machines
Neural Turing machines extend the capabilities of standard RNNs by coupling them to external memory resources, which they can interact with through attention processes. The analogy is that of Alan Turing’s enrichment of finite-state machines by an infinite memory tape.
Disadvantages of Recurrent Neural Networks
Vanishing Gradient Problem Reduces RNN Accuracy
RNNs are not perfect. It suffers from a major drawback, known as the vanishing gradient problem, which prevents it from high accuracy.
RNNs Slow Down as Context Increases
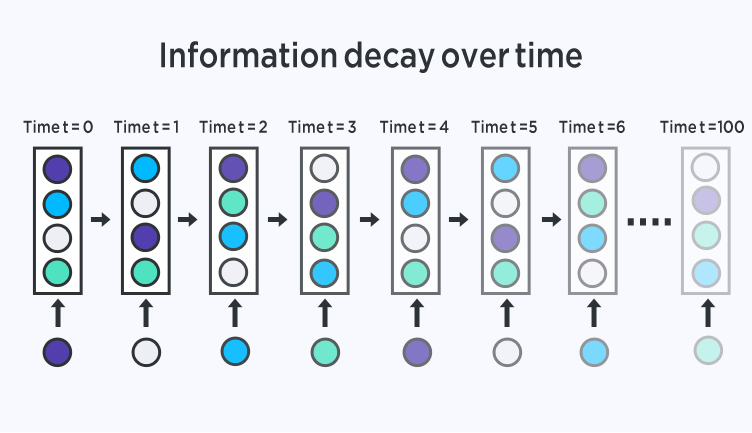
As the context length increases, layers in the unrolled RNN also increase. Consequently, as the network becomes deeper, the gradients flowing back in the back propagation step becomes smaller. As a result, the learning rate becomes really slow and makes it infeasible to expect long-term dependencies of the language.
RNNs Have Difficulty Memorizing Past Words
When context length increases, this also means RNNs experience difficulty in memorizing previous words very far away in the sequence, and are only able to make predictions based on the most recent words.
Real-World Applications of Recurrent Neural Networks
Machine Translation
The beauty of RNNs lies in their diversity of application. When we are dealing with RNNs, they can deal with various types of input and output. Let’s look at Google Translate as an example. It is an instance of neural machine translation, the approach of modeling language translation via one big recurrent neural network. This is similar to language modeling in which the input is a sequence of words in the source language. The output is a sequence of target language.

Standard Neural Machine Translation is an end-to-end neural network where the source sentence is encoded by a RNN called encoder and the target words are predicted using another RNN known as decoder. The RNN Encoder reads a source sentence one symbol at a time, and then summarizes the entire source sentence in its last hidden state. The RNN Decoder uses back-propagation to learn this summary and returns the translated version.
Sentiment Analysis
A simple example of sentiment analysis is to classify X posts into positive and negative sentiments. The input would be a post of different lengths, and the output would be a fixed type and size.

Image Captioning
Together with Convolutional Neural Networks, RNNs have been used in models that can generate descriptions for unlabeled images (think YouTube’s Closed Caption). Given an input of image(s) in need of textual descriptions, the output would be a series or sequence of words. While the input might be of a fixed size, the output can be of varying lengths.
Speech Recognition
An example is that given an input sequence of electronic signals from an EDM, we can predict a sequence of phonetic segments together with their probabilities. Think applications such as SoundHound and Shazam.
Recurrent Neural Networks and Language Modeling: Conclusion
Let’s recap major takeaways from this post:
- Language modeling is a system that predicts the next word. As a benchmark task that helps us measure our progress on understanding language, it is also a sub-component of other natural language processing systems, such as machine translation, text summarization, speech recognition.
- Recurrent neural networks take sequential input of any length, apply the same weights on each step, and can optionally produce output on each step. Overall, RNNs are a great way to build a language model.
- RNNs are useful for multiple applications, like sentence classification, part-of-speech tagging and question answering.
Frequently Asked Questions
Which type of RNN is best suited for language modeling?
Long short-term memory (LSTM) networks are best suited for language modeling. They are designed to overcome the vanishing gradient problem that limits standard RNNs, enabling them to capture long-range dependencies in text and remember context more effectively over extended sequences.
Can RNN be used for NLP?
Yes, recurrent neural networks (RNNs) are widely used in natural language processing (NLP) tasks. They excel at modeling sequential data, making them ideal for applications such as language modeling, machine translation, sentiment analysis, image captioning, and speech recognition.
Is LSTM a language model?
An LSTM (long short-term memory) model itself is a type of recurrent neural network architecture, not a language model on its own. However, LSTMs are frequently used as the core component of neural language models due to their ability to capture context across long sequences of text.
What is the difference between RNN and LSTM?
The main difference between RNNs and LSTMs is that LSTM networks include specialized memory cells and gates that control the flow of information, helping the model decide what to remember and what to forget. This design allows LSTMs to maintain context over longer sequences and effectively solve the vanishing gradient problem that traditional RNNs often face when processing lengthy input.


