

Activation functions in neural networks and deep learning play a significant role in igniting the hidden nodes to produce a more desirable output. The main purpose of the activation function is to introduce the property of nonlinearity into the model.
What Is the ReLU Activation Function?
The rectified linear unit (ReLU) or rectifier activation function introduces the property of nonlinearity to a deep learning model and solves the vanishing gradients issue. It interprets the positive part of its argument. It is one of the most popular activation functions in deep learning.
In artificial neural networks, the activation function of a node defines the output of that node given an input or set of inputs. A standard integrated circuit can be seen as a digital network of activation functions that can be “ON” or “OFF,” depending on the input.
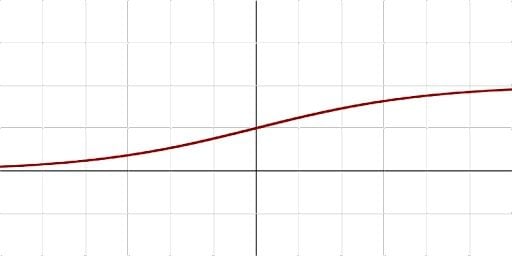
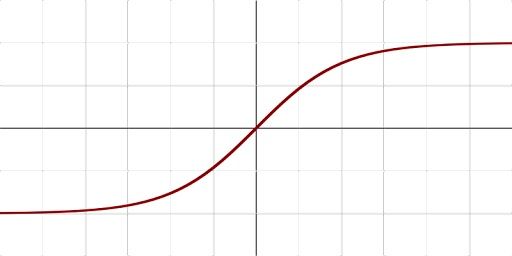
Sigmoid and tanh were monotonous, differentiable and previously more popular activation functions. However, these functions suffer saturation over time, and this leads to problems occurring with vanishing gradients. An alternative and the most popular activation function to overcome this issue is the Rectified Linear Unit (ReLU).
What Is the ReLU Activation Function?
The diagram below with the blue line is the representation of the Rectified Linear Unit (ReLU), whereas the green line is a variant of ReLU called Softplus. The other variants of ReLU include leaky ReLU, exponential linear unit (ELU) and Sigmoid linear unit (SiLU), etc., which are used to improve performances in some tasks.
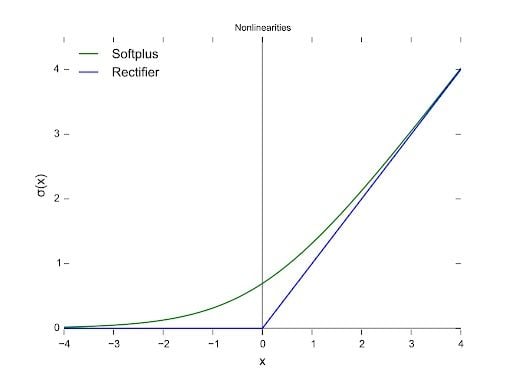
In this article, we’ll only look at the rectified linear unit (ReLU) because it’s still the most used activation function by default for performing a majority of deep learning tasks. Its variants are typically used for specific purposes in which they might have a slight edge over the ReLU.
This activation function was first introduced to a dynamical network by Hahnloser et al. in 2000, with strong biological motivations and mathematical justifications. It was demonstrated for the first time in 2011 as a way to enable better training of deeper networks compared to other widely used activation functions including the logistic sigmoid (which is inspired by probability theory and logistic regression) and the hyperbolic tangent.
The rectifier is, as of 2017, the most popular activation function for deep neural networks. A unit employing the rectifier is also called a rectified linear unit (ReLU).
Why Is ReLU a Good Activation Function?
The main reason ReLU wasn’t used until more recently is because it was not differentiable at the point zero. Researchers tended to use differentiable activation functions like sigmoid and tanh. However, it’s now determined that ReLU is the best activation function for deep learning.
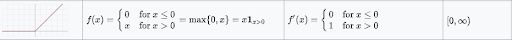
The ReLU activation function is differentiable at all points except at zero. For values greater than zero, we just consider the max of the function. This can be written as:
f(x) = max{0, z}In simple terms, this can also be written as follows:
if input > 0:
return input
else:
return 0All the negative values default to zero, and the maximum for the positive number is taken into consideration.
For the computation of the backpropagation of neural networks, the differentiation for the ReLU is relatively easy. The only assumption we will make is the derivative at the point zero, which will also be considered as zero. This is usually not such a big concern, and it works well for the most part. The derivative of the function is the value of the slope. The slope for negative values is 0.0, and the slope for positive values is 1.0.
The main advantages of the ReLU activation function are:
- Convolutional layers and deep learning: It is the most popular activation function for training convolutional layers and deep learning models.
- Computational simplicity: The rectifier function is trivial to implement, requiring only a max() function.
- Representational sparsity: An important benefit of the rectifier function is that it is capable of outputting a true zero value.
- Linear behavior: A neural network is easier to optimize when its behavior is linear or close to linear.
Disadvantages of the ReLU Activation Function
The main issue with ReLU is that all the negative values become zero immediately, which decreases the ability of the model to fit or train from the data properly.
That means any negative input given to the ReLU activation function turns the value into zero immediately in the graph, which in turn affects the resulting graph by not mapping the negative values appropriately. This can however be easily fixed by using the different variants of the ReLU activation function, like the leaky ReLU and other functions discussed earlier in the article.
This is just a short introduction to the rectified linear unit and its importance in deep learning technology today. It’s more popular than all other activation functions, and for good reason.
Frequently Asked Questions
What does ReLU stand for?
ReLU, short for rectified linear unit, is a non-linear activation function used for deep neural networks in machine learning. It is also known as the rectifier activation function.
What is ReLU used for?
The ReLU activation function is used to introduce nonlinearity in a neural network, helping mitigate the vanishing gradient problem during machine learning model training and enabling neural networks to learn more complex relationships in data.
If a model input is positive, the ReLU function outputs the same value. If a model input is negative, the ReLU function outputs zero.



#/media/File:Rectifier_and_softplus_functions.svg){kind=link}