

Random forest is a flexible, easy-to-use machine learning algorithm that produces, even without hyperparameter tuning, a great result most of the time. It is also one of the most-used algorithms, due to its simplicity and diversity (it can be used for both classification and regression tasks).
What Is Random Forest?
Random forest is a machine learning algorithm that creates an ensemble of multiple decision trees to reach a singular, more accurate prediction or result.
In this post we’ll cover how the random forest algorithm works, how it differs from other algorithms and how to use it.
What Is Random Forest?
Random forest is a supervised learning algorithm. The “forest” it builds is an ensemble of decision trees, usually trained with the bagging method. The general idea of the bagging method is that a combination of learning models increases the overall result.
Put simply: random forest builds multiple decision trees and merges them together to get a more accurate and stable prediction.
How Random Forest Works
One big advantage of random forest is that it can be used for both classification and regression problems, which form the majority of current machine learning systems.
Let’s look at random forest in classification, since classification is sometimes considered the building block of machine learning. Below you can see how a random forest model would look like with two trees:
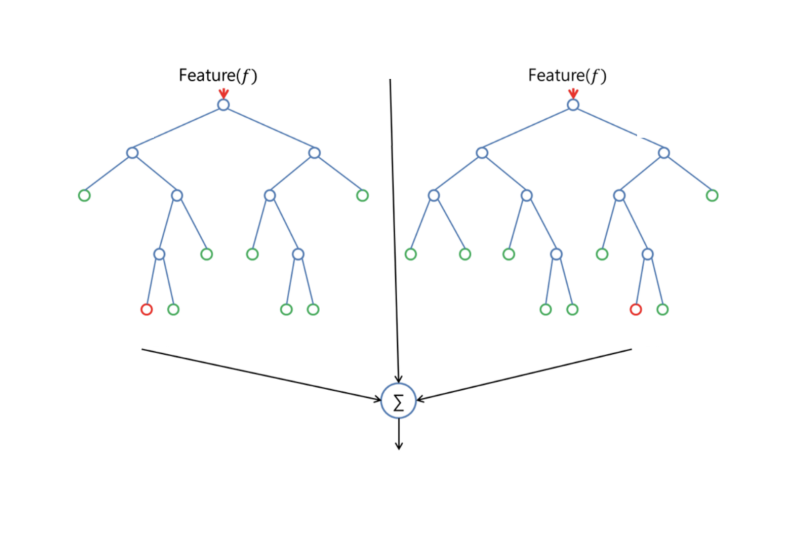
Random Forest in Classification and Regression
Random forest has nearly the same hyperparameters as a decision tree or a bagging classifier. Fortunately, there’s no need to combine a decision tree with a bagging classifier because you can easily use the classifier-class of random forest. With random forest, you can also deal with regression tasks by using the algorithm’s regressor.
Random forest adds additional randomness to the model, while growing the trees. Instead of searching for the most important feature while splitting a node, it searches for the best feature among a random subset of features. This results in a wide diversity that generally results in a better model.
Therefore, in a random forest classifier, only a random subset of the features is taken into consideration by the algorithm for splitting a node. You can even make trees more random by additionally using random thresholds for each feature rather than searching for the best possible thresholds (like a normal decision tree does).
Random Forest Models vs. Decision Trees
While a random forest model is a collection of decision trees, there are some differences.
If you input a training dataset with features and labels into a decision tree, it will formulate some set of rules, which will be used to make the predictions.
For example, to predict whether a person will click on an online advertisement, you might collect the ads the person clicked on in the past and some features that describe their decision. If you put the features and labels into a decision tree, it will generate some rules that help predict whether the advertisement will be clicked or not. In comparison, the random forest algorithm randomly selects observations and features to build several decision trees and then averages the results.
Another difference is “deep” decision trees might suffer from overfitting. Most of the time, random forest prevents this by creating random subsets of the features and building smaller trees using those subsets. Afterwards, it combines the subtrees. It’s important to note this doesn’t work every time and it also makes the computation slower, depending on how many trees the random forest builds.
A Real-Life Example of Random Forest
Andrew wants to decide where to go during his one-year vacation, so he asks the people who know him best for suggestions. The first friend he seeks out asks him about the likes and dislikes of his past travels. Based on the answers, he will give Andrew some advice.
This is a typical decision tree algorithm approach. Andrew’s friend created rules to guide his decision about what he should recommend, by using Andrew’s answers.
Afterward, Andrew starts asking more and more of his friends to advise him and they again ask him different questions they can use to derive some recommendations from. Finally, Andrew chooses the places that his friends recommend the most to him, which is the typical random forest algorithm approach.
Random Forest Feature Importance
Another great quality of the random forest algorithm is that it is very easy to measure the relative importance of each feature on the prediction. Sklearn provides a great tool for this that measures a feature’s importance by looking at how much the tree nodes that use that feature reduce impurity across all trees in the forest. It computes this score automatically for each feature after training and scales the results so the sum of all importance is equal to one.
If you don’t know how a decision tree works or what a leaf or node is, here is a good description from Wikipedia: “In a decision tree, each internal node represents a ‘test’ on an attribute (e.g., whether a coin flip comes up heads or tails), each branch represents the outcome of the test, and each leaf node represents a class label (decision taken after computing all attributes). A node that has no children is a leaf.”
By looking at the feature importance you can decide which features to possibly drop because they don’t contribute enough (or sometimes nothing at all) to the prediction process. This is important because a general rule in machine learning is that the more features you have the more likely your model will suffer from overfitting and vice versa.
Below is a table and visualization showing the importance of 13 features, which I used during a supervised classification project with the famous Titanic dataset on Kaggle. You can find the whole project here.

Random Forest Hyperparameters
The hyperparameters in random forest are either used to increase the predictive power of the model or to make the model faster. Let’s look at the hyperparameters of sklearn’s built-in random forest function.
1. Increasing the Predictive Power
Firstly, there is the n_estimators hyperparameter, which is just the number of trees the algorithm builds before taking the maximum voting or taking the averages of predictions. In general, a higher number of trees increases the performance and makes the predictions more stable, but it also slows down the computation.
Another important hyperparameter is max_features, which is the maximum number of features random forest considers to split a node. Sklearn provides several options, all described in the documentation.
The last important hyperparameter is min_sample_leaf. This determines the minimum number of leafs required to split an internal node.
2. Increasing the Random Forest Model’s Speed
The n_jobs hyperparameter tells the engine how many processors it is allowed to use. If it has a value of one, it can only use one processor. A value of “-1” means that there is no limit.
The random_state hyperparameter makes the model’s output replicable. The model will always produce the same results when it has a definite value of random_state and if it has been given the same hyperparameters and the same training data.
Lastly, there is the oob_score (also called oob sampling), which is a random forest cross-validation method. In this sampling, about one-third of the data is not used to train the model and can be used to evaluate its performance. These samples are called the out-of-bag samples. It’s very similar to the leave-one-out-cross-validation m ethod, but almost no additional computational burden goes along with it.
Advantages of the Random Forest Model
Versatility
One of the biggest advantages of random forest is its versatility. It can be used for both regression and classification tasks, and it’s also easy to view the relative importance it assigns to the input features.
Easy-to-Understand Hyperparameters
Random forest is also a very handy algorithm because the default hyperparameters it uses often produce a good prediction result. Understanding the hyperparameters is pretty straightforward, and there’s also not that many of them.
Prevents Model Overfitting
One of the biggest problems in machine learning is overfitting, but most of the time this won’t happen thanks to the random forest classifier. If there are enough trees in the forest, the classifier won’t overfit the model.
Disadvantages of the Random Forest Model
Higher Accuracy Slows the Model Down
In random forests, more accurate predictions require more trees, which can increase memory usage and slow down the model. While the algorithm is generally fast enough for most real-world applications, the addition of too many trees can make it too slow for real-time predictions.
Additionally, random forest algorithms are generally fast to train, but are quite slow to generate predictions once they’ve been trained, making them less effective in situations where run-time performance is crucial. In such cases, alternative approaches may be preferred.
Can’t Describe Relationships Within Data
Random forest is a predictive modeling tool, not a descriptive one. That means it’s designed to make predictions based on patterns in the data rather than explaining the relationship between variables. If you’re looking to understand how different factors are related, other approaches would be better.
Random Forest Applications
The random forest algorithm is used in a lot of different fields, like banking, the stock market, medicine and e-commerce.
Random Forest Use Cases
- Detects reliable debtors and potential fraudsters in finance
- Verifies medicine components and patient data in healthcare
- Gauges whether customers will like products in e-commerce
In finance, for example, it is used to detect customers more likely to repay their debt on time, or use a bank’s services more frequently. In this domain it is also used to detect fraudsters out to scam the bank. In trading, the algorithm can be used to determine a stock’s future behavior.
In healthcare, it is used to identify the correct combination of components in medicine and to analyze a patient’s medical history to identify diseases.
Random forest is used in e-commerce to determine whether a customer will actually like the product or not.
Summary of the Random Forest Classifier
Random forest is a great algorithm to train early in the model development process, to see how it performs. Its simplicity makes building a “bad” random forest a tough proposition.
The algorithm is also a great choice for anyone who needs to develop a model quickly. On top of that, it provides a pretty good indicator of the importance it assigns to your features.
Random forests are also very hard to beat performance-wise. Of course, you can probably always find a model that can perform better — like a neural network, for example — but these usually take more time to develop, though they can handle a lot of different feature types, like binary, categorical and numerical.
Overall, random forest is a (mostly) fast, simple and flexible tool, but not without some limitations.
Frequently Asked Questions
What is a random forest in simple terms?
Random forest is an algorithm that generates a ‘forest’ of decision trees. It then takes these many decision trees and combines them to avoid overfitting and produce more accurate predictions.
What is the difference between decision trees and random forest?
The difference between decision trees and random forest is that decision trees consider all possible outcomes in the search for the best outcome based on the data provided; random forest generates random predictions from multiple decision trees and averages these out. As a result, decision trees may fall victim to overfitting, but random forest doesn’t.
How does random forest work?
Random forest produces multiple decision trees, randomly choosing features to make decisions when splitting nodes to create each tree. It then takes these randomized observations from each tree and averages them out to build a final model.
Is random forest supervised or unsupervised?
Random forest is a supervised machine learning algorithm. This means it uses labeled training data to help the system recognize patterns and predict outcomes accurately.


