

A decision tree is a supervised machine learning algorithm used for classification and regression tasks. Decision trees are tree data structures that continuously split data from a given set of observations according to a certain parameter. The two types of decision trees are classification trees (which predict categorical/qualitative outcomes) and regression trees (which predict continuous/quantitative outcomes).
What Is a Classification Tree?
A classification tree (or decision tree classifier) is a type of decision tree used to predict categorical outcomes from a set of observations. Classification trees are created by recursively partitioning data based on measure of Gini impurity or information gain, with leaf nodes representing class labels and final possible outcomes.
Decision Tree Classification Basics
Decision trees start at the root node, branch off into internal nodes and end at leaf nodes. In a decision tree:
- Root node represents the topmost input feature in which the entire data set will be split; the entire data set being used for classification
- Branches represent the outcome of a test
- Internal/decision nodes represent tests where decisions are made based on input features
- Leaf nodes represent class labels and final possible outcomes for the prediction
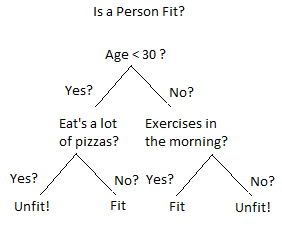
To understand the concept of decision trees, consider the above example. Let’s say you want to predict whether a person is fit or unfit, given their age, eating habits and physical activity. The decision nodes are the questions like “What’s the age?,” “Does the person exercise?,” “Does the person eat a lot of pizza?”
The leaf nodes or leaves (nodes with no children) represent outcomes like fit or unfit.
Types of Decision Trees
There are two types of decision trees: classification trees and regression trees. Classification trees predict categorical or qualitative outcomes from a set of observations, while regression trees predict continuous or quantitative outcomes from a set of observations.
1. Classification Trees (Yes/No Types)
What we’ve seen above is an example of a classification tree where the outcome was a variable like “fit” or “unfit.” Here the decision variable is categorical/discrete.
We build this kind of tree through a process known as binary recursive partitioning. This iterative process means we split the data into partitions and then split it up further on each of the branches.
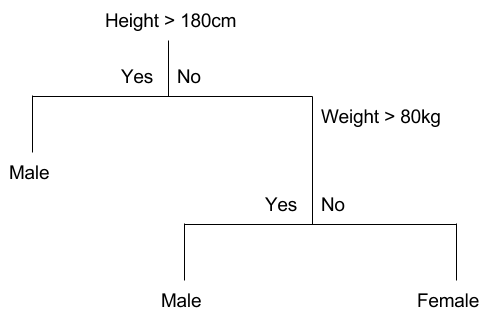
2. Regression Trees (Continuous Data Types)
Regression trees are decision trees where the target variable contains continuous values or real numbers (e.g., the price of a house, or a patient’s length of stay in a hospital).
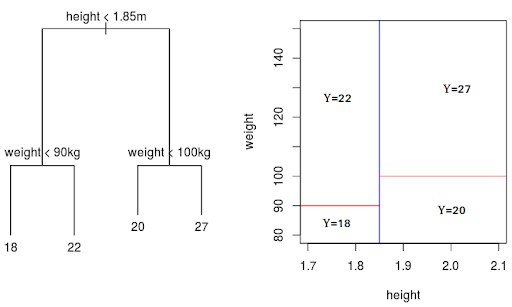
What Is the Divide and Conquer Strategy in Decision Trees?
We build decision trees using a heuristic called recursive partitioning. This approach is also commonly known as divide and conquer because it splits the data into subsets, which then split repeatedly into even smaller subsets, and so on and so forth. The process stops when the algorithm determines the data within the subsets are sufficiently homogenous or have met another stopping criterion.
Basic Divide and Conquer Algorithm
- Select a test for the root node. Create a branch for each possible outcome of the test.
- Split instances into subsets, one for each branch extending from the node.
- Repeat recursively for each branch, using only instances that reach the branch.
- Stop recursion for a branch if all its instances have the same class.
How to Create a Decision Tree
Using recursive partitioning, we break down a set of training examples into smaller and smaller subsets; this process incrementally develops an associated decision tree. At the end of the learning process, the algorithm returns a decision tree covering the training set.
The key is to use decision trees to partition the data space into clustered (or dense) regions and empty (or sparse) regions.
In decision tree classification, we classify a new example by submitting it to a series of tests that determine the example’s class label. These tests are organized in a hierarchical structure called a decision tree. Decision trees follow the divide and conquer algorithm.
Classification trees determine how nodes are split to create the tree based on Gini impurity or information gain (IG) metrics. With Gini impurity, each node in the tree is split based on the input feature that lowers the measure of Gini impurity the most, and stops splitting once Gini impurity values can no longer be improved. With information gain, a node is split based on the input feature that results in the largest information gain (i.e. reduction in uncertainty towards the final decision).
Creating a Classification Tree Using Information Gain
When creating a classification tree using information gain, we start at the tree root and split the node data on the most informative input feature. In other words, the feature with the maximum information gain will be the root node of the classification tree.
In an iterative process, we can then repeat this splitting procedure at each child node until the leaves are pure. This means that the data samples at each leaf node all belong to the same class.
In practice, we may set a limit on the tree’s depth to prevent overfitting. We compromise on purity here somewhat as the final leaves may still have some impurity.


Advantages of Classification With Decision Trees
- Inexpensive to construct
- Extremely fast at classifying unknown records
- Easy to interpret for small-sized trees
- Their accuracy is comparable to other classification techniques for many simple data sets
- Exclude unimportant features
Disadvantages of Classification With Decision Trees
- Easy to overfit
- Decision boundaries are restricted to being parallel to attribute axes
- Decision tree models are often biased toward splits on features having a large number of levels
- Small changes in the training data can result in large changes to decision logic
- Large trees can be difficult to interpret and the decisions they make may seem counter-intuitive
Real-World Applications of Decision Trees
- Biomedical Engineering: Decision trees identify features used in implantable devices.
- Financial analysis: They measure customer satisfaction with a product or service.
- Astronomy: Decision trees are to classify galaxies.
- System Control: Decision trees have found their application in modern air conditioning and temperature controllers.
- Manufacturing and production: Decision trees aid in quality control, semiconductor manufacturing, and more.
- Healthcare: They help doctors diagnose patients in cardiology, psychiatry, and more.
- Physics: Decision trees are used for particle analysis.
Frequently Asked Questions
What is a classification tree?
A classification tree is a type of decision tree used to predict categorical or qualitative outcomes from a set of observations. In a classification tree, the root node represents the first input feature and the entire population of data to be used for classification, each internal node represents decisions made depending on input features and leaf nodes represent the class labels or final possible outcomes for the prediction. Nodes in a classification tree tend to be split based on Gini impurity or information gain metrics.
What is the difference between a regression tree and a classification tree?
Regression trees are used to predict continuous or quantitative outcomes from data, while classification trees predict categorical or qualitative outcomes. Both regression trees and classification trees are types of decision trees.
What prediction does a classification tree give?
A classification tree predicts categorical or qualitative outcomes based on given data, and determines what class a target variable most likely belongs to.


