

In this tutorial we’ll try to understand one of the most important algorithms in machine learning: random forest algorithm. We’ll look at what makes random forest so special and implement it on a real-world data set using Python. You can find the code along with the data set here.
But first things first, let’s get some background.
What Is Random Forest Regression?
Random forest regression is a supervised learning algorithm and bagging technique that uses an ensemble learning method for regression in machine learning. The trees in random forests run in parallel, meaning there is no interaction between these trees while building the trees.
What Is Random Forest Regression?
Random forest regression is a supervised learning algorithm that uses an ensemble learning method for regression.
Random forest is a bagging technique and not a boosting technique. The trees in random forests run in parallel, meaning there is no interaction between these trees while building the trees.

How Does Random Forest Regression Work?
Random forest operates by constructing a multitude of decision trees at training time and outputting the clas s that’s the mode of the classes (classification) or mean prediction (regression) of the individual trees.
A random forest is a meta-estimator (i.e. it combines the result of multiple predictions), which aggregates many decision trees with some helpful modifications:
- The number of features that can be split at each node is limited to some percentage of the total (which is known as the hyper-parameter). This limitation ensures that the ensemble model does not rely too heavily on any individual feature and makes fair use of all potentially predictive features.
- Each tree draws a random sample from the original data set when generating its splits, adding a further element of randomness that prevents overfitting.
The above modifications help prevent the trees from being too highly correlated.
Random Forest Example
For example, see the nine decision tree classifiers below:
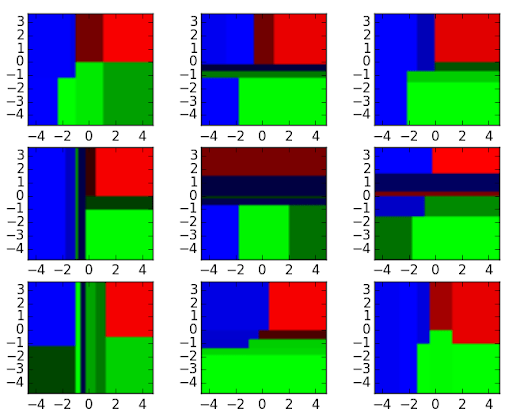
We can aggregate these decision tree classifiers into a random forest ensemble which combines their input. Think of the horizontal and vertical axes of the above decision tree outputs as features x1 and x2. At certain values of each feature, the decision tree outputs a classification of blue, green, red, etc.
The above results are aggregated, through model votes or averaging, into a single ensemble model that ends up outperforming any individual decision tree’s output.
You can see the aggregated result for the nine decision tree classifiers below:

Random Forest Regression Definitions
Ensemble Learning
An ensemble method is a technique that combines the predictions from multiple machine learning algorithms together to make more accurate predictions than any individual model. A model comprised of many models is called an ensemble model.

What Are The Different Kinds of Ensemble Learning?
- Boosting
- Bootstrap Aggregation (Bagging)
Boosting
Boosting refers to a group of algorithms that utilize weighted averages to make weak learners into stronger learners. Boosting is all about teamwork. Each model that runs, dictates the features on which the next model will focus.
As the name suggests, boosting means one is learning from another, which in turn boosts the learning.
Bootstrapping
Bootstrap refers to random sampling with replacement. Bootstrap allows us to better understand the bias and the variance within the data set. Bootstrapping involves a random sampling of a small subset of data from the data set.
Bagging is a general procedure that can be used to reduce the variance for those algorithms that have high variance, typically decision trees. Bagging makes each model run independently and then aggregates the outputs at the end without preference to any model.
Advantages of Random Forest Regression
- Random forest is one of the most accurate learning algorithms available. For many data sets, it produces a highly accurate classifier.
- It runs efficiently on large databases.
- It can handle thousands of input variables without variable deletion.
- It gives estimates of what variables are important in the classification.
- It generates an internal unbiased estimate of the generalization error as the forest building progresses.
- It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing.
Problems with Decision Trees
Decision trees are sensitive to the specific data on which they are trained. If the training da ta is changed, the resulting decision tree can be quite different and, in turn, the predictions can be distinct.
Decision trees are also computationally expensive to train, carry a big risk of overfitting and tend to find local optima because they can’t go back after they have made a split.
To address these weaknesses, we turn to random forest, which illustrates the power of combining many decision trees into one model.
Disadvantages of Random Forest Regression
- Random forests have been observed to overfit for some data sets with noisy classification/regression tasks.
- For data including categorical variables with different numbers of levels, random forests are biased in favor of those attributes with more levels. Therefore, the variable importance scores from random forest are not reliable for this type of data.
How to Implement Random Forest Regression in Python
- Importing Python Libraries and Loading our Data Set into a Data Frame

- Splitting our Data Set Into Training Set and Test Set - This step is only for illustrative purposes. There’s no need to split this particular data set since we only have 10 values in it.

- Creating a Random Forest Regression Model and Fitting it to the Training Data - For this model I’ve chosen 10 trees
(n_estimator=10).
- Visualizing the Random Forest Regression Results

There you go. We’ve learned about the various kinds of ensemble learning algorithms and how these algorithms help make random forest work. Now we have an intuitive understanding of the features and advantages of using random forest over other machine learning algorithms.


