

With all of the packages and tools available, building a machine learning model isn’t difficult. Building a good machine learning model, however, is another story. A huge step that is often ignored is feature importance, or selecting the appropriate features for your model. Skipping this step can lead to biased data that messes up a model’s final results.
Feature Importance Definition
Feature importance involves calculating the score for all input features in a machine learning model to establish the importance of each feature in the decision-making process. The higher the score for a feature, the larger the effect it has on the model to predict a certain variable.
In this article, we’ll cover what feature importance is, why it’s so useful, how you can implement it with Python and how you can visualize it in Gradio.
What Is Feature Importance?
Feature importance refers to techniques that calculate a score for all the input features for a given model. The scores represent the “importance” of each feature. A higher score means that the specific feature will have a larger effect on the model that is being used to predict a certain variable.
Suppose you have to buy a new house near your workplace. While purchasing a house, you might think of different factors. The most important factor in your decision-making might be the location of the property, so you’ll likely only look for houses that are near your workplace. Feature importance works in a similar way, ranking features based on the effect that they have on the model’s prediction.
Why Is Feature Importance Useful?
Feature importance determines how much specific variables influence the predictions of a machine learning model, which is extremely useful for the following reasons:
1. Data Comprehension
Building a model is one thing, but understanding the data that goes into the model is another. Like a correlation matrix, feature importance allows you to understand the relationship between the features and the target variable. It also helps you understand what features are irrelevant to the model.
2. Model Improvement
When training your model, you can use the scores calculated from feature importance to reduce the dimensionality of the model. The higher scores are usually kept and the lower scores are deleted as they are not important for the model. This simplifies the model and speeds up the model’s working, ultimately improving the performance of the model.
3. Model Interpretability
Feature importance is also useful for interpreting and communicating your model to other stakeholders. By calculating scores for each feature, you can determine which features contribute the most to the predictive power of your model.
How to Calculate Feature Importance
There are different ways to calculate feature importance, but this article will focus on two methods: Gini importance and permutation feature importance.
Gini Importance
In Scikit-Learn, Gini importance is used to calculate the node impurity. Feature importance is basically a reduction in the impurity of a node weighted by the number of samples reaching that node from the total number of samples. This is known as node probability. Let us suppose we have a tree with two child nodes, the equation:
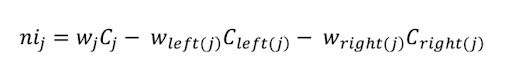
Here, we have:
- nij: Node j importance.
- wj: Weighted number of samples reaching node j.
- Cj: The impurity value of node j.
- left(j): Child node on left of node j.
- right(j): Child node on right of node j.
This equation gives us the importance of a node j, which is used to calculate the feature importance for every decision tree. A single feature can be used in the different branches of the tree. We can calculate the feature importance as follows:
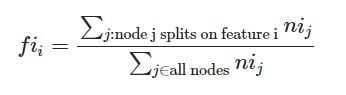
The features are normalized against the sum of all feature values present in the tree, and after dividing it with the total number of trees in our random forest, we get the overall feature importance. With this, you can get a better grasp of the feature importance in random forests.
Permutation Feature Importance
The idea behind permutation feature importance is simple. Under this method, the feature importance is calculated by noticing the increase or decrease in error when we permute the values of a feature. If permuting the values causes a huge change in the error, it means the feature is important for our model.
The best thing about this method is that it can be applied to every machine learning model. Its approach is model agnostic, which gives you a lot of freedom. There are no complex mathematical formulas behind it. The permutation feature importance is based on an algorithm that works as follows:
- Calculate the mean squared error with the original values.
- Shuffle the values for the features and make predictions.
- Calculate the mean squared error with the shuffled values.
- Compare the differences between them.
- Sort the differences in descending order to get features with most to least importance.
How to Calculate Feature Importance in Python
In this section, we’ll create a random forest model using the Boston housing data set.
1. Import the Required Libraries and Data Set
First, we’ll import all the required libraries and our data set.
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.inspection import permutation_importance
from matplotlib import pyplot as plt
2. Train Test Split
The next step is to load the data set and split it into a test and training set.
boston = load_boston()
X = pd.DataFrame(boston.data, columns=boston.feature_names)
y = boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
3. Create a Random Forest Model
Next, we’ll create the random forest model.
rf = RandomForestRegressor(n_estimators=150)
rf.fit(X_train, y_train)
4. Apply Feature Importance and Plot Results
Once the model is created, we can conduct feature importance and plot it on a graph to interpret the results.
sort = rf.feature_importances_.argsort()
plt.barh(boston.feature_names[sort], rf.feature_importances_[sort])
plt.xlabel("Feature Importance")
RM is the average number of rooms per dwelling, and it’s the most important feature in predicting the target variable.
How to Calculate Feature Importance with Gradio
Gradio is a package that helps create simple and interactive interfaces for machine learning models. With Gradio, you can evaluate and test your model in real time. It can also calculate the feature importance with a single parameter, and we can interact with the features to see how it affects feature importance.
Here’s an example:
1. Import the Required Libraries and Data Set
First, we’ll import all the required libraries and our data set. In this example, I will be using the iris data set from the Seaborn library.
# Importing libraries
import numpy as np
import pandas as pd
import seaborn as sns
# Importing data
iris=sns.load_dataset("iris")
2. Fit the Data Set to the Model
Then, we’ll split the data set and fit it on the model.
from sklearn.model_selection import train_test_split
X=iris.drop("species",axis=1)
y=iris["species"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
from sklearn.svm import SVC
model = SVC(probability=True)
model.fit(X_train,y_train)
3. Create a Prediction Function
We’ll also create a prediction function that will be used in our Gradio interface.
def predict_flower(sepal_length, sepal_width, petal_length, petal_width):
df = pd.DataFrame.from_dict({'Sepal Length':[sepal_length],
'Sepal Width': [sepal_width],
'Petal Length': [petal_length],
'Petal Width': [petal_width]})
predict = model.predict_proba(df)[0]
return {model.classes_[i]: predict[i] for i in range(3)}
4. Install Gradio and Create an Interface
Finally, we’ll install Gradio with pip and create our interface.
# Installing and importing Gradio
!pip install gradio
import gradio as gr
sepal_length = gr.inputs.Slider(minimum=0, maximum=10, default=5, label="sepal_length")
sepal_width = gr.inputs.Slider(minimum=0, maximum=10, default=5, label="sepal_width")
petal_length = gr.inputs.Slider(minimum=0, maximum=10, default=5, label="petal_length")
petal_width = gr.inputs.Slider(minimum=0, maximum=10, default=5, label="petal_width")
gr.Interface(predict_flower, [sepal_length, sepal_width, petal_length, petal_width], "label", live=True, interpretation="default").launch(debug=True)
The gr.Interface takes an interpretation parameter which gives us the importance of the features for the mode. Below is the result:
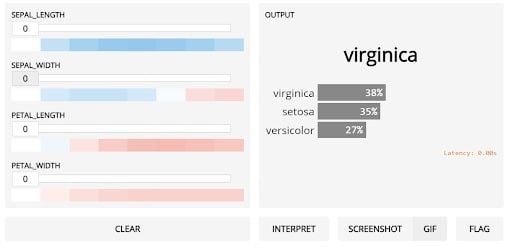

The legend tells you how changing that feature will affect the output. Increasing petal length and petal width will increase the confidence in the virginica class. Petal length is more “important” only in the sense that increasing petal length gets you “redder,” more confident, faster.
If you made it this far, congrats. Hopefully, you have a thorough understanding of what feature importance is, why it’s useful and how you can use it.
Frequently Asked Questions
What is feature importance simply put?
Feature importance is a way to measure the degree to which different variables (features) in your dataset impact a machine learning model’s predictions.
What is the best way to calculate feature importance?
A popular method for calculating feature importance is permutation feature importance. Under this method, the features in a model are shuffled to determine if there are any major changes in a model’s performance. Smaller degrees of change signal a feature is less important while larger degrees of change establish a feature as more important.
What are the advantages of feature importance?
Feature importance clarifies the relationship between different features and the variable you’re trying to predict. This makes it easier to identify and remove less important features, improving a machine learning model’s speed and overall performance.


