

In this article, I will explain and provide the Python implementations of Markov chain. It will not be a deep dive into the mathematics behind Markov chains, but will focus on how it works and how to implement it with Python.
Markov Chain Definition
What Is a Markov Chain?
A Markov chain is a stochastic model created by Andrey Markov that outlines the probability associated with a sequence of events occurring based on the state in the previous event. It’s a very common and easy-to-understand model that’s frequently used in industries that deal with sequential data such as finance. Even Google’s page rank algorithm, which determines what links to show first in its search engine, is a type of Markov chain. Through mathematics, this model uses our observations to predict future events.
The main goal of the Markov process is to identify the probability of transitioning from one state to another. One of the primary appeals to Markov is that the future state of a stochastic variable is only dependent on its present state. An informal definition of a stochastic variable is described as a variable whose values depend on the outcomes of random occurrences.
Main Characteristics of a Markov Chain
The main characteristic of a Markov process is the property of memorylessness. The term “memorylessness” in mathematics is a property of probability distributions and generally refers to scenarios in which the time associated with a certain event occurring does not depend on how much time has already elapsed. In other words, the model has “forgotten” which state the system is in. As a result, the predictions associated with a Markov process are conditional only on its current state and are independent of past and future states.
This memorylessness attribute is both a blessing and a curse. Imagine you wish to predict words or sentences based on previously entered text — similar to how Google does for Gmail. The benefit of using the Markov process is that the newly generated predictions would not be dependent on something you wrote paragraphs ago. However, you won’t be able to predict text that’s based on context from a previous state of the model. This is a common problem in natural language processing (NLP) and an issue many models face.
How to Create a Markov Chain Model
A Markov chain model is dependent on two key pieces of information — the transition matrix and initial state vector.
Transition Matrix
Denoted as “P,” This NxN matrix represents the probability distribution of the state’s transitions. The sum of probabilities in each row of the matrix will be one, implying that this is a stochastic matrix.
Note that a directed, connected graph can be converted into a transition matrix. Each element in the matrix would represent a probability weight associated with an edge connecting two nodes.
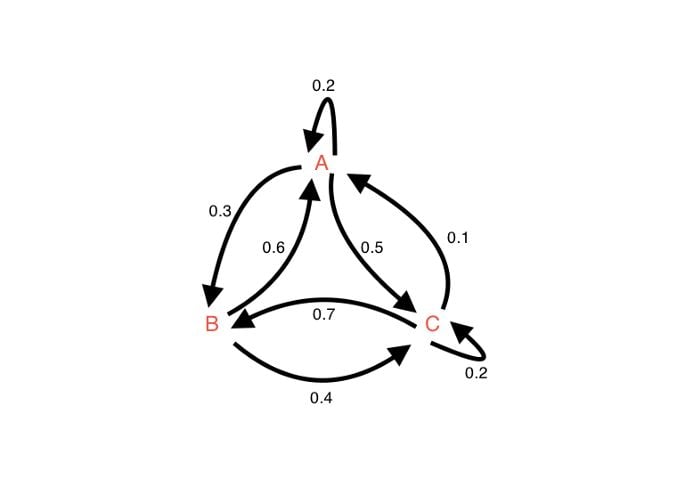
+-----+-----+-----+
| A | B | C | - Represents the network above
+-----+-----+-----+-----+ - NxN transition matrix
| A | .2 | .3 | .5 | - element hold probabilities
+-----+-----+-----+-----+ - row sum of probabilities = 1
| B | .6 | 0 | .4 | - .3 is the probability for state A
+-----+-----+-----+-----+ to go to state B
| C | .1 | .7 | .2 | - .7 is the probability for state C
+-----+-----+-----+-----+ to go to state BInitial State Vector
Denoted as “S,” this Nx1 vector represents the probability distribution of starting at each of the N possible states. Every element in the vector represents the probability of beginning at that state.
Given these two dependencies, you can take the product of P x I to determine the initial state of the Markov chain. In order to predict the probability of future states occurring, you can raise your transition matrix P to the “M’th” power.
What Is an Example of a Markov Chain?
A common application of Markov chains in data science is text prediction. It’s an area of NLP that is commonly used in the tech industry by companies like Google, LinkedIn and Instagram. When you’re writing emails, Google predicts and suggests words or phrases to autocomplete your email. And when you receive messages on Instagram or LinkedIn, those apps suggest potential replies.
Suppose you had a large amount of text associated with a topic. You can imagine each sentence as a sequence of words in that corpus of text. Each word would then be its own state, and you would associate the probability of moving from one state to another based on the available words to which you are connected. This would allow you to transition from one state to another based on the probabilities associated with the transition matrix. This can be visualized below.
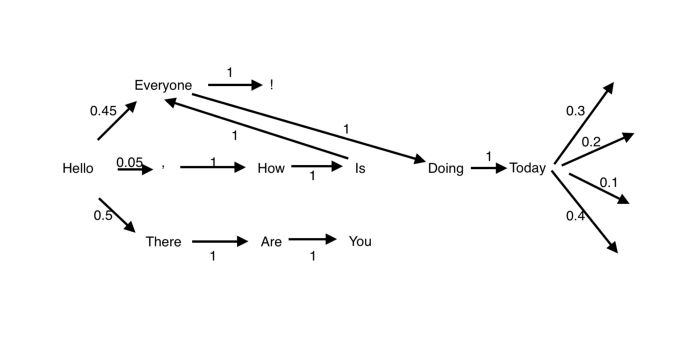
For visualization purposes, the network above has a small amount of words in its corpus. When dealing with large amounts of text like the Harry Potter series, this network would become very large and complicated. If you look at the beginning word “Hello,” there are three other potential words and symbols following it: Everyone , There with their associated probabilities. The simplest way to calculate these probabilities is by frequency of the word in the corpus.
Hello --> ['Everyone', ',', 'Everyone', 'Everyone', 'There', 'There', 'There', There', There', ...]If there were 20 words in the list above, where each word is stated after the word “Hello” then the probability of each word occurring would follow the following formula:
P(word) = Frequency of Word / Total Number of Words in List
P(Everyone) = 9 / 20
P(,) = 1 / 20
P(There) = 10 / 20Your initial state vector would be associated with the probability of all the words you could’ve started your sentence with. In the example above, since “Hello” is the only word to start with, the initial state vector would be a Nx1 vector with 100 percent of the probability associated with the word “Hello.” You can now predict the future states through this Markov model. I’ll show you how to implement this in Python next.
Create Your Own Markov Chain
I predicted sentences Shakespeare would write in a play. Upon downloading the dependencies, Shakespeare data and updating the file_path to where you saved it, this code can run on your computer, too. If you want to use a different text file to train the model on and predict, then just update the file_path to your specified location.
from collections import defaultdict
import string
import random
class Markov():
def __init__(self, file_path):
self.file_path = file_path
self.text = self.remove_punctuations(self.get_text())
self.model = self.model()
def get_text(self):
'''
This function will read the input file and return the text associated to the file line by line in a list
'''
text = []
for line in open(self.file_path):
text.append(line)
return ' '.join(text)
def remove_punctuations(self, text):
'''
Given a string of text this function will return the same input text without any punctuations
'''
return text.translate(str.maketrans('','', string.punctuation))
def model(self):
'''
This function will take a block of text as the input and map each word in the text to a key where the
values associated to that key are the words which proceed it
args:
text (String) : The string of text you wish to train your markov model around
example:
text = 'hello my name is V hello my name is G hello my current name is F world today is a good day'
markov_model(text)
>> {'F': ['world'],
'G': ['hello'],
'V': ['hello'],
'a': ['good'],
'current': ['name'],
'good': ['day'],
'hello': ['my', 'my', 'my'],
'is': ['V', 'G', 'F', 'a'],
'my': ['name', 'name', 'current'],
'name': ['is', 'is', 'is'],
'today': ['is'],
'world': ['today']}
'''
# split the input text into individual words seperated by spaces
words = self.text.split(' ')
markov_dict = defaultdict(list)
# create list of all word pairs
for current_word, next_word in zip(words[0:-1], words[1:]):
markov_dict[current_word].append(next_word)
markov_dict = dict(markov_dict)
print('Successfully Trained')
return markov_dict
def predict_words(chain, first_word, number_of_words=5):
'''
Given the input result from the markov_model function and the nunmber of words, this function will allow you to predict the next word
in the sequence
args:
chain (Dictionary) : The result of the markov_model function
first_word (String) : The word you want to start your prediction from, note this word must be available in chain
number_of_words (Integer) : The number of words you want to predict
example:
chain = markov_model(text)
generate_sentence(chain, first_word = 'do', number_of_words = 3)
>> Do not fail.
'''
if first_word in list(chain.keys()):
word1 = str(first_word)
predictions = word1.capitalize()
# Generate the second word from the value list. Set the new word as the first word. Repeat.
for i in range(number_of_words-1):
word2 = random.choice(chain[word1])
word1 = word2
predictions += ' ' + word2
# End it with a period
predictions += '.'
return predictions
else:
return "Word not in corpus"
if __name__ == '__main__':
m = Markov(file_path='Shakespeare.txt')
chain = m.model
print(predict_words(chain, first_word = 'do', number_of_words = 10))In summation, a Markov chain is a stochastic model that outlines a probability associated with a sequence of events occurring based on the state in the previous event. The two key components to creating a Markov chain are the transition matrix and the initial state vector. It can be used for many tasks like text generation, which I’ve shown how to do based on the Python code above.
Frequently Asked Questions
How are Markov chains used in real life?
An everyday example of a Markov chain is Google’s text prediction in Gmail, which uses Markov processes to finish sentences by anticipating the next word or phrase. Markov chains can also be used to predict user behavior on social media, stock market trends and DNA sequences.
Why is Markov chain used?
A Markov chain is used in situations where the next possible outcome is random. This means the next state of a system only depends on its current state, making the Markov chain an ideal method for predicting the next state.
Is a Markov chain AI?
While a Markov chain in itself isn’t artificial intelligence, it plays a key role in powering AI technologies. Through Markov processes, AI tools can predict various outcomes, culminating in generative AI tools that can produce images, text and audio.


