

Here’s how we can use deep neural networks to predict human behavior through predictive behavior modeling. In particular, we’ll discuss what predictive behavior modeling actually means, use cases for this technique and how to use deep neural networks to model future behavior.
What Is Predictive Behavior Modeling?
What Is Predictive Behavior Modeling?
Simply speaking, predictive behavior modeling is an area of predictive analytics that tries to predict (or model) a group’s future behavior (e.g. customers, voters, etc.). You can formulate the prediction of future behavior as a classification problem. For example, if there are four possible actions a customer can take, the predictive behavior model, which is a deep neural network, assigns each of these actions a probability score. The probability score represents the likelihood that the given person or group will take the action associated with this probability score.
Predictive behavior modeling is the science of building algorithmic models and training them based on historical data to predict future behavior. For example, we can look at customers’ past purchases and buying habits in order to predict how, what and when they will purchase products in the future. In other words, we are attempting to predict the likelihood a customer will take a particular action.
In the field of predictive analysis, predictive behavior modeling goes beyond passive behavioral analysis. Rather than trying to make well-founded assumptions based on analyzing historical data (work normally done by humans), predictive behavior modeling allows us to make decisions based on predictions generated by algorithmic models (i.e., deep neural networks).
Before we dive deeper into the technical implementation of predictive behavior modeling, let’s first look at some concrete use cases.
Use Cases for Predictive Behavior Modeling
1. Predicting Customer Churn
Customer churn occurs when customers or subscribers stop doing business with a company or service. Given a large amount of customer data like demographic information, customer purchase history, service usage, billing data, etc., a neural network trained on this data can perform a classification of customers into various categories of risk in terms of future churn.
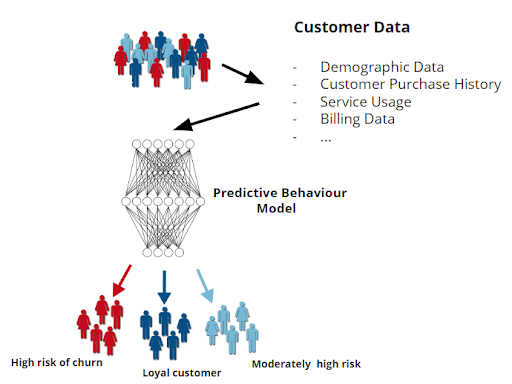
More precisely, we can train the model on past customer data. The data would contain information on customers who stopped doing business with the company as well as information for customers who are still doing business. The network trained on this data would be able to classify a brand-new customer into one of the categories of risk for future churn (high, moderately high or loyal).
Also known as customer attrition, customer churn is a critical metric because it’s much less expensive to retain existing customers than it is to acquire new customers. Customer retention is generally less expensive, as you’ve already earned the trust and loyalty of existing customers. As you can imagine, it’s critical for businesses to predict potential churn in order to prevent it, but also to forecast realistic future revenue and allocate resources appropriately..
After segmenting and identifying the customers most likely to leave, the company can take the necessary steps (such as marketing or incentives) to convince them to stay with the company.
In addition, customers will feel more valued because the company is communicating with them, which results in greater satisfaction, brand loyalty and word-of-mouth referrals.
2. Predicting the Outcome of a Marketing Campaign
Algorithmic models can be trained on the results of previous marketing campaigns or strategies that targeted a particular group of people. Some marketing campaigns are more appealing to one group of people than another. Intuitively, some people with certain characteristics who are exposed to a particular marketing campaign under certain conditions are more willing to buy or upgrade to a new product or service than others.
Trained algorithmic models can predict campaign response so we’re not always reacting to customer response, but anticipating it.
Deep learning engineers can implement a neural network model to predict which kind of marketing campaigns or actions are more likely to be successful for a particular group of people.

Simply put, this is a classification task. Given the data of a particular customer, we can implement a neural network that performs a classification of this customer segment into various groups. Each group is associated with the likelihood that the customer in this group will buy a product or service advertised in the marketing campaign (low likelihood to buy or upgrade, high, moderately high, etc.).
Predictive behavior modeling enables marketers to know in advance which marketing actions are more likely to be successful. With this knowledge, companies can spend less time and money on people who have no interest in the product or service. Instead, those resources can go toward attracting customers who, according to the neural network’s predictions, are most interested in the product or service advertised in the campaign, which will result in a better return on investment (ROI).
Predictive Behavior Modeling with Neural Networks
Predictive behavior modeling is a process that requires a lot of data. Let’s say we’re a company that wants to implement a deep learning model to predict whether a particular customer will take certain actions in the future. This will require not only the data of that particular customer (or customer demographic), but also the data of thousands of other customers.
Take a look at the following sample of the famous bank marketing data set:

This data set contains information of approximately 45,000 customers of a Portuguese bank and is related to the bank’s direct marketing campaigns (phone calls). Often, more than one contact to the same client was required, in order to assess whether the product (bank term deposit) would be subscribed (“yes”) or not (“no”).
Each data instance contains the information of a particular customer as well as the outcome of the marketing campaign.
We can divide the data into two categories the features (blue) and the labels (red).
In this case, the features are customers’ age, education level and job, alongside any other characteristics that can describe the customers. In deep learning, features are usually abbreviated as x.
The label, on the other hand, (abbreviated as y) represents the action the customer described by features
(x) taken in the past. In this case, “no” means the customer is still with the bank and “yes” means that this customer has stopped doing business with the bank.
As you might have already guessed, we can’t use the features from this data set directly to train the neural network model. This is because the features contain numeric data and string data types, which we cannot feed into a model directly.
Instead, we must preprocess the data set in various ways. Regarding the label, we’ll represent it as a vector. Each entry in this vector will represent a possible action or behavior of a customer. An entry value of 1 means that the customer took the action associated with this entry in the past; otherwise we’ll use an entry value of 0.
In the case of bank marketing from the previous example, that binary number will tell us whether the person with the given features accepted the offer advertised in the marketing campaign or not.
The same principle will apply to the question of whether or not a customer has purchased a certain product, has made a product upgrade or has performed any other action in the past.
Given the features and the labels of thousands of customers, deep learning engineers can implement a neural network model that can learn from past customer data to predict the probability that a customer (described by features) will take a particular action in the future.

For this, we must show the neural network the customer features x over and over again. For each input x, the network will compute an output y that we’ll compare with the ground truth label.
Based on the error between the label and the prediction, we’ll improve the neural network with the gradient descent algorithm.
Predictive Behavior Modeling Is a Classification Task
Since we want to predict probabilities, customer behavior modeling is a classification task.
In this case, we are classifying a customer by features into several groups of possible actions. We consider the action group with the highest predicted probability scores to be the expected behavior of that customer in the future.
During classification, we want to implement a neural network that performs a mapping from input features x to an output y. The output y is the output of the neural network model, which is a probability score between 0 and 1.
This value gives us the probability that the customer described by the features x will take the action associated with the probability y. Having customer data, all we need to do is to build a neural network model that’s able to solve the given training objective.
Since we want to predict a probability between 0 and 1, which we compare with the actual label in the data set, our training objective here is to minimize the cross-entropy loss function.

Now let’s discuss how many output neurons the neural network should have for this type of task.
For example, suppose you perform a classification task for only two possible behaviors or actions. Let’s call these actions A and action B.

In this case, it may be sufficient to use only one output neuron if the label y_hat is a binary number. For example, action A could be represented by a value of 0 and action B by the value of 1 or vice versa.
However, a common and more appropriate approach would be to use the same number of output neurons as there are actions. For two possible actions, you would have two output neurons. In this case, the output of the network would be a vector with two entries, while the label vector would be a binary vector in which each entry is either 1 or 0.
The entries in the output vector y would contain probabilities in the range between 0 and 1. Since during classification we have mutually exclusive classes, use the softmax function as the function in the last layer This will make the output of the neural network sum up to one, which is a convenient way to represent a probability distribution.


