

Hidden Markov models are probabilistic frameworks where the observed data are modeled as a series of outputs generated by one of several (hidden) internal states. Both Markov and hidden Markov models are engineered to handle data that can be represented as a sequence of observations over time.
Hidden Markov Model Definition
A hidden Markov model is a probabilistic framework used to predict the results of an event based on a series of observations with one or several hidden internal states.
While a Markov model or Markov chain concerns stochastic (random) process states that are visible to the observer, a hidden Markov model pertains to stochastic processes where states can be hidden or not directly visible to the observer.
What Is a Hidden Markov Model (HMM)?
A hidden Markov model (HMM) is utilized when we can’t observe the states of a stochastic process themselves, but only the result of some probability function (observation) of the states. HMM is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved (hidden) states.
Hidden Markov models can be used to identify underlying patterns or structures in sequential data. This makes it applicable for research and tasks in machine learning (including natural language processing and speech recognition), bioinformatics and gene analysis as well as time-series forecasting.
For example, in speech recognition tasks, a hidden Markov model algorithm may be implemented to measure the probability of a certain word or lack of words occurring in a given audio recording. In this case, the occurrence of specific words or silence in the recording can represent states, and volume of speech throughout the recording can represent observations. By knowing observations (volume), this information can be used by the algorithm to determine the likelihood of hidden states — or words and lack of words in this example — and predict the most probable word being spoken.
Mathematically, here is how Markov models and hidden Markov models differ:
- Markov model: Series of (hidden) states
z={z_1,z_2………….}drawn from state alphabetS ={s_1,s_2,…….𝑠_|𝑆|}wherez_ibelongs toS. - Hidden Markov model: Series of observed output
x = {x_1,x_2,………}drawn from an output alphabetV= {𝑣1, 𝑣2, . . , 𝑣_|𝑣|}wherex_ibelongs toV.
Hidden Markov Model Assumptions
A hidden Markov model is built on several assumptions, including:
1. Output Independence Assumption
Output observation is conditionally independent of all other hidden states and all other observations when given the current hidden state.
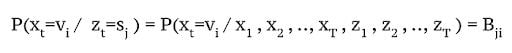
2. Emission Probability Matrix
Probability of hidden state generating output v_i given that state at the corresponding time was s_j.
Markov Model Assumptions
Markov models are developed based on two assumptions:
1. Limited Horizon Assumption
Probability of being in a state at a time t depend only on the state at the time (t-1).
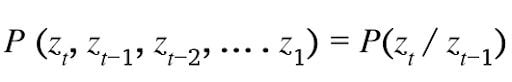
That means state at time t represents enough summary of the past to reasonably predict the future. This assumption is an order-1 Markov process. An order-k Markov process assumes conditional independence of state z_t from the states that are k + 1-time steps before it.
2. Stationary Process Assumption
Conditional (probability) distribution over the next state, given the current state, doesn’t change over time.
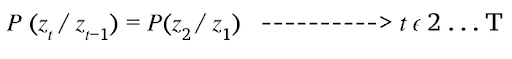
That means states keep on changing over time but the underlying process is stationary.
Notation Convention
- There is an initial state and an initial observation
z_0 = s_0 s_0: Initial probability distribution over states at time 0.- Initial state probability:
(π) - At
t=1, probability of seeing first real statez_1isp(z_1/z_0). - Since
z0 = s0:
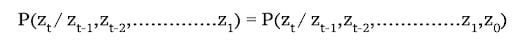
State Transition Matrix
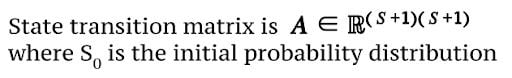
𝐀𝐢,𝐣: probability of transitioning from state i to state j at any time t.
The following chart is a state transition matrix of four states, including the initial state:
2 Questions Answered in a Markov Model
- What is the probability of particular sequences of state z?
- How do we estimate the parameter of state transition matrix A to maximize the likelihood of the observed sequence?
Probability of Particular Sequences in a Markov Model

Consider the state transition matrix above. Let’s determine the probability of sequence:
{z1 = s_hot , z2 = s_cold , z3 = s_rain , z4 = s_rain , z5 = s_cold}
P(z) = P(s_hot|s_0 ) P(s_cold|s_hot) P(s_rain|s_cold) P(s_rain|s_rain) P(s_cold|s_rain)
= 0.33 x 0.1 x 0.2 x 0.7 x 0.2 = 0.000924
Hidden Markov Model Example
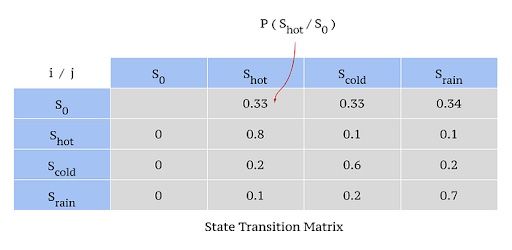
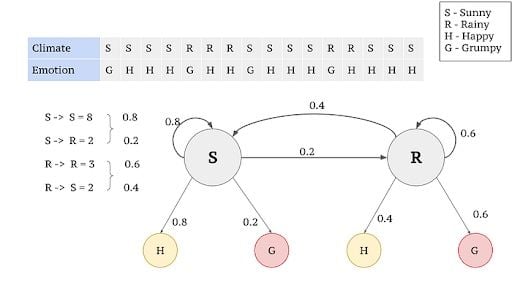
Consider the example given below, which elaborates how a person feels in different climates.
- Set of states:
(S) = {Happy, Grumpy} - Set of hidden states:
(Q) = {Sunny , Rainy} - State series over time:
= z∈ S_T - Observed states for four day:
= {z1=Happy, z2= Grumpy, z3=Grumpy, z4=Happy}
The feeling that you understand from a person emoting is called the observations, since you observe them. The weather that influences the feeling of a person is called the hidden state, since you can’t observe it.
Emission Probabilities
In the above example, feelings (“Happy” or “Grumpy”) can be only observed. A person can observe that a person has an 80 percent chance to be “happy” given that the climate at the particular point of observation is sunny. Similarly there’s a 60 percent chance of a person being “grumpy” given that the climate is rainy. The 80 percent and 60 percent are emission probabilities since they deal with observations.
Transition Probabilities
When we consider the climates (hidden states) that influence the observations, there are correlations between consecutive days being sunny or alternate days being rainy. There is an 80 percent chance for the Sunny climate to be in successive days, whereas there’s a 60 percent chance for it to be rainy on consecutive days. The probabilities that explain the transition to/from hidden states are transition probabilities.
How Does a Hidden Markov Model Work?
A hidden Markov model answers three primary questions:
- What is the probability of an observed sequence?
- What is the most likely series of states to generate an observed sequence?
- How can we learn the values for the HMMs parameters A and B given some data?
Probability of Observed Sequence
We have to add up the likelihood of the data x given every possible series of hidden states. This will lead to a complexity of O(|S|)^T. Hence, two alternate procedures were introduced to find the probability of an observed sequence.
Forward Procedure
Calculate the total probability of all the observations (from t_1) up to time t:
𝛼_𝑖 (𝑡) = 𝑃(𝑥_1 , 𝑥_2 , … , 𝑥_𝑡, 𝑧_𝑡 = 𝑠_𝑖; 𝐴, 𝐵)
Backward Procedure
Similarly calculate total probability of all the observations from final time (T) to t:
𝛽_i (t) = P(x_T , x_T-1 , …, x_t+1 , z_t= s_i ; A, B)
Hidden Markov Model Using Forward Procedure
Below is an example of a hidden Markov model using forward procedure.
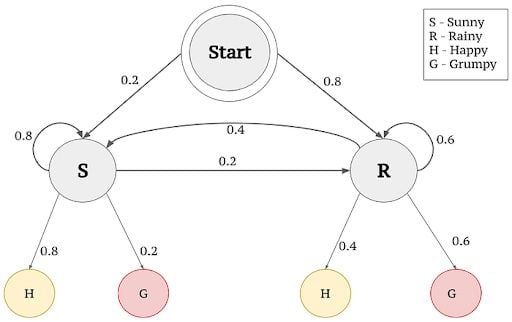
S = {hot,cold}v = {v1=1 ice cream ,v2=2 ice cream, v3=3 ice cream}, whereVis the Number of ice creams consumed in a day.- Example Sequence:
= {x1=v2,x2=v3,x3=v1,x4=v2}
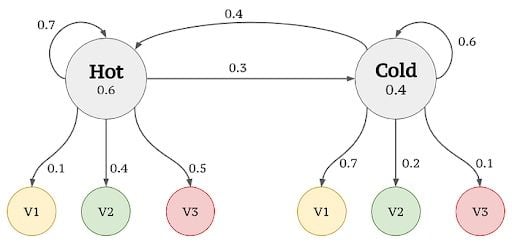
We first need to calculate the prior probabilities, that is, the probability of being hot or cold previous to any actual observation. This can be obtained from S_0 or π. From Fig.4, S_0 is provided as 0.6 and 0.4, which are the prior probabilities. Then based on Markov and HMM assumptions, we follow the steps in the figures below to calculate the probability of a given sequence.
1. First Observed Output x1=v2
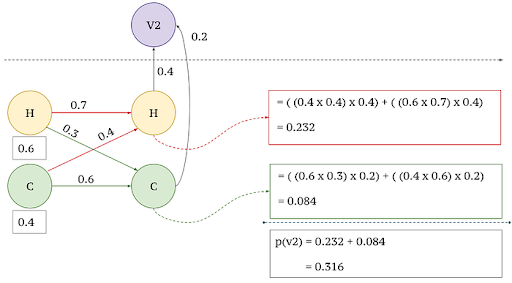
2. Observed Output x2=v3
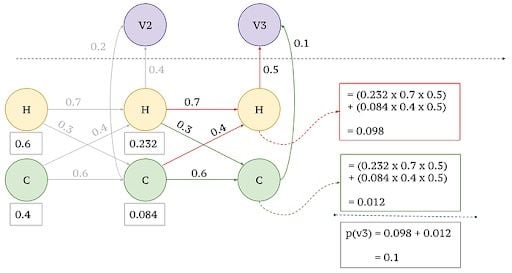
3. Observed Output x3 and x4
Similarly for x3=v1 and x4=v2, we have to simply multiply the paths that lead to v1 and v2.
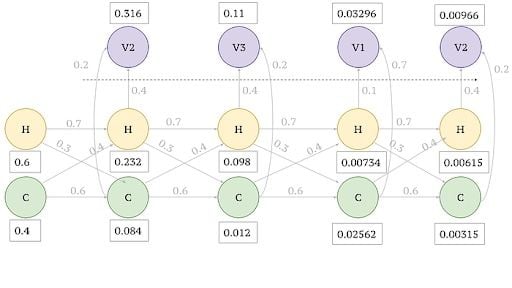
4. Maximum Likelihood Assignment
For a given observed sequence of outputs𝑥 𝜖 𝑉_𝑇, we intend to find the most likely series of states𝑧 𝜖 𝑆_𝑇. We can understand this with an example found below.
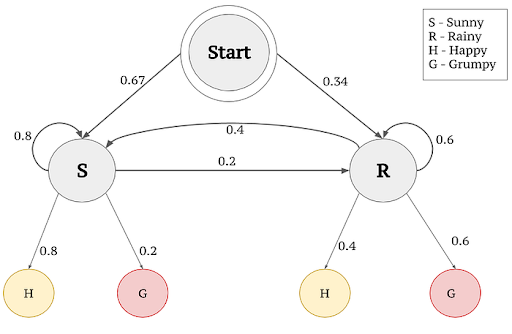
The Viterbi algorithm is a dynamic programming algorithm similar to the forward procedure which is often used to find maximum likelihood. Instead of tracking the total probability of generating the observations, it tracks the maximum probability and the corresponding state sequence.
Consider the sequence of emotions: H,H,G,G,G,H for six consecutive days. Using the Viterbi algorithm we will find out the more likelihood of the series.
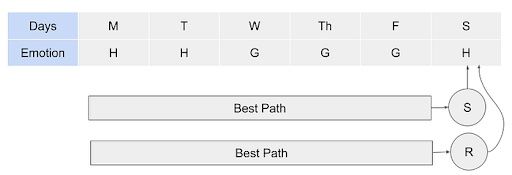
There will be several paths that will lead to sunny on Saturday, and many paths that lead to rainy on Saturday. Here, we intend to identify the best path to sunny or rainy Saturday and multiply with the transition emission probability of “Happy,” since Saturday makes the person feel “Happy.”
Let’s consider a sunny Saturday. The previous day, Friday, can be sunny or rainy. Then we need to know the best path up to Friday, and then multiply with emission probabilities that lead to a grumpy feeling. Iteratively, we need to figure out the best path at each day ending up in more likelihood of the series of days.
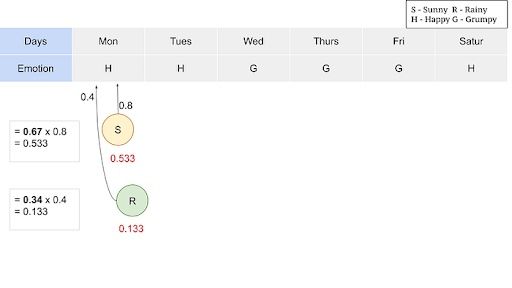
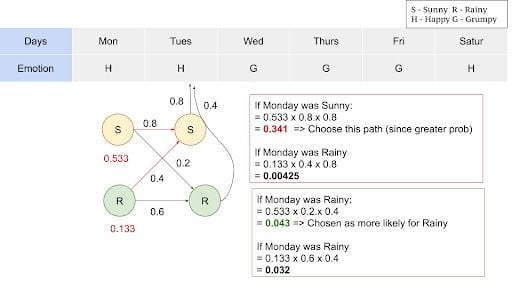
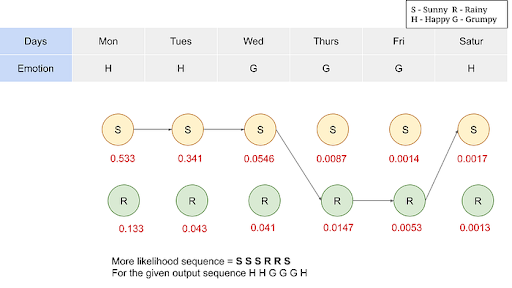
The algorithm leaves you with maximum likelihood values and we now can produce the sequence with a maximum likelihood for a given output sequence.
5. Learn the Values for the HMMs Parameters A and B
Learning in HMMs involves estimating the state transition probabilities A and the output emission probabilities B that make an observed sequence most likely. Expectation-Maximization algorithms are used for this purpose. A commonly-used algorithm known as the Baum-Welch algorithm falls under this category and uses the forward algorithm.
Frequently Asked Questions
What is a hidden Markov model?
A hidden Markov model is a statistical model in which the system being modeled is assumed to be a Markov process with unobserved (hidden) states. It’s used when you can’t observe the states themselves but only the result of a probability function of the states
What’s the difference between a hidden Markov model vs. a Markov model?
- A hidden Markov model is a probabilistic model used when the results are the product of one of several hidden internal states.
- A Markov model is a probabilistic model used to predict a sequence of events when the internal states can be observed.
What are the basic problems of hidden Markov model?
The three basic problems of a hidden Markov model (HMM) include:
- Evaluation or Likelihood Problem: Given an HMM λ = (A, B) and an observation sequence of O = O_1 O_2, … O_T, determine the likelihood P(O'λ).
- Decoding Problem: Given an HMM λ = (A, B) and an observation sequence of O = O_1 O_2, … O_T, determine the optimal hidden state sequence of Q (set of finite states).
- Learning Problem: Given an observation sequence of O = O_1 O_2, … O_T, learn and adjust the HMM parameters A and B to maximize the probability P(O'λ).


