

Natural Language Processing (NLP) is a subfield of machine learning that makes it possible for computers to understand, analyze, manipulate and generate human language. You encounter NLP machine learning in your everyday life — from spam detection, to autocorrect, to your digital assistant (“Hey, Siri?”). You may even encounter NLP and not even realize it. In this article, I’ll show you how to develop your own NLP projects with Natural Language Toolkit (NLTK) but before we dive into the tutorial, let’s look at some every day examples of NLP.
Examples of NLP Machine Learning
- Email spam filters
- Auto-correct
- Predictive text
- Speech recognition
- Information retrieval
- Information extraction
- Machine translation
- Text simplification
- Sentiment analysis
- Text summarization
- Query response
- Natural language generation
Get Started With NLP
NLTK is a popular open-source suite of Python libraries. Rather than building all of your NLP tools from scratch, NLTK provides all common NLP tasks so you can jump right in. In this tutorial, I’ll show you how to perform basic NLP tasks and use a machine learning classifier to predict whether an SMS is spam (a harmful, malicious, or unwanted message or ham (something you might actually want to read. You can find all the code below in this Github Repo.
First things first, you’ll want to install NLTK.
Type !pip install nltk in a Jupyter Notebook. If it doesn’t work in cmd, type conda install -c conda-forge nltk. You shouldn’t have to do much troubleshooting beyond that.
Importing NLTK Library
import nltk
nltk.download()This code gives us an NLTK downloader application which is helpful in all NLP Tasks.
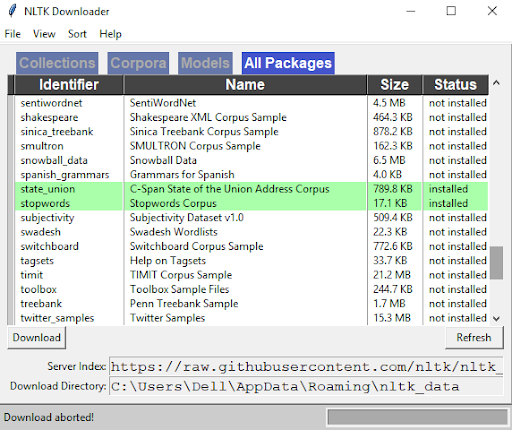
As you can see, I’ve already installed Stopwords Corpus in my system, which helps remove redundant words. You’ll be able to install whatever packages will be most useful to your project.
Prepare Your Data for NLP
Reading In-text Data
Our data comes to us in a structured or unstructured format. A structured format has a well-defined pattern. For example Excel and Google Sheets are structured data. Alternatively, unstructured data has no discernible pattern (e.g. images, audio files, social media posts). In between these two data types, we may find we have a semi-structured format. Language is a great example of semi-structured data.

As we can see from the code above, when we read semi-structured data, it’s hard for a computer (and a human!) to interpret. We can use Pandas to help us understand our data.
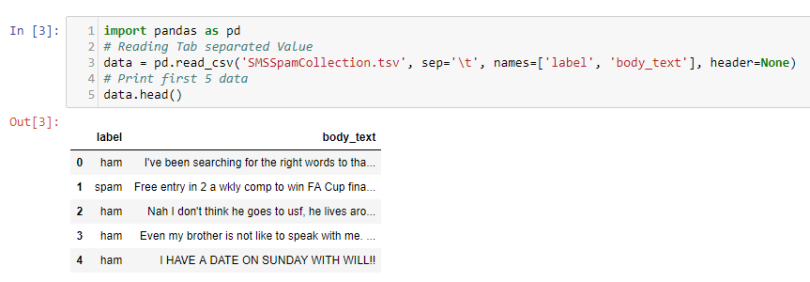
With the help of Pandas we can now see and interpret our semi-structured data more clearly.
How to Clean Your Data
Cleaning up your text data is necessary to highlight attributes that we’re going to want our machine learning system to pick up on. Cleaning (or pre-processing) the data typically consists of three steps.
How to Clean Your Data for NLP
- Remove punctuation
- Tokenize
- Remove stop words
- Stem
- Lemmatize
1. Remove Punctuation
Punctuation can provide grammatical context to a sentence which supports human understanding. But for our vectorizer, which counts the number of words and not the context, punctuation does not add value. So we need to remove all special characters. For example, “How are you?” becomes: How are you
Here’s how to do it:

In body_text_clean, you can see we’ve removed all punctuation. I’ve becomes Ive and WILL!! Becomes WILL.
2.Tokenize
Tokenizing separates text into units such as sentences or words. In other words, this function gives structure to previously unstructured text. For example: Plata o Plomo becomes ‘Plata’,’o’,’Plomo’.
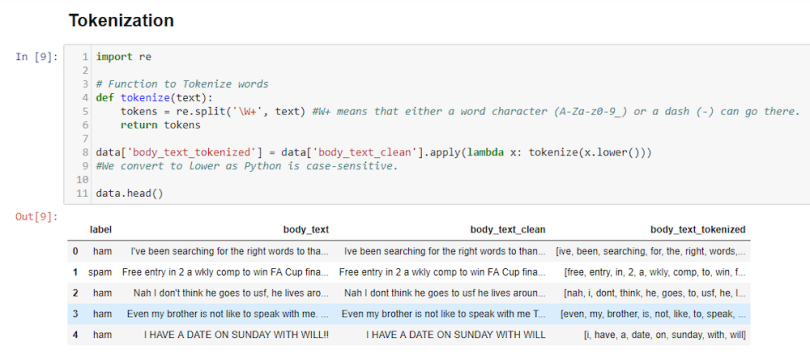
In body_text_tokenized, we’ve generated all the words as tokens.
3. Remove Stop Words
Stop words are common words that will likely appear in any text. They don’t tell us much about our data so we remove them. Again, these are words that are great for human understanding, but will confuse your machine learning program. For example: silver or lead is fine for me becomes silver, lead, fine.
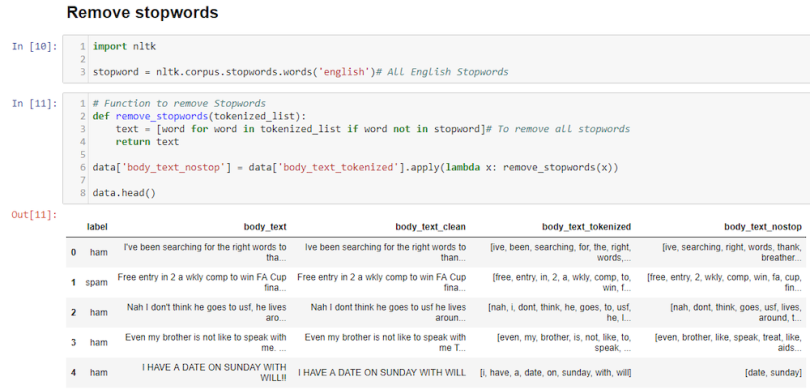
In body_text_nostop, we remove all unnecessary words like “been,” “for,” and “the.”
4. Stem
Stemming helps reduce a word to its stem form. It often makes sense to treat related words in the same way. It removes suffixes like “ing,” “ly,” “s” by a simple rule-based approach. Stemming reduces the corpus of words but often the actual words are lost, in a sense. For example: “Entitling” or “Entitled” become “Entitl.”
Note: Some search engines treat words with the same stem as synonyms.
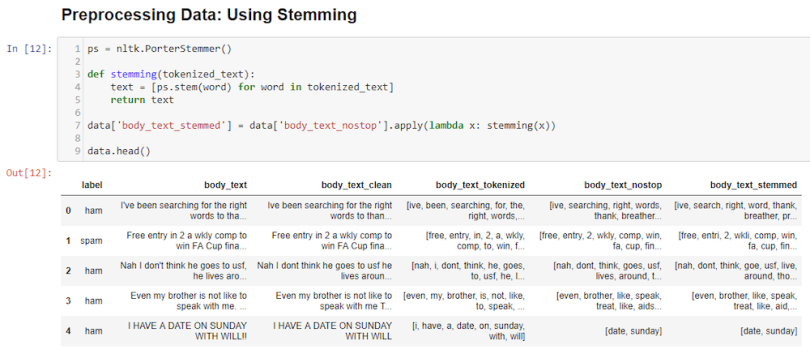
In body_text_stemmed, words like entry and goes are stemmed to entri and goe even though they don’t mean anything in English.
5. Lemmatize
Lemmatizing derives the root form (“lemma”) of a word. This practice is more robust than stemming because it uses a dictionary-based approach (i.e a morphological analysis) to the root word. For example, “Entitling” or “Entitled” become “Entitle.”
In short, stemming is typically faster as it simply chops off the end of the word, but without understanding the word’s context. Lemmatizing is slower but more accurate because it takes an informed analysis with the word’s context in mind.
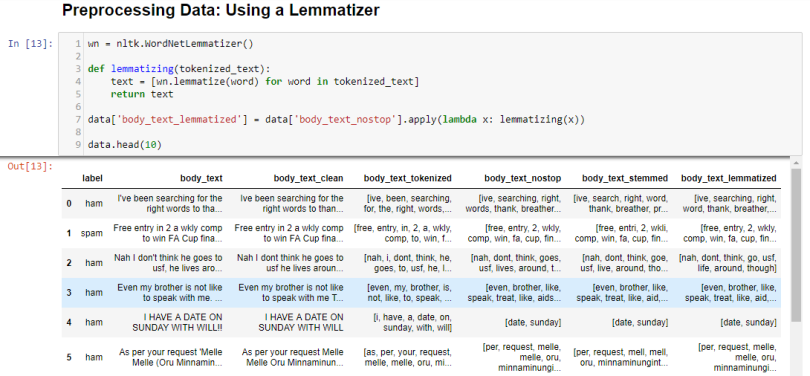
In body_text_stemmed, we can see words like “chances” are lemmatized to “chance” but stemmed to “chanc.”
Vectorize Data
Vectorizing is the process of encoding text as integers to create feature vectors so that machine learning algorithms can understand language.
Methods of Vectorizing Data for NLP
- Bag-of-Words
- N-Grams
- TF-IDF
1. Bag-Of-Words
Bag-of-Words (BoW) or CountVectorizer describes the presence of words within the text data. This process gives a result of one if present in the sentence and zero if absent. This model therefore, creates a bag of words with a document-matrix count in each text document.
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer(analyzer=clean_text)
X_counts = count_vect.fit_transform(data['body_text'])
print(X_counts.shape)
print(count_vect.get_feature_names())We apply BoW to the body_text so the count of each word is stored in the document matrix. (Check the repo).
2. N-Grams
N-grams are simply all combinations of adjacent words or letters of length n that we find in our source text. N-grams with n=1 are called unigrams, n=2 are bigrams, and so on.

Unigrams usually don’t contain much information as compared to bigrams or trigrams. The basic principle behind N-grams is that they capture which letter or word is likely to follow a given word. The longer the N-gram (higher n), the more context you have to work with.
from sklearn.feature_extraction.text import CountVectorizer
ngram_vect = CountVectorizer(ngram_range=(2,2),analyzer=clean_text) # It applies only bigram vectorizer
X_counts = ngram_vect.fit_transform(data['body_text'])
print(X_counts.shape)
print(ngram_vect.get_feature_names())We’ve applied N-Gram to the body_text, so the count of each group of words in a sentence is stored in the document matrix. (Check the repo).
3. TF-IDF
TF-IDF computes the relative frequency with which a word appears in a document compared to its frequency across all documents. It’s more useful than term frequency for identifying key words in each document (high frequency in that document, low frequency in other documents).
Note: We use TF-IDF for search engine scoring, text summarization and document clustering. Check my article on recommender systems to learn more about TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(analyzer=clean_text)
X_tfidf = tfidf_vect.fit_transform(data['body_text'])
print(X_tfidf.shape)
print(tfidf_vect.get_feature_names())We’ve applied TF-IDF in the body_text, so the relative count of each word in the sentences is stored in the document matrix. (Check the repo).
Note: Vectorizers output sparse matrices in which most entries are zero. In the interest of efficient storage, a sparse matrix will be stored if you’re only storing locations of the non-zero elements.
Feature Engineering
Feature Creation
Feature engineering is the process of using domain knowledge of the data to create features that make machine learning algorithms work. Because feature engineering requires domain knowledge, feature can be tough to create, but they’re certainly worth your time.
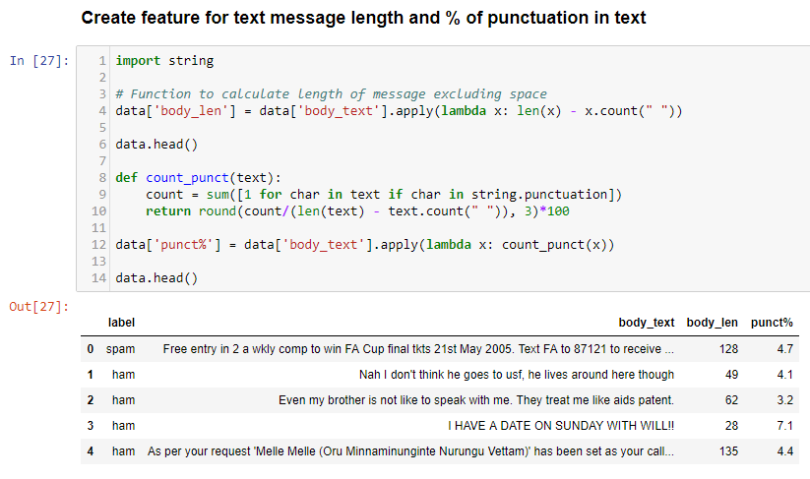
body_lenshows the length of words excluding whitespaces in a message body.punct%shows the percentage of punctuation marks in a message body.
Is Your Feature Worthwhile?
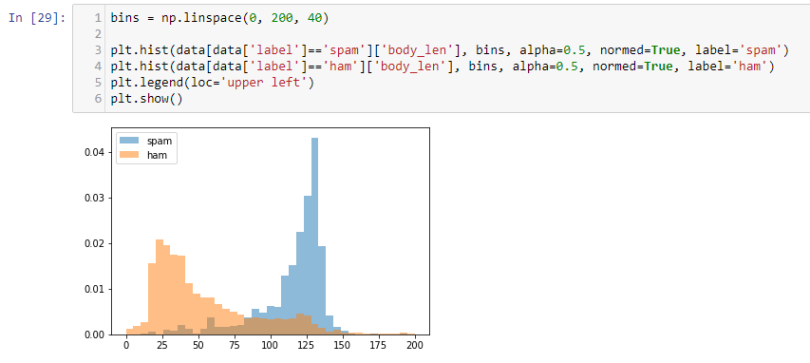
We can see clearly that spams have a high number of words compared to hams. So body_len is a good feature to distinguish.
Now let’s look at punct%.
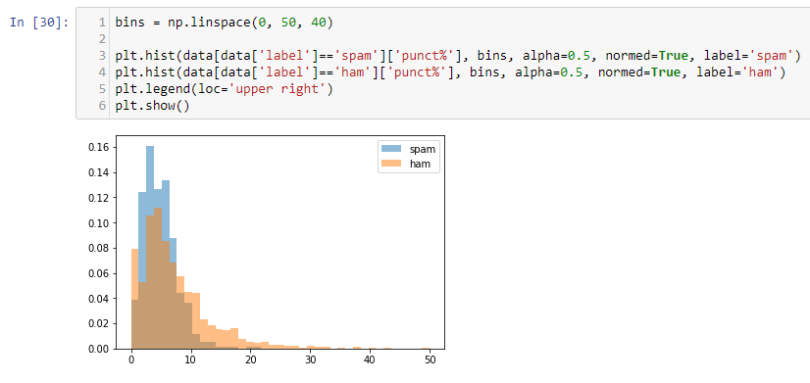
Spam has a higher percentage of punctuations but not that far away from ham. This is surprising given spam emails often contain a lot of punctuation marks. Nevertheless, given the apparent difference, we can still call this a useful feature.
Building Machine Learning Classifiers
Model Selection
We use an ensemble method of machine learning. By using multiple models in concert, their combination produces more robust results than a single model (e.g. support vector machine, Naive Bayes). Ensemble methods are the first choice for many Kaggle competitions. We construct random forest algorithms (i.e. multiple random decision trees) and use the aggregates of each tree for the final prediction. This process can be used for classification as well as regression problems and follows a random bagging strategy.
- Grid-search: This model exhaustively searches overall parameter combinations in a given grid to determine the best model.
- Cross-validation: This model divides a data set into k subsets and repeats the method k times.This model also uses a different subset as the test set in each iteration.
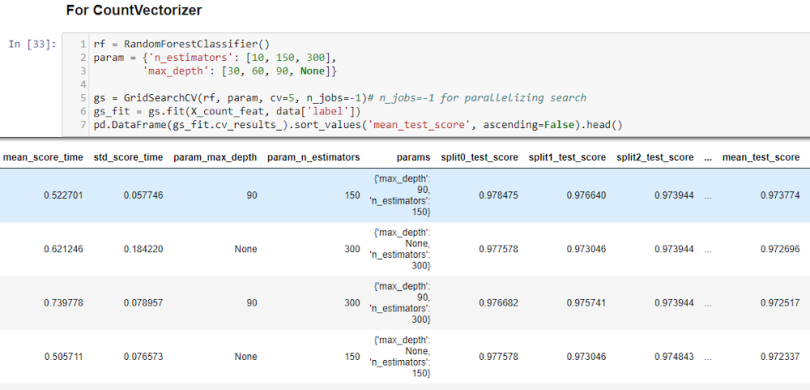
The mean_test_score for n_estimators=150 and max_depth gives the best result. Here, n_estimators is the number of trees in the forest (group of decision trees) and max_depth is the max number of levels in each decision tree.
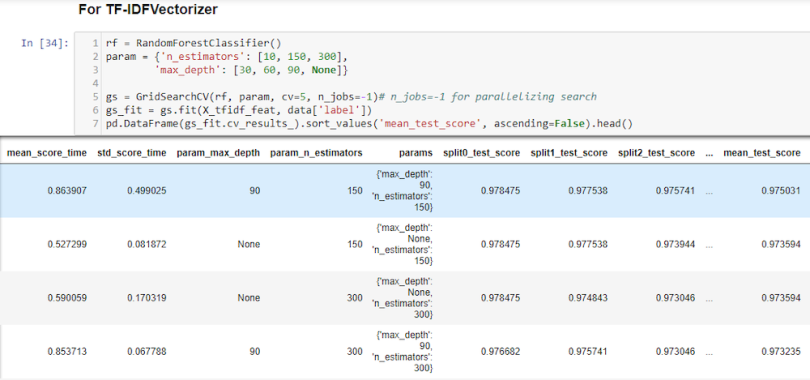
Similarly, the mean_test_score for n_estimators=150 and max_depth=90 gives the best result.
Future Improvements
You could use GradientBoosting, XgBoost for classifying. GradientBoosting will take a while because it takes an iterative approach by combining weak learners to create strong learners thereby focusing on mistakes of prior iterations. In short, compared to random forest, GradientBoosting follows a sequential approach rather than a random parallel approach.
Our NLP Machine Learning Classifier
We combine all the above-discussed sections to build a Spam-Ham Classifier.
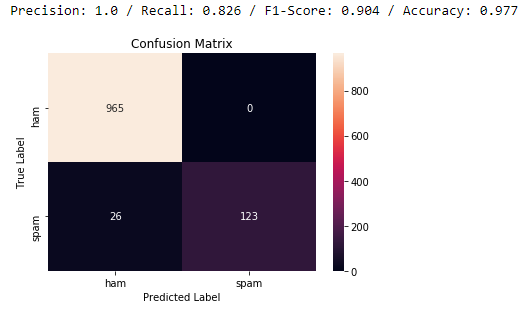
Random forest provides 97.7 percent accuracy. We obtain a high-value F1-score from the model. This confusion matrix tells us that we correctly predicted 965 hams and 123 spams. We incorrectly identified zero hams as spams and 26 spams were incorrectly predicted as hams. This margin of error is justifiable given the fact that detecting spams as hams is preferable to potentially losing important hams to an SMS spam filter.
Spam filters are just one example of NLP you encounter every day. Here are others that influence your life each day (and some you may want to try out!). Hopefully this tutorial will help you try more of these out for yourself.
-
Email spam filters — your “junk” folder
-
Auto-correct — text messages, word processors
-
Predictive text — search engines, text messages
-
Speech recognition — digital assistants like Siri, Alexa
-
Information retrieval — Google finds relevant and similar results
-
Information extraction — Gmail suggests events from emails to add on your calendar
-
Machine translation — Google Translate translates language from one language to another
-
Text simplification — Rewordify simplifies the meaning of sentences
-
Sentiment analysis —Hater News gives us the sentiment of the user
-
Text summarization — Reddit’s autotldr gives a summary of a submission
-
Query response — IBM Watson’s answers to a question
-
Natural language generation — generation of text from image or video data


