

Stable Diffusion is a powerful image generation tool that can be used to create realistic and detailed images. However, its image outputs can sometimes be noisy and blurry. A variational autoencoder (VAE) is a technique that can be used to improve the quality of images you generate with Stable Diffusion.
Stable Diffusion Variational Autoencoder (VAE) Explained
A variational autoencoder (VAE) is a technique used to improve the quality of AI-generated images you create with the text-to-image model Stable Diffusion. VAE encodes the image into a latent space and then that latent space is decoded into a new, higher-quality image.
What Is Latent Space?
Before diving into VAEs and how they work in Stable Diffusion, it’s crucial to understand the concept of latent space. Latent space collectively refers to latent variables — variables that are difficult to observe but still influence the distribution of the data.
Consider economists trying to gauge consumer confidence in the economy. While they can’t directly measure consumer confidence, they can track consumers’ buying habits to determine whether people’s spending has gone up or down. In this case, consumer confidence is the latent variable that can be indirectly observed through the variable of spending habits.
What Is a VAE?
A VAE is a generative AI model that is trained on input data and then creates variations of that data. VAEs encode an image into a latent space, which is a lower-dimensional representation of the image. The latent space is then decoded into a new image, which is typically of higher quality than the original image.
There are two main types of VAEs that can be used with Stable Diffusion: exponential moving average (EMA) and mean squared error (MSE). EMA is generally considered to be the better VAE for most applications, as it produces images that are sharper and more realistic. MSE can be used to produce images that are smoother and less noisy, but it may not be as realistic as images generated by EMA.


When Do You Use a VAE?
Sometimes when downloading checkpoints from Civitai, it will say Baked VAE. This means the VAE is already included in the checkpoint. For example, the Dark Sushi Mix Colorful checkpoint requires using the VAE, otherwise the images come out looking foggy and desaturated. Applying VAE results in a crisper, more colorful image.
What Is Stable Diffusion?
Stable Diffusion is a text-to-image generating model that uses deep learning and diffusion methods to generate realistic images based on text inputs.
In general, a VAE is needed for checkpoints that were trained using one. The VAE encodes images into a latent space that the model uses during training. At generation time, the model decodes points from the latent space back into images. Without the matching VAE, the model can’t properly reconstruct the images.
If a checkpoint says it requires a certain VAE, you need to use that VAE to get proper image generations. The model relies on the VAE to translate the latent space vectors into realistic images. Leaving it out results in foggy or distorted outputs.
Applications of VAEs
VAEs can be used across a variety of settings, but these are some of their most common use cases:
- Content generation: VAEs can be used in generator tools to produce text, images, videos and other types of content related to the training data.
- Natural language processing: The ability of VAEs to identify intricate relationships between different text elements allows them to process and generate natural-sounding language in tools like chatbots and virtual assistants.
- Anomaly detection: VAEs can process large volumes of data and learn its overall trends, identifying outliers. This makes it useful for situations like helping cybersecurity teams detect fraud and improving healthcare professionals’ ability to diagnose diseases.
- Semi-supervised learning: Semi-supervised learning trains machine learning models on small groups of labeled data and larger amounts of unlabeled data. VAEs can enhance this process by gathering details about the data set despite limited access to labeled data.
- Data denoising: Based on insights gathered from the training data, VAEs can estimate values in data sets that are either missing or corrupted by noise.
How to Use a VAE
To use VAE with Stable Diffusion, you will need to download a VAE model and place it in the stable-diffusion-webui/models/VAE directory. You can then select the VAE model that you want to use in the
Settings > Stable Diffusion > SD VAE.
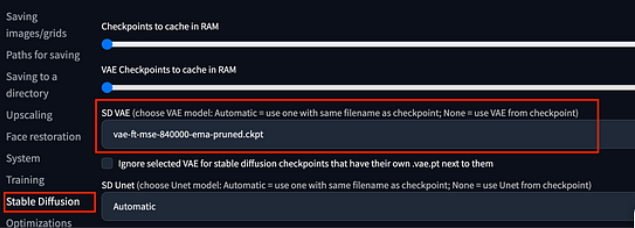
You also can add VAE select option to the quick settings list.
As you can see, the images generated with VAE are of higher quality than the images generated without VAE. If you are interested in using VAE with Stable Diffusion, I encourage you to try it out. You may be surprised at the results.
Benefits of VAEs
There are many advantages that VAEs offer to users looking to get the most out of generation tools like Stable Diffusion.
Broader Variety of Content
Because VAEs can create different variations of data sets, they give creators more freedom when developing digital content. Users can experiment with various iterations of text, images, videos and audio clips.
Precise Content Refinement
The ability of VAEs to track latent variables means users gain more insights into the characteristics of their data. In Stable Diffusion, users can produce more intricate outputs and make more personalized adjustments.
Greater Model Reliability
VAEs are excellent at estimating values that are either missing or affected by data noise. This helps Stable Diffusion avoid generating distorted images, allowing the tool to consistently deliver higher-quality outputs.
Smaller Computational Workload
VAEs compress data into a lower-dimensional latent space, cutting down on the computational resources needed for training. This makes model training faster, resulting in a much more efficient process overall.
Drawbacks of VAEs
Although VAEs can enhance the performance of generators like Stable Diffusion, users still need to consider their downsides.
Quality Issues
VAEs must make educated guesses when measuring latent variables, creating room for errors to occur. And if a VAE is unable to use the latent space to learn enough information about the input data, this can further affect the quality of its outputs.
Training Complexities
Training VAEs involves using loss functions that can fluctuate, making it difficult to develop a stable model. VAEs are also influenced by hyperparameters like learning rate and neural network architecture, further complicating the training process.
Mode Collapse
In some cases, VAEs may fail to capture the entire data distribution, resulting in a lack of diverse outputs. This can result from access to limited or low-quality training data or the failure of a VAE to adequately explore all latent variables.
Potential Costs
While VAEs compress data into latent spaces, this becomes less effective when larger or more complex data sets are involved. VAEs need to work harder and gather samples from large data sets, leading to higher workloads and costs.
Frequently Asked Questions
Why is VAE used?
Because VAEs compress data into a latent space, users apply VAEs to generate different variations of content and make more precise improvements to content. They can also be used to learn features of input data when little to no labeled data is available, and to estimate values either lost or corrupted by noise.
Why use VAE instead of AE?
When it comes to modeling a latent space, VAEs present it as a probability distribution while AEs map specific points within the latent space. VAEs can then better capture the features of the input data and generate a variety of new data samples.
Is VAE a diffusion model?
Both VAEs and diffusion models are generative AI models, but the two are distinct. VAEs compress input data into a latent space and decode this space to deliver an output. On the other hand, diffusion models gradually add and remove noise from data to produce outputs.


