

In Python, classes contain attributes and methods. An attribute is a variable that stores data. A class method is a function that belongs to the class that usually performs some logic on the class attribute(s). In this article, we will go over class inheritance, parent and child classes, the benefits of inheritance, and look at some examples of inheritance in Python.
Class Inheritance in Python
Inheritance allows you to define a new class that has access to the methods and attributes of another class that has already been defined. The class that has the methods and attributes that will be inherited by another class is called the parent class. The class that has access to the attributes and methods of the parent class is called the child class.
What Is Class Inheritance?
Inheritance allows you to define a new class that has access to the methods and attributes of another class that has already been defined. The class that has the methods and attributes that will be inherited by another class is called the parent class. Other names for the parent class that you may come across are base class and superclass. The class that has access to the attributes and methods of the parent class is called the child class. The child class is also called the subclass. In addition to defining a class that inherits from an existing class, you can define a child class that inherits from multiple parent classes.
How to Create Child Classes
A child class inherits the methods and attributes from the parent class. Other names for the child class are the subclass and derived class. The child class can be used to extend the functionality of the parent class by adding new methods and attributes. It can also be used for overriding or customizing the parent class.
The child class is defined by passing the parent class as an argument to the child class:
class ChildClass(ParentClass):
def __init__(self):
super().__iniit__(attribute)
def print_attribute(self):
print(“attribute inherited from Parent Class:”, self.attribute)
How to Create Parent Classes
A parent class has the methods and attributes that are inherited by a new child class. Parent classes have methods and attributes that can either be overridden or customized by a child class. The way to define a parent class in Python is simply by defining a class with methods and attributes, just as you would usually define an ordinary class.
Below, we define a simple example of a parent class. The init method is present, just as we have for an ordinary class. In the init method we define a class attribute and store some value in the class attribute. We then define a class method called print_attribute that prints the attribute defined in the init method:
class ParentClass:
def __init__(self, attribute):
self.attribute = attribute
def print_attribute(self):
print(Self.attribute)
Benefits of Inheritance
Inheritance is very powerful as it allows the developer to limit code duplication. By designing a hierarchy of classes, you can prevent duplicate lines of codes that perform the same task. This not only makes code easy to read, but it also significantly improves maintainability. For example, if you have many places in your code where you are calculating the error rate of model predictions, you can refactor that into a parent class method that is inherited by child classes.
When hierarchical class design (inheritance) is done well, it also makes testing and debugging easier. This is because well-defined tasks will be localized to a single place in the code base, so when a change needs to be made to how a task is completed, finding the necessary code that needs to be changed should be straightforward. Further, once a change is made to a method in the parent class, the change is propagated to all of the irrespective child classes.
Example of Class Inheritance in Python
Many of the packages we use for machine learning, such as Scikit-learn and Keras, contain classes that inherit from a parent class. For example, classes such as linear regression, support vector machines, and random forests are all child classes that inherit from a parent class called BaseEstimator. The base estimator class contains methods such as predict and fit, which most data scientists should be familiar with.
A more interesting application is defining custom child classes that inherit from parent classes in Python by using several packages. For example, you can write a custom dataframe class as a child class that inherits from the DataFrame class in Pandas. Similarly, you can define a custom classification class that inherits from the parent class RandomForestClassifier.
You can also define custom parent and child classes as well. For example, you can define a custom parent class that specifies a specific type of classification model and a child class that analyzes the model output. For example, you can also write parent and child classes for model prediction data visualization. The parent class can specify attributes of the type of classification model and its input and outputs. The child class can then generate visualizations such as confusion matrices to analyze the model output.
For our classification models, we will work with the fictitious Telco churn data set, which is publicly available on Kaggle. The data set is free to use, modify and share under the Apache 2.0 License.
Extending an existing class in a python package
We will start by reading our churn data into a Pandas data frame:
import pandas as pd
df = pd.read_csv('telco_churn.csv')Next, let’s define our input and output. We will use the fields MonthlyCharges, Gender, Tenure, InternetService, and OnlineSecurity to predict churn. Let’s convert the categorical columns into machine readable values:
df['gender'] = df['gender'].astype('category')
df['gender_cat'] = df['gender'].cat.codes
df['InternetService'] = df['InternetService'].astype('category')
df['InternetService_cat'] = df['InternetService'].cat.codes
df['OnlineSecurity'] = df['OnlineSecurity'].astype('category')
df['OnlineSecurity_cat'] = df['OnlineSecurity'].cat.codes
df['Churn'] = np.where(df['Churn']=='Yes', 1, 0)
cols = ['MonthlyCharges', 'tenure', 'gender_cat', 'InternetService_cat', 'OnlineSecurity_cat']Next, let’s define our input and output:
from sklearn.model_selection import train_test_split
X = df[cols]
y = df['Churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Now we can define our custom child class. Let’s import the random forest classifier from Scikit-learn and define an empty class called CustomClassifier. The CustomClassifier will take the RandomForestClassifier class as an argument:
from sklearn.ensemble import RandomForestClassifier
class CustomClassifier(RandomForestClassifier):
passWe will specify a test_size in our init method that allows us to specify the size of our testing and training samples. We will also use the super method to allow our custom class to inherit the methods and attributes of the random forest class. This will extend the parent random forest class with any additional custom methods.
from sklearn.ensemble import RandomForestClassifier
class CustomClassifier(RandomForestClassifier):
def __init__(self, test_size=0.2, **kwargs):
super().__init__(**kwargs)
self.test_size = test_sizeNow we will define a method that splits our data for training and testing:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
class CustomClassifier(RandomForestClassifier):
def __init__(self, test_size=0.2, **kwargs):
super().__init__(**kwargs)
self.test_size = test_size
def split_data(self):
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(X, y, test_size=self.custom_param, random_state=42)Next, we can define an instance of our class. We will pass in a value of 0.2 for our test_size. This means that the testing set will be made up of 20 percent of the data, and the training is made up of the remaining 80 percent:
rf_model = CustomClassifier(0.2)
rf_model.split_data()We can understand our child class by printing the attributes and methods of our child class:
print(dir(rf_model))We will see that, through our child class, we have all of the methods and attributes accessible to the parent random forest object:
['__abstractmethods__', '__annotations__', '__class__',
'__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__getitem__',
'__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__',
'__iter__', '__le__', '__len__', '__lt__', '__module__', '__ne__',
'__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__',
'__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__',
'_abc_impl', '_check_feature_names', '_check_n_features',
'_compute_oob_predictions', '_estimator_type', '_get_oob_predictions',
'_get_param_names', '_get_tags', '_make_estimator', '_more_tags',
'_repr_html_', '_repr_html_inner', '_repr_mimebundle_',
'_required_parameters', '_set_oob_score_and_attributes',
'_validate_X_predict', '_validate_data', '_validate_estimator',
'_validate_y_class_weight', 'apply', 'base_estimator', 'bootstrap',
'ccp_alpha', 'class_weight', 'criterion', 'decision_path',
'estimator_params', 'feature_importances_', 'fit', 'get_params',
'max_depth', 'max_features', 'max_leaf_nodes', 'max_samples',
'min_impurity_decrease', 'min_samples_leaf', 'min_samples_split',
'min_weight_fraction_leaf', 'n_estimators', 'n_features_', 'n_jobs',
'oob_score', 'predict', 'predict_log_proba', 'predict_proba',
'random_state', 'score', 'set_params', 'split_data', 'test_size',
'verbose', 'warm_start']To show that our custom child class instance has access to the parent random forest class methods and attributes, let’s try fitting a random forest model to our training data through our custom class instance:
rf_model = CustomClassifier(0.2)
rf_model.split_data()
rf_model.fit(rf_model.X_train, rf_model.y_train)This code executes with no error, despite the fact that we are calling a method that belongs to the external class. This is the beauty of inheritance in Python! It allows you to easily extend the functionality of existing classes whether they’re part of a package or custom.
We can also access random forest classifier class attributes in addition to methods. For example, feature importance is an attribute of the random forest classifier class. Let’s access and display random forest feature importance using our class instance:
importances = dict(zip(rf_model.feature_names_in_,
rf_model.feature_importances_))
print("Feature Importances: ", importances)
This gives the following results:
Feature Importances: {'MonthlyCharges': 0.5192056776242303,
'tenure': 0.3435083140171441,
'gender_cat': 0.015069195786109523,
'InternetService_cat': 0.0457071535620191,
'OnlineSecurity_cat': 0.07650965901049701}
Extending a Custom Parent Class
Another machine learning use case for Python inheritance is extending a custom parent class functionality with a child class. For example, we can define a parent class that trains a random forest model. We can then define a child class that generates a confusion matrix using inherit test set and prediction attributes.
Let’s start by defining the class we will use to build our model. For this example, we will be using the Seaborn library and the confusion metric method from the metrics module. We will also store the training and test sets as attributes of our parent:
from sklearn.metrics import confusion_matrix
import seaborn as sns
class Model:
def __init__(self):
self.n_estimators = 10
self.max_depth = 10
self.y_test = y_test
self.y_train = y_train
self.X_train = X_train
self.X_test = X_testNext, we can define a fit method that fits a random forest classifier to our training data:
from sklearn.metrics import confusion_matrix
import seaborn as sns
class Model:
...
def fit(self):
self.model = RandomForestClassifier(n_estimators = self.n_estimators, max_depth = self.max_depth, random_state=42)
self.model.fit(self.X_train, self.y_train)Finally, we can define a predict method that returns model predictions:
from sklearn.metrics import confusion_matrix
import seaborn as sns
class Model:
...
def predict(self):
self.y_pred = self.model.predict(X_test)
return self.y_predNow we can define our child class. Let’s call our child class “ModelVisulaization.” This class will inherit the method and attributes of our Model class:
class ModelVisualization(Model):
def __init__(self):
super().__init__()We will extend our model class by adding a method that generates a confusion matrix:
class ModelVisualization(Model):
def __init__(self):
super().__init__()
def generate_confusion_matrix(self):
cm = confusion_matrix(self.y_test, self.y_pred)
cm = cm / cm.astype(np.float).sum(axis=1)
sns.heatmap(cm, annot=True, cmap='Blues')Now we can define an instance of our child class and plot our confusion matrix:
results = ModelVisualization()
results.fit()
results.predict()
results.generate_confusion_matrix()This generates the following:
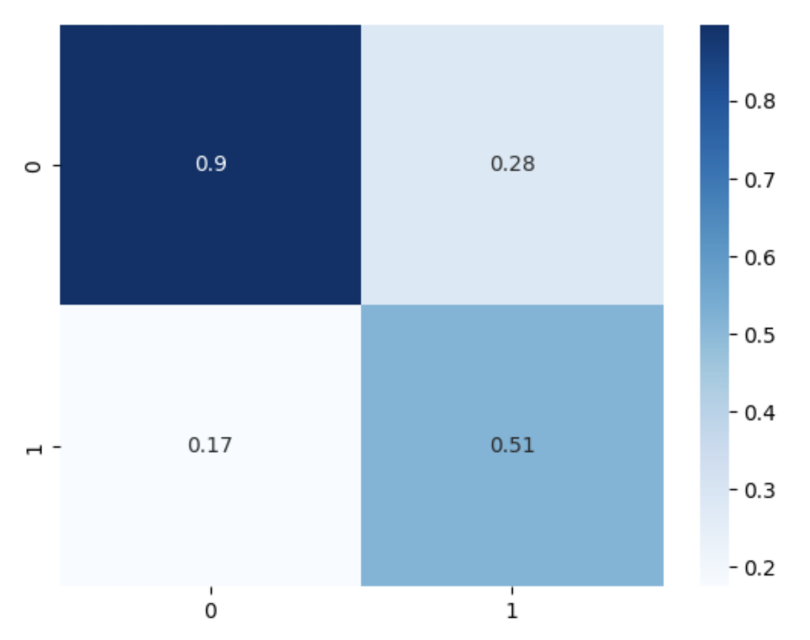
Obviously, there is some freedom around how you design custom classes, whether they’re children of classes in existing packages or of other custom parent classes. Depending on your use case, one route may make more sense than another. For example, if you simply wish to add a small number of additional attributes and methods, extending an existing class may be more appropriate. If a large number of tasks need to be customized, building custom parent and child classes would be more appropriate.
Python class inheritance can be extremely useful for data science and machine learning tasks. Extending the functionality of classes that are part of existing machine learning packages is a common use case. Although we covered extending the random forest classifier class here, you can also extend the functionality of the Pandas dataframe class and data transformation classes such as standard scaler and min max scaler. Having a general understanding of how to use Python inheritance to extend existing classes is valuable for data scientists and machine learning engineers.
Further, there are instances where many tasks that are part of distinct workflows need to be customized. We considered the example of extending a custom class that we used to build a classification model with visualization functionality. This allows us to inherit the methods and attributes of the modeling class and generate visualizations in the child class.
The code from this post is available on GitHub.
Frequently Asked Questions
What is class inheritance in Python?
Class inheritance in Python allows a new class (child class) to access methods and attributes from an existing class (parent class), enabling code reuse and customization.
What is the difference between a parent class and a child class?
A parent class defines the original attributes and methods, while a child class inherits and can extend or override that functionality.
Can a child class inherit from multiple parent classes in Python?
Yes, Python supports multiple inheritance, allowing a child class to inherit from more than one parent class.


