

Function wrappers are useful tools for modifying the behavior of functions. In Python, they’re called decorators. Decorators allow us to extend the behavior of a function or a class without changing the original implementation of the wrapped function.
What Are Python Wrappers?
Function wrappers, called decorators in Python, are used to modify the behavior of functions without changing the original implementation of the wrapped function. Common applications include monitoring the runtime of function calls or debugging other functions.
The functools module in Python makes defining custom decorators easy, which can “wrap” (modify/extend) the behavior of another function. Defining function wrappers is very similar to defining ordinary functions in Python. Once the function decorator is defined, then we simply use the “@” symbol and the name of the wrapper function in the line of code preceding the function we’d like to modify or extend. The process for defining timer and debugger function wrappers follows similar steps.
Below, we cover how to define and apply function wrappers for profiling machine learning model runtime for a simple classification model. We will use this function wrapper to monitor the runtime of the data preparation, model fit and model predict steps in a simple machine learning workflow. We will also see how to define and apply function wrappers for debugging these same steps.
I will be working with Deepnote, a data science notebook that makes running reproducible experiments simple, and with the fictitious Telco Churn data set, which is publicly available on Kaggle.
Monitoring Runtime of Machine Learning Workflow Using Wrappers
Let’s go through an example to see how this process works.
Data Preparation
Let’s start the data preparation process by navigating to the Deepnote platform (sign up is free if you don’t already have an account). Let’s create a project.

And name our project function_wrappers and name our notebook profiling_debugging_mlworkflow:
Let’s add our data to Deepnote:
We will be using the Pandas library to handle and process our data. Let’s import it:
import pandas as pdNext, let’s define a function that we will call data_preparation:
def data_preparation():
passLet’s add some basic data processing logic. This function will perform five tasks:
- Read in data
- Select relevant columns: The function will take a list of column names as input
- Clean the data: Specify column data types
- Split data for training and testing: The function will will take test size as input
- Return training and testing set
Let’s first add the logic to read in the data. Let’s also add logic to display the first five rows:
def data_preparation(columns, test_size):
df = pd.read_csv("telco_churn.csv")
print(df.head())Let’s call our data prep function. For now, let’s pass “none” as arguments for columns and test size:
def data_preparation(columns, test_size):
df = pd.read_csv("telco_churn.csv")
print(df.head())
data_preparation(None, None)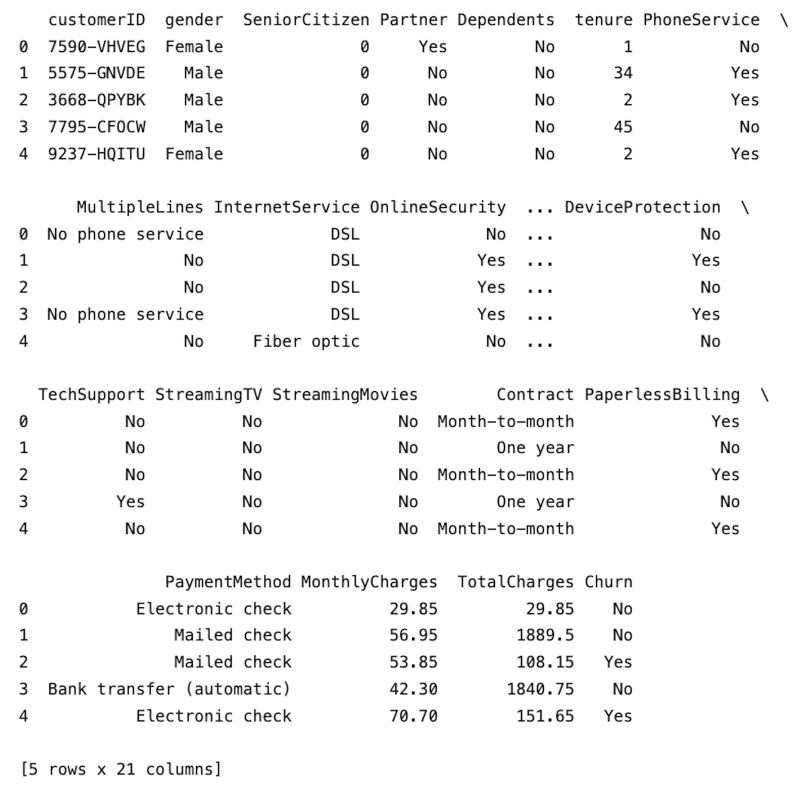
Next, within our data_preparation method let’s use the columns variable to filter our data frame, define a list of column names we will use, and call our function with the columns variable:
def data_preparation(columns, test_size):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
print(df_subset.head())
columns = ["gender", "tenure", "PhoneService", "MultipleLines", "TotalCharges", "Churn"]
data_preparation(columns, None)
Next, let’s specify another function argument, which we will use to specify data types of each column. Within a for loop in our function, we will specify the data for each column, which we will get from our input dictionary of data type mappings:
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
print(df_subset.head())
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
data_preparation(columns, None, datatype_dict)Within another for loop, we will convert all categorical columns to machine-readable codes:
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
for col in columns:
if datatype_dict[col] == "category":
df_subset[col] = df_subset[col].cat.codes
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
data_preparation(columns, None, datatype_dict)Finally, let’s specify our input and output, split our data for training and testing and return our train and test sets. First, let’s import the train test split method from the model selection module in Scikit-learn:
from sklearn.model_selection import train_test_splitNext, let’s specify our inputs, outputs, training and testing sets:
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
for col in columns:
if datatype_dict[col] == "category":
df_subset[col] = df_subset[col].cat.codes
X = df_subset[["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges",]]
y = df_subset["Churn"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)
return X_train, X_test, y_train, y_test
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
X_train, X_test, y_train, y_test = data_preparation(columns, 0.33, datatype_dict)Model Training
Now that we have our training and test data prepared, let’s train our classification model. For simplicity, let’s define a function that trains a random forest classifier with default parameters and sets a random state reproducibility. The function will return the trained model object. Let’s start by importing the random forest classifier:
from sklearn.ensemble import RandomForestClassifierNext, let’s define our fit function and store the trained model object:
def fit_model(X_train,y_train):
model = RandomForestClassifier(random_state=42)
model.fit(X_train,y_train)
return model
model = fit_model(X_train,y_train)Model Predictions and Performance
Let’s also define our predict function that will return model predictions
def predict(X_test, model):
y_pred = model.predict(X_test)
return y_pred
y_pred = predict(X_test, model)Finally, let’s define a method that reports classification performance metrics
def model_performance(y_pred, y_test):
print("f1_score", f1_score(y_test, y_pred))
print("accuracy_score", accuracy_score(y_test, y_pred))
print("precision_score", precision_score(y_test, y_pred))
model_performance(y_pred, y_test)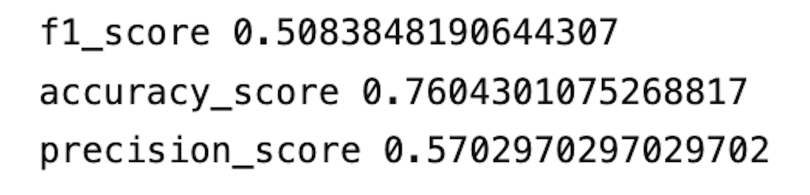
Now, if we want to use function wrappers to define our timer, we need to import the functools and time modules:
import functools
import timeNext, let’s define our timer function. We will call it runtime_monitor. It will take a parameter called input_function as an argument. We will also pass the input function to the wraps method in the functools wrappers, which we will place before our actual timer function, called runtime_wrapper:
def runtime_monitor(input_function):
@functools.wraps(input_function)
def runtime_wrapper(*args, **kwargs):Next, within the scope of runtime wrapper, we specify the logic for calculating the execution runtime for our input function. We define a starting time value, the return value of our function (which is where we execute our function) an endtime value, and the runtime value, which is the difference between the start and endtime
def runtime_wrapper(*args, **kwargs):
start_value = time.perf_counter()
return_value = input_function(*args, **kwargs)
end_value = time.perf_counter()
runtime_value = end_value - start_value
print(f"Finished executing {input_function.__name__} in {runtime_value} seconds")
return return_valueOur timer function (runtime_wrapper) is defined within the scope of our runtime_monitor function. The full function is as follows:
def runtime_monitor(input_function):
@functools.wraps(input_function)
def runtime_wrapper(*args, **kwargs):
start_value = time.perf_counter()
return_value = input_function(*args, **kwargs)
end_value = time.perf_counter()
runtime_value = end_value - start_value
print(f"Finished executing {input_function.__name__} in {runtime_value} seconds")
return return_value
return runtime_wrapperWe can then use runtime_monitor to wrap our data_preparation, fit_model, predict, and model_performance functions. For data_preparation, we have the following:
@runtime_monitor
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
for col in columns:
if datatype_dict[col] == "category":
df_subset[col] = df_subset[col].cat.codes
X = df_subset[["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges",]]
y = df_subset["Churn"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)
return X_train, X_test, y_train, y_test
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
X_train, X_test, y_train, y_test = data_preparation(columns, 0.33, datatype_dict)
We see our data preparation function takes 0.04 to execute. For fit_model, we have:
@runtime_monitor
def fit_model(X_train,y_train):
model = RandomForestClassifier(random_state=42)
model.fit(X_train,y_train)
return model
model = fit_model(X_train,y_train)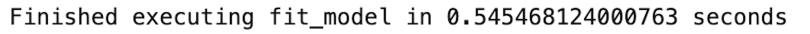
For our predict:
@runtime_monitor
def predict(X_test, model):
y_pred = model.predict(X_test)
return y_pred
y_pred = predict(X_test, model)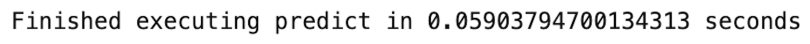
And finally, for model performance:
@runtime_monitor
def model_performance(y_pred, y_test):
print("f1_score", f1_score(y_test, y_pred))
print("accuracy_score", accuracy_score(y_test, y_pred))
print("precision_score", precision_score(y_test, y_pred))
model_performance(y_pred, y_test)
We see that the fit method is the most time consuming, which we would expect. Being able to reliably monitor the runtime of these functions is essential for resource management when building even simple machine learning workflows such as this.
Debugging Machine Learning Models Using Wrappers
Defining a debugger function wrapper is also a straightforward process. Let’s start by defining a function called debugging method. Similar to our timer function, it will take a function as input. We will also pass the input function to the wraps method in the functools wrappers, which we will place before our actual debugger function, called debugging_wrapper. The debugging_wrapper will take arguments and keyword arguments as inputs:
def debugging_method(input_function):
@functools.wraps(input_function)
def debugging_wrapper(*args, **kwargs):Next, we will store the representations of arguments, the key words and their values in lists called arguments and keyword_arguments respectively:
def debugging_wrapper(*args, **kwargs):
arguments = []
keyword_arguments = []
for a in args:
arguments.append(repr(a))
for key, value in kwargs.items():
keyword_arguments.append(f"{key}={value}")Next, we will concatenate arguments and keyword_argument and then join them in a string:
def debugging_wrapper(*args, **kwargs):
...#code truncated for clarity
function_signature = arguments + keyword_arguments
function_signature = "; ".join(function_signature) Finally, we will print the function name, its signature and its return value:
def debugging_wrapper(*args, **kwargs):
...#code truncated for clarity
print(f"{input_function.__name__} has the following signature: {function_signature}")
return_value = input_function(*args, **kwargs)
print(f"{input_function.__name__} has the following return: {return_value}") The debugging_wrapper function will also return the return value of the input function. The full function is as follows:
def debugging_method(input_function):
@functools.wraps(input_function)
def debugging_wrapper(*args, **kwargs):
arguments = []
keyword_arguments = []
for a in args:
arguments.append(repr(a))
for key, value in kwargs.items():
keyword_arguments.append(f"{key}={value}")
function_signature = arguments + keyword_arguments
function_signature = "; ".join(function_signature)
print(f"{input_function.__name__} has the following signature: {function_signature}")
return_value = input_function(*args, **kwargs)
print(f"{input_function.__name__} has the following return: {return_value}")
return return_value
return debugging_wrapperData Preparation
We can now wrap our data_preparation function with our debugging_method:
@debugging_method
@runtime_monitor
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
for col in columns:
if datatype_dict[col] == "category":
df_subset[col] = df_subset[col].cat.codes
X = df_subset[["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges",]]
y = df_subset["Churn"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)
return X_train, X_test, y_train, y_test
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
X_train, X_test, y_train, y_test = data_preparation(columns, 0.33, datatype_dict)Model Training
We can do the same for our fit function:
@debugging_method
@runtime_monitor
def fit_model(X_train,y_train):
model = RandomForestClassifier(random_state=42)
model.fit(X_train,y_train)
return model
model = fit_model(X_train,y_train)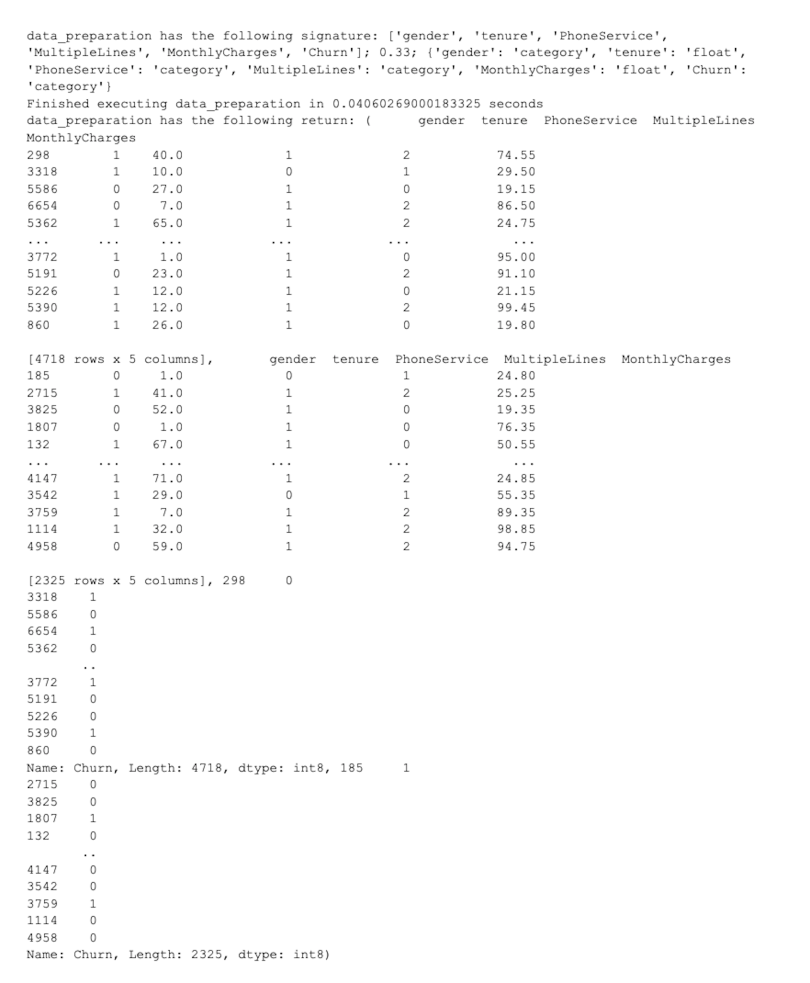
Model Predictions and Performance
And for our predict function:
@debugging_method
@runtime_monitor
def predict(X_test, model):
y_pred = model.predict(X_test)
return y_pred
y_pred = predict(X_test, model)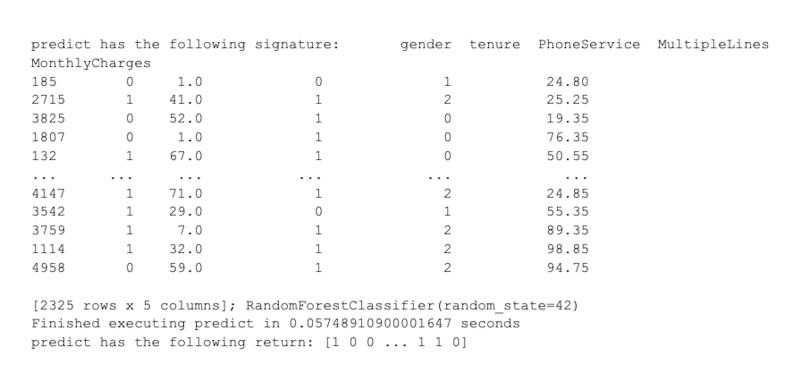
And finally, for our performance function:
@debugging_method
@runtime_monitor
def model_performance(y_pred, y_test):
print("f1_score", f1_score(y_test, y_pred))
print("accuracy_score", accuracy_score(y_test, y_pred))
print("precision_score", precision_score(y_test, y_pred))
model_performance(y_pred, y_test)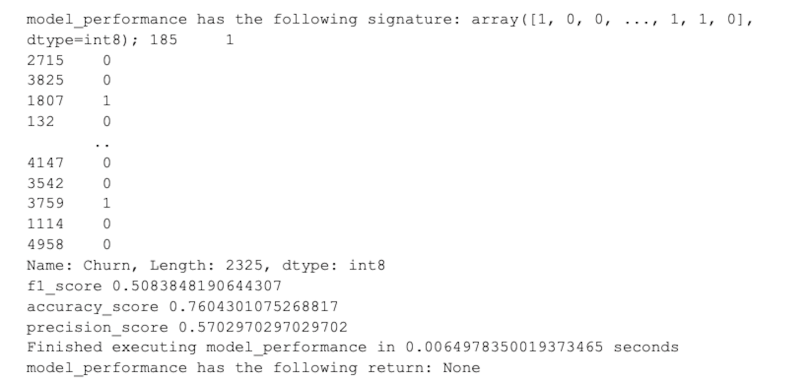
The code in this post is available on GitHub.
Function Wrapper Uses in Python
Function wrappers have a wide range of applications in software engineering, data analytics and machine learning.
Monitoring Function and Operation Runtimes
When developing and fitting machine learning models, runtimes for steps like data preparation, model training and predicting steps can vary depending on the size of the data and operation complexity. With this in mind, using wrappers to monitor how runtime of these operations changes when the data changes is useful. For example, wrappers allow developers to monitor how long a function takes to execute and run successfully. This process is essential for managing computational resources like time and costs.
Debugging Other Functions
Debugging with function wrappers is also useful when building machine learning models. In Python, defining a debugger function wrapper that prints the function arguments and return values is straightforward. Function wrappers can be used to inspect causes of failed function executions using a few lines of code, which can help resolve issues with data preparation, model fit calls and model prediction calls.
For example, in data preparation, issues and bugs may arise when data is refreshed or model inputs for training are modified. In this case, function wrappers can be used to help indicate how changes in inputs, array shapes and array lengths may be causing fit calls to fail.
Function wrappers in Python can help simplify runtime monitoring and debugging. Having reliable tools for runtime monitoring and debugging is valuable for both data scientists and machine learning engineers.
Frequently Asked Questions
What is a Python wrapper?
Python wrappers are functions or classes that can encapsulate, or “wrap,” the behavior of another function. Wrappers allow an existing function to be modified or extended without changing its core source code.
What does @wraps do in Python?
In Python, “@wraps” is a decorator provided by the functools module. Using @wraps transfers metadata (attributes like __name__, __doc__, etc.) from another function or class to its wrapper function.
What is a wrapper in programming?
A wrapper is a function in a programming language used to encapsulate another function and its behavior. Encapsulation in programming means combining data and associated data methods into one unit.
What is the difference between wrapper and decorator in Python?
Wrappers are called decorators in Python. A decorator is a kind of wrapper, where it works to wrap another function to modify its behavior.


