

Missing values are commonly encountered when processing large collections of data. A missing value can correspond to an empty variable, an empty list, an empty dictionary, a missing element in a column, an empty dataframe, or even an invalid value. Defining empty variables and data structures is an essential part of handling missing or invalid values. This is important for tasks such as variable initialization, type checking and specifying function default arguments.
For variables such as floats, integers, booleans, and strings, invalid types can often lead to failing or error-causing code. This can trigger programs to crash midway through a large processing job, which can lead to a significant waste in time and computational resources. Being able to define functions with sensible default values such that they return a consistent and expected output error free is an essential skill for every programmer and can save the engineer or data scientist much headache down the road.
Some of the topics we will cover include:
How to Define Empty Variables and Data Structures in Python
- Empty variables with None and NaN
- Empty lists for initialization
- Empty dictionaries for initialization
- Empty dataframes for initialization
- NaN default function arguments
- Empty list default function arguments
- Empty dictionary default function arguments
- Empty dataframe default function arguments
- Other uses for empty variables
Defining Empty Variables with None and NaN
Defining empty variables in Python is straightforward. If you wish to define a placeholder for a missing value that will not be used for calculations, you can define an empty variable using the None keyword. This is useful because it clearly indicates that the value for a variable is missing or not valid.
For example, let’s say we have demographic data with sets of values for age, income (USD), name and senior citizen status:
age1 = 35
name1 = “Fred Philips”
income1= 55250.15
senior_citizen1 = False
age2 = 42
name2 = “Josh Rogers”
income2=65240.25
senior_citizen1 = False
age3 = 28
name3 = “Bill Hanson”
income3=79250.65
senior_citizen3 = FalseThere may be instances where some information may be missing or include an invalid value. For example, it is possible that we may receive data with invalid values such as a character or string for the age or a floating point or integer for the name. This can occur often with web applications that use free-text user input boxes. If the app isn’t able to detect and alert the user to an invalid input value, it will include the invalid values in its database. Consider the following example:
age4 = “#”
name4 = 100
income4 = 45250.65
senior_citizen4 = “Unknown”For this person, we have an age value of “#,” which clearly is invalid. Furthermore, the name entered is a number, which also doesn’t make sense. Finally, for our senior_citizen variable we have “Unknown.” If we are interested in keeping this data, since the income is valid, it is best to define age, name and senior_citizen as empty variables using the None keyword.
age4 = None
name4 = None
income4 = 45250.65
senior_citizen4 = NoneThis way any developer looking at the data will clearly understand the valid values for age, name and senior_citizen are missing. Further, the income values can still be used to calculate statistics since all of the values for income are present.
A limitation of the None keyword is that it can’t be used in calculations. For example, suppose we wanted to calculate the average age for the four instances we have defined:
avg_age = (age1 + age2 + age3 + age4)/4
If we try to run our script it will throw the following error:
avg_age = (age1 + age2 + age3 + age4)/4
TypeError: unsupported operand type(s) for +: ‘int’ and ’NoneType’This is a type error stating that we are unable to use the ‘+’ operator (addition) between integers and None values.
We can remedy this by using the NaN (not a number) values from NumPy as our missing value placeholder:
age4 = np.nan
name4 = np.nan
income4 = 45250.65
senior_citizen4 = np.nan
avg_age = (age1 + age2 + age3 + age4)/4Since we have a NaN in our calculation, the result will also be NaN. Now the code will be able to run successfully. Further, this is especially useful when dealing with data structures such as dataframes, as there are methods in Python that allow you to handle NaN values directly.
In addition to defining empty variables, it is often useful to store empty data structures in variables. This has many uses but we will discuss how default empty data structures can be used for type checking.
Defining an Empty List for Initialization
The simplest application of storing an empty list in a variable is for initializing a list that will be populated. For example, we can initialize a list for each of the attributes we defined earlier (age, name, income, senior_status):
ages = []
names = []
incomes = []
senior_citizen = []These empty lists can then be populated using the append() method:
ages.append(age1)
ages.append(age2)
ages.append(age3)
ages.append(age4)
print(“List of ages: “, ages)We can do the same for name, income, and senior status:
names.append(name1)
names.append(name2)
names.append(name3)
names.append(name4)
print(“List of names: “, names)
incomes.append(income1)
incomes.append(income2)
incomes.append(income3)
incomes.append(income4)
print(“List of incomes: “, incomes)
senior_citizen.append(income1)
senior_citizen.append(income2)
senior_citizen.append(income3)
senior_citizen.append(income4)
print(“List of senior citizen status: “, senior_citizen)Which returns:
List of ages: [35, 42, 28, nan]
List of names: [’Fred Philips’, ‘Josh Rogers’, ‘Bill Hanson’, nan]
List of incomes: [5525.15, 65240.25, 79250.65, 45250.65]
List of senior citizen status: [False, False, False, nan]
Defining an Empty Dictionary for Initialization
We can also use an empty dictionary for initialization:
demo_dict = {}
And use the list we populated earlier to populate the dictionary:
demo_dict['age'] = ages
demo_dict['name'] = names
demo_dict['income'] = incomes
demo_dict['senior_citizen'] = senior_citizen
print(“Demographics Dictionary”)
print(demo_dict)Which returns:
Demographics Dictionary
{’age’: [35, 42, 28, nan], ’name’: [’Fred Philips’, ‘Josh Rogers’, ‘Bill Hanson’, nan], ‘income’: [55250.15, 65240.25, 79250.65, 45250.65], ‘senior_citizen’: [False, False, False, nan]}
Defining an Empty Dataframe for Initialization
We can also do something similar with Pandas dataframes:
import pandas as pd
demo_df = pd.DataFrame()
demo_df['age'] = ages
demo_df['name'] = names
demo_df['income'] = incomes
demo_df['senior_citizen'] = senior_citizen
print(“Demographics Dataframe”)
print(demo_df)Which will return:
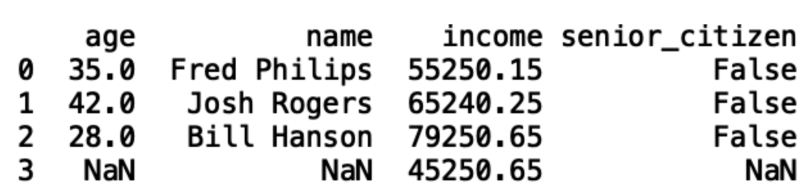
Notice the logic for populating dictionaries and dataframes are similar. Which data structure you use depends on your needs as an engineer, analyst, or data scientist. For example, dictionaries are more useful if you like to produce JSON files and don’t need array lengths to be equal, while data frames are more useful for generating CSV files.
NaN Default Function Arguments
Another use for defining empty variables and data structures are for default function arguments.
For example, consider a function that calculates income after federal tax. The tax rate for the range of incomes we’ve defined so far is around 22 percent. We can define our function as follows:
def income_after_tax(income):
after_tax = income - 0.22*income
return after_taxIf we call our function with income this way:
after_tax1 = income_after_tax(income1)
print(“Before: “, income1)
print(“After: “, after_tax1)And print the results we get the following:
Before: 55250.15
After: 43095.117This works fine for this example, but what if we have an invalid value for income like an empty string? Let’s pass in an empty string and try to call our function:
after_tax_invalid = income_after_tax(‘’)
TypeError: can’t multiple sequence by non-int of type ‘float’We get a type error stating that we can’t multiply a sequence, which is the empty string, by a non-integer type float. The function call fails and after_tax never actually gets defined. We ideally would like to guarantee that the function runs for any value of income, and after_tax6 at least gets defined with some default value. We can do this by defining a default NaN argument for after_tax and type check the income. We only calculate after_tax if income is a float otherwise, after_tax is NaN:
def income_after_tax(income, after_tax = np.nan):
if income is float:
after_tax = income - 0.22*income
return after_taxWe can then pass any invalid value for income and we will still be able to run our code successfully:
after_tax_invalid1 = income_after_tax(‘’)
after_tax_invalid2 = income_after_tax(None)
after_tax_invalid3 = income_after_tax(“income”)
after_tax_invalid4 = income_after_tax(True)
after_tax_invalid5 = income_after_tax({})
print(“after_tax_invalid1: “, after_tax_invalid1)
print(“after_tax_invalid2: “, after_tax_invalid2)
print(“after_tax_invalid3: “, after_tax_invalid3)
print(“after_tax_invalid4: “, after_tax_invalid4)
print(“after_tax_invalid5: “, after_tax_invalid5)Returning:
after_tax_invalid1: nan
after_tax_invalid2: nan
after_tax_invalid3: nan
after_tax_invalid4: nan
after_tax_invalid5: nanThe reader may wonder why an invalid value is passed to a function to begin with. In practice, function calls are often made on thousands-to-millions of user inputs. If the user input is a free-text response, and not a dropdown menu, it is difficult to guarantee that the data types are correct unless it is explicitly enforced by the application. Because of this, we’d want to be able to process valid and invalid inputs without the application crashing or failing.
Empty List Default Function Arguments
Defining empty data structures as default arguments can also be useful. Let’s consider a function that takes our list of incomes and calculates the after-tax income.
def get_after_tax_list(input_list):
out_list = [x - 0.22*x for x in input_list]
print(“After Tax Incomes: “, out_list)If we call this with our incomes list, we get:
get_after_tax_list(incomes)
After Tax Incomes: [43095.117, 50887.395000000004, 61815.507, 35295.507]If we call this with a value that is not a list, for example an integer, we get:
get_after_tax_list(5)
out_list = [x - 0.22*x for x in input_list]
TypeError: ‘int’ object is not iterableNow, if we include an empty list as the default value for our output list, our script runs successfully:
get_after_tax_list(5)
After Tax Incomes: []
Empty Dictionary Default Function Arguments
Similar to defining default arguments as empty lists, it is also useful to define functions with empty dictionary default values. Let’s define a function that takes an input dictionary, like the demo_dict that we defined earlier, and it will return a new dictionary with the mean income.
def get_income_truth_values(input_dict):
output_dict= {’avg_income’: np.mean(input_dict['income'])}
print(output_dict)
return output_dictLet’s call our function with demo_dict.
get_income_truth_values(demo_dict)
{’avg_income’: 61247.924999999996}Now let’s try passing in an invalid value for input_dict. Let’s pass the integer value 10000:
get_income_truth_values(10000)
out_dict+ {’avg_income’: np.mean(input_dict[’income’])}
TypeError: ‘int’ object is not subscriptableWe get a type error stating that the integer object, 1000, is not subscriptable. We can correct this by checking if the type of our input is a dictionary, checking if the appropriate key is in the dictionary and setting a default argument for our output dictionary that will be returned if the first two conditions are not met. This way, if the conditions are not met, we can still run our code without getting an error. For our default argument we will simply specify an empty dictionary for the output_dict.
def get_income_truth_values(input_dict, output_dict={}):
if type(input_dict) is dict and ‘income’ in input_dict:
output_dict= {’avg_income’: np.mean(input_dict['income'])}
print(output_dict)
return output_dict And we can make the same function calls successfully.
get_income_truth_values(10000) We can also define a default dictionary with an NaN value for the avg_income. This way we will guarantee that we have a dictionary with the expected key, even when we call our function with an invalid input:
def get_income_truth_values(input_dict, output_dict={’avg_income’: np.nan}):
if type(input_dict) is dict and ‘income’ in input_dict:
output_dict= {’avg_income’: np.mean(input_dict['income'])}
print(output_dict)
return output_dict
get_income_truth_values(demo_dict)
get_income_truth_values(10000) Which will print:
{’avg_income’: 61247.924999999996}
{’avg_income’: nan}
Empty DataFrame Default Function Arguments
Similar to our examples with lists and dictionaries, a default function with a default empty dataframe can be very useful. Let’s modify the dataframe we define to include the state of residence for each person:
demo_df['state'] = ['NY', 'MA', 'NY', 'CA']Let’s also impute the missing values for age and income using the mean:
demo_df['age'].fillna(demo_df['age'].mean(), inplace=True)
demo_df['income'].fillna(demo_df['income'].mean(), inplace=True)Next let’s define a function that performs a groupby() function on the states and calculates the mean for the age and income fields. The result will give use the average age and income for each state:
def income_age_groupby(input_df):
output_df = input_df.groupby(['state'])['age', 'income'].mean().reset_index()
print(output_df)
return output_df
income_age_groupby(demo_df)The result looks like:

As you’d likely be able to guess by this point, if we call our function with a data type that is not a dataframe, we will get an error. We get an attribute error stating that the list object has no attribute groupby. This makes sense since the groupby() method belongs to dataframe objects:
income_age_groupby([1,2,3])
output_df = input_df.groupby([’state’])[’age’, ‘income’].mean().reset_index()
AttributeError: ‘list’ object has no attribute ‘groupby’We can define a default data frame containing NaNs for each of the expected fields and check if the necessary columns are present:
def income_age_groupby(input_df, output_df = pd.DataFrame({’state’: [np.nan], ‘age’: [np.nan], ‘income’:[np.nan]})):
if type(input_df) is type(pd.DataFrame()) and set(['age', 'income', 'state']).issubset(input_df.columns):
output_df = input_df.groupby(['state'])['age', 'income'].mean().reset_index()
print(output_df)
return output_df
income_age_groupby([1,2,3])We see that our code ran successfully with the invalid data values.

While we considered examples for data we made up, these methods can be extended to a variety of data processing tasks whether it be for software engineering, data science or machine learning. I encourage you to try applying these techniques in your own data processing code!
The code in this post is available on GitHub.
Other Uses for Empty Variables
As demonstrated above, defining empty variables and data structures are useful for tasks such as type checking and setting default arguments.
In terms of type checking, empty variables and data structures can be used to inform some control flow logic. For example, if presented with an empty data structure, perform “X” logic to populate that data structure.
With type checking and setting default arguments, there may be cases where the instance of an empty data structure should kick off some logic that allows a function call to succeed under unexpected conditions. For example, if you define a function that is called several times on different lists of floating point numbers and calculate the average, it will work as long as the function is provided with a list of numbers.
Conversely, if the function is provided with an empty list it will fail as it will be unable to calculate the average value of an empty list. Type checking and default arguments can then be used to try to calculate and return an average, and if it fails it returns a default value. This can help guarantee that code used for processing thousands of rows of data will always run successfully even under unexpected conditions.
Frequently Asked Questions
What is an empty variable in Python?
An empty or null variable in Python is a variable with no assigned value. Empty variables can be defined with the None or NaN (np.nan) keywords (like a = None or a = np.nan), while empty data structures like strings, lists or dictionaries can be defined by having no values included in the syntax (like a_string = “” or a_list = []). Empty variables tend to be used as placeholders in code, such as in the case of wanting to initialize a variable but not wanting it to be defined immediately or used in calculations.
Is the variable null or empty in Python?
In Python, a null variable and empty variable can refer to the same thing, which is a variable having no assigned value. However, a null variable may refer to a variable with no value (i.e. a = None), while an empty variable may refer to an empty data structure like a string, list or dictionary (i.e. a_string = “”, a_list = [], a_dict = {}).
How do you use empty () in Python?
Python has no built-in empty() function, but variables or functions can be assigned to be empty and have no value manually. For example, an empty variable is assigned like a = None, and an empty data structure such as a list is assigned like a_list = [].


