

The groupby() function in Pandas splits all the records from a data set into different categories or groups, offering flexibility to analyze the data by these groups. Pandas is a widely used Python library for data analytics projects, but it isn’t always easy to analyze the data and get valuable insights from it. Using groupby can help transform and aggregate data in Pandas to better understand it.
What Is Pandas Groupby?
Pandas groupby splits all the records from your data set into different categories or groups so that you can analyze the data by these groups. When you use the .groupby() function on any categorical column of DataFrame, it returns a GroupBy object, which you can use other methods on to group the data.
In the real world, you’ll usually work with large amounts of data and need to do similar operations over different groups of data. Pandas groupby() is handy in all those scenarios and gives you insights within a few seconds, making it extremely efficient and a must know function in data analysis.
In this article, I’ll explain five easy Pandas groupby tricks with examples to help you perform data analysis efficiently and ace your next data science interview. Before going further, let’s understand the basics.
How Does Pandas Groupby Work?
When you use the .groupby() function on any categorical column of DataFrame, it returns a GroupBy object. Then you can use different methods on this object and even aggregate other columns to get the summary view of the data set.
For example, you can use the .groupby() function on the column “Product_Category” in df to get the GroupBy object:
df_group = df.groupby("Product_Category")
type(df_group)
# Output
pandas.core.groupby.generic.DataFrameGroupByThe returned GroupBy object is nothing but a dictionary where keys are the unique groups in which records are split and values are the columns of each group that are not mentioned in groupby.
The GroupBy object holds the contents of the entire DataFrame but in a more structured form. And just like dictionaries there are several methods to get the required data efficiently.
Let’s start with importing your data into Pandas.
5 Pandas Groupby Methods to Know
For these examples, we’ll use a self-created “Dummy Sales Data” set, which you can get on my Github for free under MIT License.
Let’s import the data set into Pandas DataFrame df.
import pandas as pd
df = pd.read_csv("Dummy_Sales_Data_v1.csv")
df.head()
It’s a simple 9999 x 12 data set, which I created using Faker in Python. Now, let’s review some of the tricks you can do with groupby in Pandas.
1. Number of Groups
Once you split the data into different categories, it’s interesting to know how many different groups your data is now divided into.
The simple and common a nswer is to use the nunique() function on any column, which gives you a number of unique values in that column. As many unique values as there are in a column, the data will be divided into that many groups.
For example, you can see how many unique groups can be formed using Product_Category.
df.Product_Category.nunique()
-- Output
5However, when you already have a GroupBy object, you can directly use the method ngroups, which gives you the answer you are looking for:
df_group = df.groupby("Product_Category")
df_group.ngroups
-- Output
5Once you get the number of groups, you are still unaware about the size of each group. The next method gives you an idea of how large or small each group is.
2. Group Sizes
The number of rows in each group of a GroupBy object can be easily obtained using the function .size().
For instance, let’s say you want to see how many different rows are available in each group of “Product_Category”:
df.groupby("Product_Category").size()
The method simply counts the number of rows in each group. One may argue that the same results can be obtained using an aggregate function count():
df.groupby("Product_Category").count()
You can see the numbers in both results are the same. However, there’s a significant difference in the way they are calculated.
As per Pandas, the aggregate function .count() counts only the non-null values from each column, whereas .size() simply returns the number of rows available in each group irrespective of presence or absence of values.
You need to have a strong understanding of the difference between these two functions before using them. If you want to see how many non-null values are present in each column of each group, use .count(). Otherwise, use .size().
Once you get the size of each group, you might want to take a look at the first, last or the record at any random position in the data. The next method can be handy in that case.
3. Get First and Last
These functions return the first and last records after data is split into different groups. Rather than referencing the index, it gives out the first or last row appearing in all the groups.
For example, you can see the first record of in each group below:
df.groupby("Product_Category").first()
In a similar way, you can look at the last row in each group:
df.groupby("Product_Category").last()
.first() and .last() returned the first and the last row once all the rows were grouped under each Product_Category.
You can also extract a row at any other position, as well. For example, extracting the fourth row in each group is also possible using function .nth().
df.groupby("Product_Category").nth(3)Remember, indexing in Python starts with zero, therefore, when you say .nth(3), you are actually accessing the fourth row.
Logically, you can even get the first and last row using .nth() function. For example, you can get the first row in each group using .nth(0) and .first(), or the last row using .nth(-1) and .last().
So, why do these different functions even exist?
Although .first() and .nth(0) can be used to get the first row, there is a difference in handling NaN or missing values. .first() give you first non-null values in each column, whereas .nth(0) returns the first row of the group, no matter what the values are. Same with .last()
I recommend using .nth() over the other two functions to get the required row from a group, unless you are specifically looking for non-null records. But suppose, instead of retrieving only a first or a last row from the group, you might be curious to know the contents of a specific group. The next method quickly gives you that info.
4. Get Groups
The Pandas GroupBy method get_group() is used to select or extract only one group from the GroupBy object.
For example, suppose you want to see the contents of ‘Healthcare’ group:
df_group.get_group('Healthcare')
As you see, there is no change in the structure of the data set, and you still get all the records where the product category is ‘Healthcare’.
I have an interesting use-case for this method: Slicing a DataFrame.
Suppose, you want to select all the rows where “Product Category” is ‘Home’. A simple and widely used method is to use bracket notation “[ ]”:
df[df["Product_Category"]=='Home']Nothing is wrong with that, but you can get the exact same results with the method .get_group():
df_group = df.groupby("Product_Category")
df_group.get_group('Home')To take it a step further, when you compare the performance between these two methods and run them 1,000 times each, .get_group() is more time-efficient. In fact, slicing with .groupby() is four times faster than with logical comparison.
This method was about getting only a single group at a time by specifying the group name in the .get_group() method. But what if you want to have a look into the contents of all groups in one go?
Remember, GroupBy object is a dictionary.
So, you can iterate through it the same way as a dictionary — using key and value arguments.
Here is how you can take a peek into the contents of each group:
for name_of_group, contents_of_group in df_group:
print(name_of_group)
print(contents_of_group)
This will list out the name and contents of each group as shown above. Contents of only one group are visible in the picture, but in the Jupyter Notebook, you can see the same pattern for all the groups listed one below another.
It basically shows you the first and last five rows in each group just like .head() and .tail() methods of Pandas DataFrame.
The use of Pandas groupby is incomplete if you don’t aggregate the data. Let’s explore how you can use different aggregate functions on different columns in this last part.
5. Aggregate Multiple Columns
Applying an aggregate function on columns in each group is one of the most widely used practices to obtain a summary structure for further statistical analysis.
And that is where Pandas groupby with aggregate functions is very useful. With groupby, you can split a data set into groups based on a single column or multiple columns and then apply aggregate functions on the remaining numerical columns.
Let’s continue with the same example. After grouping the data by product_category, suppose you want to see what the average unit price and quantity in each product category is.
All you need to do is refer to these columns in the GroupBy object using square brackets and apply the aggregate function .mean() on them:
#Create a groupby object
df_group = df.groupby("Product_Category")
#Select only required columns
df_columns = df_group[["UnitPrice(USD)","Quantity"]]
#Apply aggregate function
df_columns.mean()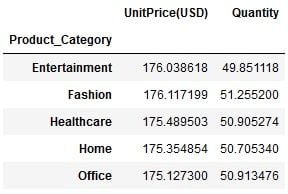
In this way you can get the average unit price and quantity in each group. You can add more columns, as per your requirement, and apply other aggregate functions such as .min(), .max(), .count(), .median(), .std() and so on.
Please note that the code is split into three lines just for your understanding. However, the same output can be achieved in just one line of code:
df.groupby("Product_Category")[["UnitPrice(USD)","Quantity"]].mean()While it looks easy and fancy to write a one-liner like the above, you should always keep in mind the PEP-8 guidelines about the number of characters in one line. Moving ahead, you can apply multiple aggregate functions on the same column using the GroupBy method .aggregate(). Simply provide the list of function names which you want to apply on a column.
For instance, suppose you want to get the maximum, minimum, summation and average of Quantity in each product category. The aggregate functions would be min, max, sum and mean:
df.groupby("Product_Category")[["Quantity"]].aggregate([min,
max,
sum,
'mean'])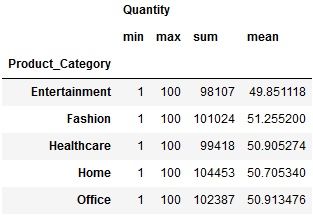
You get all the required statistics about the Quantity in each group. But wait, did you notice something in the list of functions you provided in the .aggregate().
All the functions, such as sum, min and max, were written directly, but the function mean was written as a string, i.e. in single quotes like this ‘mean’. But why was it written like a string?
As per Pandas, the function passed to .aggregate() must be the function which works when passed a DataFrame or passed to DataFrame.apply().
In short, when you mention ‘mean’, .aggregate() searches for a function mean belonging to pd.Series, i.e. pd.Series.mean(). Whereas, if you mention mean (without quotes), .aggregate() will search for a function named mean in default Python, which is unavailable and will throw a NameError exception.
Further, using .groupby() you can apply different aggregate functions on different columns. In that case you need to pass a dictionary to .aggregate(), where keys will be column names and values will be the aggregate function that you want to apply.
For example, suppose you want to get the total orders and average quantity in each product category. The dictionary you will be passing to .aggregate() will be:
{‘OrderID’:’count’, ’Quantity’:’mean’}And you can get the desired output by simply passing this dictionary:
function_dictionary = {'OrderID':'count','Quantity':'mean'}
df.groupby("Product_Category").aggregate(function_dictionary)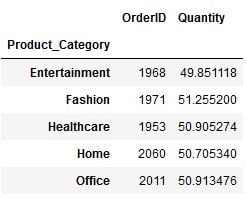
In this way, you can apply multiple functions on multiple columns as needed.
The Pandas .groupby() and GroupBy object are even more flexible. There’s a way to get the basic statistical summary split by each group with a single function: describe(). All you need to do is specify a required column and apply .describe() on it:
df.groupby("Product_Category")[["Quantity"]].describe()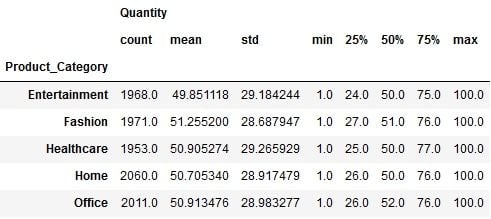
In this way, you can get a complete descriptive statistics summary for Quantity in each product category. As you can see, it contains the result of individual functions such as count, mean, std, min, max and median.
And that’s it. I hope you gained valuable insights into Pandas .groupby() and its flexibility from this article. You can also review the examples in my notebook.
Frequently Asked Questions
What does the groupby() method in pandas do?
The groupby() method in Pandas splits data from a DataFrame into groups or categories and can be used to apply a function over these groups. When using groupby() on any categorical columns in a DataFrame, it returns a GroupBy object based on the specified value(s).
Is pandas groupby slow?
groupby() operations in Pandas can be slow due to large data sets, complex aggregations, the data type of columns or types of functions applied.
How to get value from groupby pandas?
groupby() in Pandas can be used to transform or gather insights about a data set, with the ability to aggregate groups, extract one group, find the number of groups, find the size of groups in a DataFrame and more.


