

Many applications like information retrieval, personalization, document categorization, image processing, and so on, rely on the computation of similarity or dissimilarity between items. Two items are considered similar if the distance between them is small, and vice versa.
So, how do we calculate this distance? Well, each data object (item) can be thought of as an n-dimensional vector where the dimensions are the attributes (features) in the data. The vector representations thereby make it possible to compute the distance between pairs using the standard vector-based similarity measures like the Manhattan distance or Euclidean distance, to name two. During such calculations, norms come up. Vector norms occupy an important space in the context of machine learning, so in this article, we’ll first work to understand the basics of a norm and its properties and then go over some of the most common vector norms.
Common Vector Norms in Machine Learning
- L¹ / Manhattan Norm
- L² / Euclidean Norm
- L∞ Norm
- Lᵖ Norm
What Is a Norm?
A norm is a way to measure the size of a vector, a matrix, or a tensor. In other words, norms are a class of functions that enable us to quantify the magnitude of a vector. For instance, the norm of a vector X drawn below is a measure of its length from origin.

The subject of norms comes up on many occasions in the context of machine learning:
- When defining loss functions, i.e., the distance between the actual and predicted values
- As a regularization method in machine learning, e.g., ridge and lasso regularization methods.
- Even algorithms like support vector machine (SVM) use the concept of the norm to calculate the distance between the discriminant and each support-vector.
How Do We Represent Norms?
The norm of any vector X is denoted by a double bar around it and is written as follows:
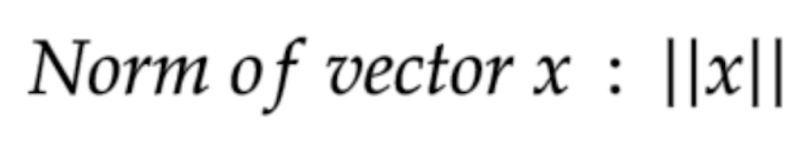
What Are the Properties of a Norm?
Consider two vectors X and Y, having the same size and scalar. A function is considered a norm only if it satisfies the following properties:
What Are the Properties of a Norm?
- Non-negativity: It should always be non-negative.
- Definiteness: It is zero if and only if the vector is zero, i.e., zero vector.
- Triangle inequality: The norm of a sum of two vectors is no more than the sum of their norms (∥X + Y∥ ≤ ∥X∥ + ∥Y∥).
- Homogeneity: Multiplying a vector by a real scalar multiplies the norm of the vector by the absolute value of the scalar (for any real scalar α, ∥αX∥ = 'α' ∥X∥).
Let’s see these qualities represented mathematically.
Non-Negativity

Definiteness

Triangle Inequality

Homogeneity

Any real value function of a vector that satisfies the above four properties is called a norm.
What Are Some Standard Norms?
A lot of functions can be defined that satisfy the properties above. Consider a two-dimensional column vector X as follows,

We can now calculate some standard norms for X, starting with the L¹ norm.
What Is the L¹ Norm / Manhattan Norm?
The L¹ norm is defined as the sum of the absolute values of the components of a given vector. Since we have a vector X with only two components, the L¹ norm of x can be written as:

Notice the representation with one written as a subscript. This norm is also called the Manhattan or the taxicab norm, inspired by the burrough of Manhattan in New York. The L¹ norm is typically the distance a taxi will have to drive from the origin to point x.
Mathematical Notation
The L¹ norm can be mathematically written as:

What Are the Properties of the L1/Manhattan Norm?
- The L¹ norm is used in situations when it is helpful to distinguish between zero and non-zero values.
- The L¹ norm increases proportionally with the components of the vector.
- It is used in Lasso (Least Absolute Shrinkage and Selection Operator) regression, which involves adding the L¹ norm of the coefficient as a penalty term to the loss function.
What Is the L² Norm / Euclidean Norm?
L² is the most commonly used norm and the one most encountered in real life. The L² norm measures the shortest distance from the origin. It is defined as the root of the sum of the squares of the components of the vector. So, for our given vector X, the L² norm would be:

The L² norm is so common that it is sometimes also denoted without any subscript:

The L² norm is also known as the Euclidean norm after the famous Greek mathematician, often referred to as the founder of geometry. The Euclidean norm essentially means we are referring to the Euclidean distance.
Mathematical Notation
The L² norm can be mathematically written as:

What Are the Properties of the L2 Norm?
- The L² norm is the most commonly used one in machine learning.
- Since it entails squaring of each component of the vector, it is not robust to outliers.
- Since the L² norm squares each component, very small components become even smaller. For example, (0.1)² = 0.01.
- It is used in ridge regression, which involves adding the coefficient of the L² norm as a penalty term to the loss function.
What Is the L∞/Max Norm?
The L∞ norm is defined as the absolute value of the largest component of the vector, or the maximum absolute value among the vector’s components. Therefore, it is also called the max norm. So, continuing with our example of a 2D vector X having two components (i.e., x₁ and x₂, where x₂ > x₁), the L∞ norm would simply be the absolute value of x₂.

Mathematical Notation
The L∞ norm can be mathematically written as:

What Are the Properties of the Max Norm?
- The L∞ norm simplifies to the absolute value of the largest element in the vector.
What Is the Lᵖ Norm?
We can now generalize to the idea of what is known as the p-norm. In a way, we can derive all other norms from the p-norm by varying the values of p. That is to say, if you substitute the value of p with one, two, and ∞ respectively in the formula below, you’ll obtain L¹, L², and L∞ norms.
Mathematical Notation
The Lᵖ norm can be mathematically written as:

An important point to remember here is that each of the norms above fulfills the properties of the norms mentioned in the beginning.
What happens when p equals zero?
When this happens, we might want to call the value L⁰ “norm” (however, it’s not technically a norm because it doesn’t satisfy the homogeneity property). The so-called “L⁰ norm” is useful when we want to know the number of non-zero components in a vector. This means sparsity can be modeled via the L⁰ “norm.”

Sparsity is an important concept in machine learning, as it helps to improve robustness and prevent overfitting.
Vector Norms Summed Up
This article looked at the concept of a vector norm, its properties, and some commonly used norms that we encounter in machine learning.
You may also find these resources on linear algebra useful for understanding vector norms further.
Frequently Asked Questions
What is a vector norm?
A vector norm is a function that measures the size or magnitude of a vector by quantifying its length from the origin. To be a vector norm, a function must satisfy the following properties: non-negativity, definiteness, triangle inequality and homogeneity.
Why are vector norms important in machine learning?
Vector norms are important in machine learning because they are used to calculate distances between data points, define loss functions, apply regularization techniques and are involved in algorithms like support vector machine (SVM).


