

My tryst with the Pandas library continues. Of late, I have been trying to look more deeply into this library and consolidating some of its features in bite-sized articles. I have written articles on reducing memory usage while working with Pandas, converting XML files into a pandas data frame easily, getting started with time series in Pandas, and many more.
In this article, I’ll touch upon a very useful aspect of data analysis: sorting. We’ll begin with a brief introduction and then quickly jump on some ways to perform sorting efficiently in Pandas.
How to Sort Data Frames in Pandas
- Sorting on a single column.
- Sorting on multiple columns.
- Sorting by multiple columns with different sort orders.
- Sorting by index.
- Ignore the index while sorting.
- Choosing the sorting algorithm.
- Sorting by column names.
- Performing operations in place.
- Handling missing values.
- Apply the key function to the values before sorting.
Common Data Sorting Algorithms
If you’re an Excel user, one of the first things that you’ll do when you open a spreadsheet is to sort the items in ascending or descending order based on a column (or columns). Technically, sorting is a way of ordering elements based on their ranks. There is complete documentation dedicated to various sorting algorithms in the programming field. Here are some commonly used sorting algorithms.
These different sorting algorithms each have different underlying principles for sorting data. For instance, in bubble sort, the algorithm compares an element to its neighbor and swaps them in the desired order. On the other hand, merge sort is based on the divide-and-conquer technique. In selection sort, the algorithm repeatedly selects the minimum (or maximum) element from the unsorted portion and places it at the beginning (or end) of the sorted portion. Explaining the intricacies of all these algorithms is beyond the scope of this article, but if it piques your interest, here is a great article that explains the concept with great visualizations.
How to Sort in Pandas
Let’s now explore how we can perform sorting in Pandas. For this, I’ll use a very interesting data set consisting of a list of the top 100 most-starred GitHub repositories, which is publicly available on Kaggle. The data set is updated daily and consists of other attributes like several forks, project description, language, and even project description. Let’s load the data set and look at its structure. As a note, you can follow along using this notebook.
df = pd.read_csv('Most starred Github Repositories.csv')
df.head()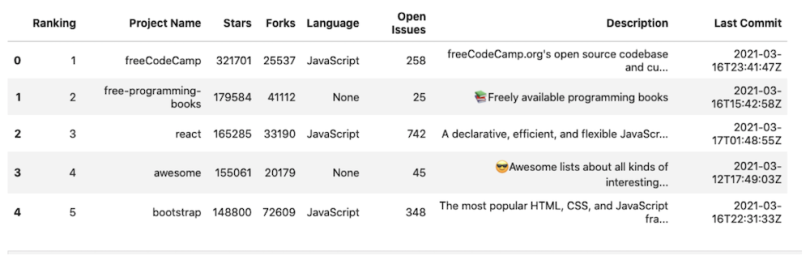
Let’s quickly go over the various columns of the data set:
- Project Name: Name of the repository in GitHub
- Stars: A bookmark or display of appreciation for a repository.
- Forks: A copy of a repository that you manage.
- Language: The main programming languages used in the project
- Open Issues: Suggested improvements, tasks, or questions related to the repository. The issues that haven’t been resolved are labeled as open issues.
- Description: A paragraph detailing the purpose of the project.
- Last Commit: A commit, or revision is an individual change to a file or set of files. This field stores the date and time of the last commit.
All these definitions have been taken from the GitHub glossary.
The current data set is ordered by the number of stars, i.e., the project with the maximum number of stars comes first, and so on. Pandas supports three kinds of sorting: sorting by index labels, sorting by column values, and sorting by a combination of both. Let’s now look at the different ways of sorting this data set with some examples:
1. Sorting on a Single Column
The function used for sorting in Pandas is called DataFrame.sort_values(). It uses the Quicksort algorithm by default, meaning it sorts a data frame by its column or row values in ascending order. Let’s sort the data set by the Forks column.
forks = df.sort_values(by='Forks',ascending=False)
forks.head(10)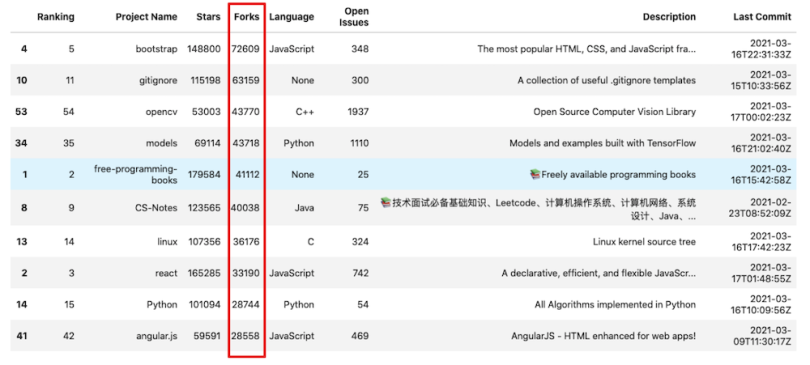
The function dataframe.sort_values comes with a lot of parameters. We will touch on a few important ones as we advance through this article. In the above example, we have encountered two of them:
by: The optional by parameter is used to specify the column(s) that are used to determine the sorted order.ascending: This specifies whether to sort the data frame in ascending or descending order. The default value is ascending. To sort in descending order, we need to specify ascending=False.
2. Sorting on Multiple Columns
Pandas also makes it possible to sort the data set on multiple columns. Simply pass in the list of the desired columns names in the sort_values function as follows:
df.sort_values(by=['Open Issues','Stars']).head(10)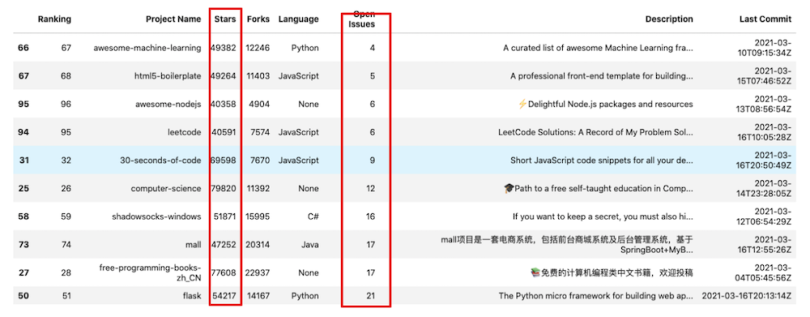
In the example above, we have sorted the data frame based on the number of open issues and the number of stars a project has. Note that by default, the sorting has been done in ascending order.
3. Sorting by Multiple Columns With Different Sort Orders
When sorting by multiple columns, it is also possible to pass in different sort orders for different columns.
df.sort_values(by=['Open Issues', 'Stars'],
ascending=[True, False]).head(10)
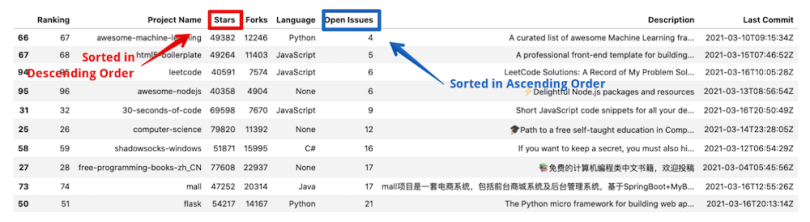
In the above examples, the data frame will be first sorted on the Open Issues column in ascending order and then on the Stars column in descending order.
4. Sorting by Index
Another way of sorting a data frame would be by its index. In section one, we created a data frame named Forks. This is just another version of the original data frame, which has been sorted on the Forks columns. The data frame appears like this:

As is evident, the index is unsorted. We can sort it by using the dataframe.sort_index() function.
forks.sort_index()
Alternatively, you can sort the index in descending order by passing in the ascending=False the argument in the function above.
5. Ignore the Index While Sorting
Setting ignore_index=True resets the index of the sorted DataFrame to a default integer range. It doesn't affect the sort itself, just the resulting index labels. This results in an index labeled from zero to n-1 where n refers to the number of observations.
df.sort_values(by='Forks',ascending=False, ignore_index=True).head()
If ignore_index was not set to True (or default), then the resulting sorted data frame would have been:

6. Choosing the Sorting Algorithm
We touched upon the topic of different sorting algorithms in the beginning. By default, sort_values uses the quicksort algorithm. We can choose between quicksort, mergesort, and heapsort algorithms using the kind parameter, however. Remember that this option is only applied when sorting on a single column or label.
df.sort_values(by='Forks', kind='mergesort')
7. Sorting by Column Names
Additionally, we can also sort the data frame using the column names instead of the rows using the sort_index() function. For this, we need to set the axis parameter to one. This is because axis=1 refers to columns, while axis=0 is for rows.
df.sort_index(axis=1).head(5)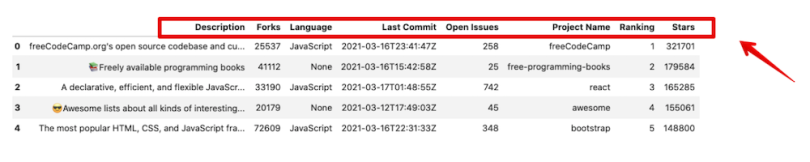
The columns above have been sorted in ascending alphabetical order. By setting ascending=False, we can sort in descending order also.
8. Performing Operations in Place
By setting the inplace parameter to true, all the sorting operations are done in place. This means that the existing data frame gets modified. When inplace = False, the operations take place on a copy of the data frame, which is then returned. The original data frame remains unchanged.
df.sort_values(by='Forks', inplace=True)As a note, in-place operations can cause side effects during chained operations. Best practice in modern Pandas discourages inplace=True in favor of reassignment, but it remains an option if needed.
9. Handling Missing Values
Data usually contains null values. Using the na_position as first or last, in sort_values() function, we can choose to puts NaNs at the beginning or at the end.
df.sort_values(by='Forks', na_position='first') #NaN placed first
df.sort_values(by='Forks', na_position='last') #NaN placed in the end
10. Apply the Key Function to the Values Before Sorting
We can also apply a key function to the values before sorting. The function expects a series and returns a series with the same shape as the input. It will be applied to each column independently. In the example below, we first convert the column Project Name in lower case and then sort the data frame on this column
df.sort_values(by='Project Name',key=lambda col: col.str.lower())[:5]
As a note, key= works only in Pandas 1.1.0 and later versions.
Confidently Sort Data in Pandas
In this article, we looked at the different ways of sorting a data frame using the Pandas library. We looked at the usage of both sort_values() as well as the sort_index() functions along with their parameters. The official documentation is an excellent resource if you are thinking of going deeper into the details.
Frequently Asked Questions
What is the difference between sort_values() and sort_index() in Pandas?
In Pandas, sort_values() sorts a DataFrame by the values in one or more columns, while sort_index() sorts based on index labels.
Can I sort by multiple columns with different sort orders in Pandas?
Yes, you can do this in Pandas by passing a list to both the by and ascending parameters in sort_values(). For example: ascending=[True, False].
How do I reset the index after sorting a Pandas DataFrame?
In Pandas, use the ignore_index=True parameter in sort_values() to reset the index to a default range after sorting a DataFrame.


