
: A Step-by-Step Explanation")
Principal component analysis (PCA) is a dimensionality reduction technique that transforms a data set into a set of orthogonal components — called principal components — which capture the maximum variance in the data. PCA simplifies complex data sets while preserving their most important structures.
What Is Principal Component Analysis?
Principal component analysis (PCA) is a dimensionality reduction and machine learning method used to simplify a large data set into a smaller set while still maintaining significant patterns and trends.
PCA is a widely covered machine learning method on the web. Below we cover how principal component analysis works in a simple step-by-step way, so everyone can understand it and make use of it — even those without a strong mathematical background.
What Is Principal Component Analysis?
Principal component analysis, or PCA, is a dimensionality reduction method that is often used to reduce the dimensionality of large data sets, by transforming a large set of variables into a smaller one that still contains most of the information in the large set.
Reducing the number of variables of a data set naturally comes at the expense of accuracy, but the trick in dimensionality reduction is to trade a little accuracy for simplicity. Because smaller data sets are easier to explore and visualize, and thus make analyzing data points much easier and faster for machine learning algorithms without extraneous variables to process.
So, to sum up, the idea of PCA is simple: reduce the number of variables of a data set, while preserving as much information as possible.
What Are Principal Components?
Principal components are new variables that are constructed as linear combinations or mixtures of the initial variables. These combinations are done in such a way that the new variables (i.e., principal components) are uncorrelated and most of the information within the initial variables is squeezed or compressed into the first components. So, the idea is 10-dimensional data gives you 10 principal components, but PCA tries to put maximum possible information in the first component, then maximum remaining information in the second and so on, until having something like shown in the scree plot below.
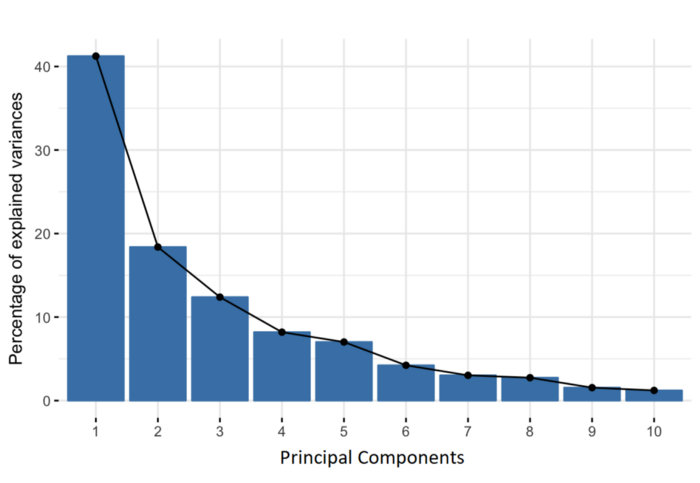
Organizing information in principal components this way will allow you to reduce dimensionality without losing much information, and this by discarding the components with low information and considering the remaining components as your new variables.
An important thing to realize here is that the principal components are less interpretable and don’t have any real meaning since they are constructed as linear combinations of the initial variables.
Geometrically speaking, principal components represent the directions of the data that explain a maximal amount of variance, that is to say, the lines that capture most information of the data. The relationship between variance and information here, is that, the larger the variance carried by a line, the larger the dispersion of the data points along it, and the larger the dispersion along a line, the more information it has. To put all this simply, just think of principal components as new axes that provide the best angle to see and evaluate the data, so that the differences between the observations are better visible.
How PCA Constructs the Principal Components
As there are as many principal components as there are variables in the data, principal components are constructed in such a manner that the first principal component accounts for the largest possible variance in the data set.
For example, let’s assume that the scatter plot of our data set is as shown below, can we guess the first principal component ? Yes, it’s approximately the line that matches the purple marks because it goes through the origin and it’s the line in which the projection of the points (red dots) is the most spread out. Or mathematically speaking, it’s the line that maximizes the variance (the average of the squared distances from the projected points (red dots) to the origin).
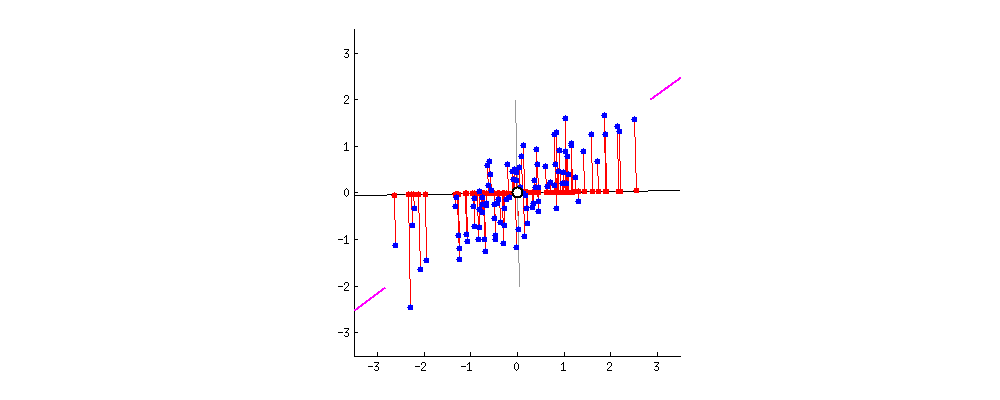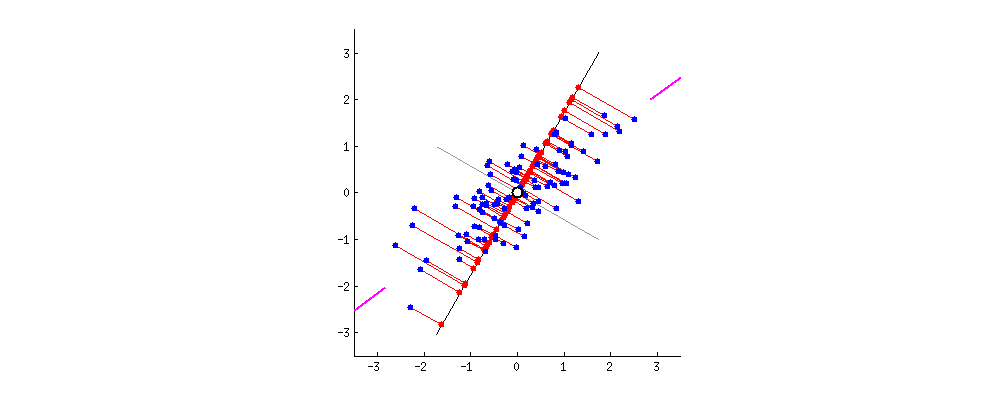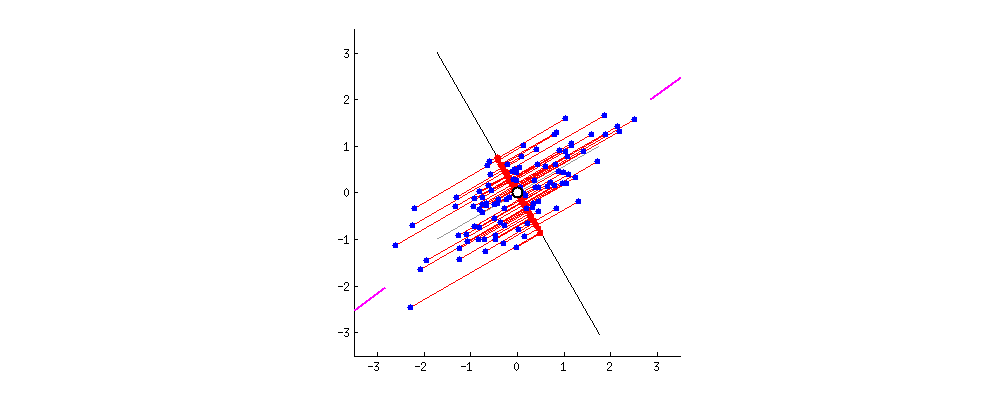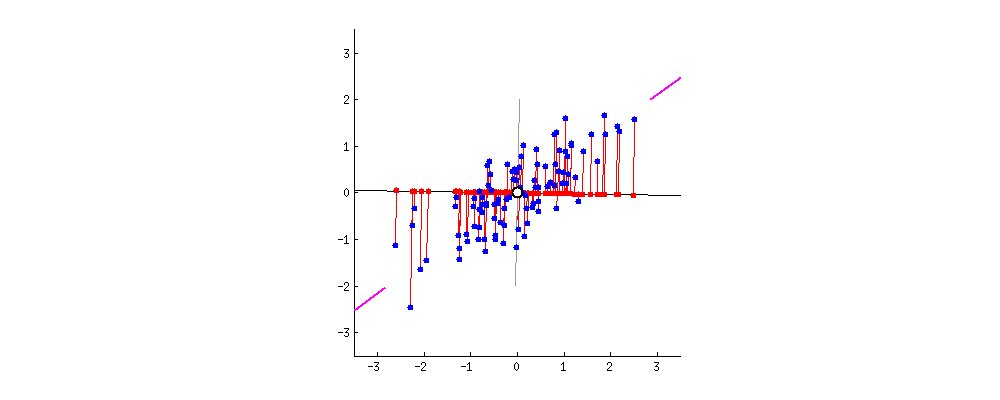
The second principal component is calculated in the same way, with the condition that it is uncorrelated with (i.e., perpendicular to) the first principal component and that it accounts for the next highest variance.
This continues until a total of p principal components have been calculated, equal to the original number of variables.
How Principal Component Analysis Works: 5 Steps
Principal component analysis can be broken down into five steps. I’ll go through each step, providing logical explanations of what PCA is doing and simplifying mathematical concepts such as standardization, covariance, eigenvectors and eigenvalues without focusing on how to compute them.
Step 1: Standardization and Centering Data
The aim of this step is to standardize the range of the continuous initial variables so that each one of them contributes equally to the analysis.
More specifically, the reason why it is critical to perform standardization prior to PCA, is that the latter is quite sensitive regarding the variances of the initial variables. That is, if there are large differences between the ranges of initial variables, those variables with larger ranges will dominate over those with small ranges (for example, a variable that ranges between 0 and 100 will dominate over a variable that ranges between 0 and 1), which will lead to biased results. So, transforming the data to comparable scales can prevent this problem.
Mathematically, this can be done by subtracting the mean and dividing by the standard deviation for each value of each variable.
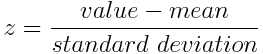
Once the standardization is done, all the variables will be transformed to the same scale.
Step 2: Covariance Matrix Computation
The aim of this step is to understand how the variables of the input data set are varying from the mean with respect to each other, or in other words, to see if there is any relationship between them. Because sometimes, variables are highly correlated in such a way that they contain redundant information. So, in order to identify these correlations, we compute the covariance matrix.
The covariance matrix is a p × p symmetric matrix (where p is the number of dimensions) that has as entries the covariances associated with all possible pairs of the initial variables. For example, for a 3-dimensional data set with 3 variables x, y, and z, the covariance matrix is a 3×3 data matrix of this from:

Since the covariance of a variable with itself is its variance (Cov(a,a)=Var(a)), in the main diagonal (Top left to bottom right) we actually have the variances of each initial variable. And since the covariance is commutative (Cov(a,b)=Cov(b,a)), the entries of the covariance matrix are symmetric with respect to the main diagonal, which means that the upper and the lower triangular portions are equal.
What do the covariances that we have as entries of the matrix tell us about the correlations between the variables?
It’s actually the sign of the covariance that matters:
- If positive then: the two variables increase or decrease together (correlated)
- If negative then: one increases when the other decreases (Inversely correlated)
Now that we know that the covariance matrix is not more than a table that summarizes the correlations between all the possible pairs of variables, let’s move to the next step.
Step 3: Eigen Decomposition and Identifying Principal Components
Eigenvectors and eigenvalues are the linear algebra concepts that we need to compute from the covariance matrix in order to determine the principal components of the data.
What you first need to know about eigenvectors and eigenvalues is that they always come in pairs, so that every eigenvector has an eigenvalue. Also, their number is equal to the number of dimensions of the data. For example, for a 3-dimensional data set, there are 3 variables, therefore there are 3 eigenvectors with 3 corresponding eigenvalues.
It is eigenvectors and eigenvalues who are behind all the magic of principal components because the eigenvectors of the Covariance matrix are actually the directions of the axes where there is the most variance (most information) and that we call Principal Components. And eigenvalues are simply the coefficients attached to eigenvectors, which give the amount of variance carried in each Principal Component.
By ranking your eigenvectors in order of their eigenvalues, highest to lowest, you get the principal components in order of significance.
Principal Component Analysis Example:
Let’s suppose that our data set is 2-dimensional with 2 variables x,y and that the eigenvectors and eigenvalues of the covariance matrix are as follows:
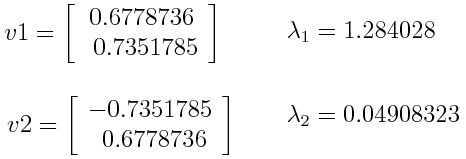
If we rank the eigenvalues in descending order, we get λ1>λ2, which means that the eigenvector that corresponds to the first principal component (PC1) is v1 and the one that corresponds to the second principal component (PC2) is v2.
After having the principal components, to compute the percentage of variance (information) accounted for by each component, we divide the eigenvalue of each component by the sum of eigenvalues. If we apply this on the example above, we find that PC1 and PC2 carry respectively 96 percent and 4 percent of the variance of the data.
Step 4: Feature Selection and Creating a Feature Vector
As we saw in the previous step, computing the eigenvectors and ordering them by their eigenvalues in descending order, allow us to find the principal components in order of significance. In this step, what we do is, to choose whether to keep all these components or discard those of lesser significance (of low eigenvalues), and form with the remaining ones a matrix of vectors that we call Feature vector.
So, the feature vector is simply a matrix that has as columns the eigenvectors of the components that we decide to keep. This makes it the first step towards dimensionality reduction, because if we choose to keep only p eigenvectors (components) out of n, the final data set will have only p dimensions.
Principal Component Analysis Example:
Continuing with the example from the previous step, we can either form a feature vector with both of the eigenvectors v1 and v2:

Or discard the eigenvector v2, which is the one of lesser significance, and form a feature vector with v1 only:

Discarding the eigenvector v2 will reduce dimensionality by 1, and will consequently cause a loss of information in the final data set. But given that v2 was carrying only 4 percent of the information, the loss will be therefore not important and we will still have 96 percent of the information that is carried by v1.
So, as we saw in the example, it’s up to you to choose whether to keep all the components or discard the ones of lesser significance, depending on what you are looking for. Because if you just want to describe your data in terms of new variables (principal components) that are uncorrelated without seeking to reduce dimensionality, leaving out lesser significant components is not needed.
Step 5: Data Projection
In the previous steps, apart from standardization, you do not make any changes on the data, you just select the principal components and form the feature vector, but the input data set remains always in terms of the original axes (i.e., in terms of the initial variables).
In this step, which is the last one, the aim is to use the feature vector formed using the eigenvectors of the covariance matrix, to reorient the data from the original axes to the ones represented by the principal components (hence the name Principal Components Analysis). This can be done by multiplying the transpose of the original data set by the transpose of the feature vector.
Principal Component Analysis Variants and Extensions
While classical principal component analysis assumes linearity and orthogonal components, real-world data doesn’t always follow these assumptions. This has led to various types of PCA extensions being developed to address specific data challenges.
Here are some popular PCA variants to know:
1. Kernel PCA (KPCA)
Kernel PCA extends classical PCA to capture non-linear structures in data. It maps the input data into a high-dimensional feature space using a kernel function, and then performs PCA in this new space. KPCA allows users to uncover complex manifolds in data that linear PCA cannot detect, making it useful in image processing, pattern recognition and non-linear clustering.
Key advantage: Captures non-linear relationships between features.
2. Sparse PCA (SPCA)
Sparse PCA applies sparse constraints (limits to the number active parameters) to principal components, resulting in eigenvectors or other loadings to contain many zeroes. This makes principal components more interpretable and robust in high-dimensional scenarios where the number of features is greater than the number of samples, such as in text mining or genomics.
Key advantage: Creates interpretable components and mitigates overfitting in high-dimensional data.
3. Robust PCA (RPCA)
Robust PCA addresses the sensitivity of classical PCA to outliers by decomposing the data matrix into a low-rank matrix and a sparse matrix that captures the anomalies. This makes RCPA effective for tasks such as fraud detection or background subtraction in video sequences.
Key advantage: Handles outliers and noise by separating them from the true low-dimensional structure.
4. Incremental PCA (IPCA)
Incremental PCA is designed for scenarios where a data set is too large to fit into computer memory. As such, IPCA updates the principal components incrementally as new data arrives, making it suitable for data streaming or real-time applications.
Key advantage: Scalable to large data sets and suitable for real-time data tasks.
5. Probabilistic PCA (PPCA)
Probabilistic PCA reformulates PCA as a probabilistic latent variable model, which assumes Gaussian noise and enables full Bayesian treatment. PPCA facilitates principled handling of missing data and uncertainty estimation of data, making it useful in machine learning and statistical modeling.
Key advantage: Provides a probabilistic interpretation of data and supports inference under uncertainty.
Applications of Principal Component Analysis
Principal component analysis has applications across data science, machine learning and engineering fields, helping improve data analysis, visualization and computing performance in various tasks.
Here are some of its most common applications:
1. Data Visualization
PCA reduces high-dimensional data to a two-dimensional or three-dimensional space for easier visualization, helping to reveal data trends, clusters or outliers.
2. Preprocessing for Machine Learning
PCA is often used before applying machine learning algorithms in order to reduce dimensionality, speed up training and improve model generalization.
3. Feature Extraction
PCA transforms correlated data features into a smaller set of uncorrelated components, which can help improve model performance and interpretability.
4. Data Compression
PCA reduces data storage needs by representing data with fewer dimensions while preserving most of its variability, making it effective in image and signal compression.
5. Noise Reduction
By filtering out low-variance components, PCA can reduce noise in data for applications like image and audio.
History of Principal Component Analysis
Principal component analysis was first introduced by Karl Pearson in 1901 as a method for identifying the principal axes of variation in multidimensional data, which laid the foundation for modern multivariate statistics. Pearson’s work came about from the need to reduce the dimensionality of complex data, specifically biological and anthropometric data.
In 1933, Harold Hotelling further formalized PCA in the context of statistical analysis and psychometrics. In this context, he introduced the concept of principal components as linear combinations of original variables, emphasizing their use in simplifying data structures and reducing data redundancy.
PCA has since become a foundational tool in statistics, with applications expanding to cover large data sets in the wake of computing. Today, PCA is used in various fields — from data science and machine learning to healthcare and finance — and remains a staple of dimensionality reduction and exploratory data analysis.
Frequently Asked Questions
What does a PCA plot tell you?
A principal component analysis (PCA) plot shows similarities between groups of samples in a data set. Each point on a PCA plot represents a correlation between an initial variable and the first and second principal components.
Why is PCA used in machine learning?
PCA reduces the number of variables or features in a data set while still preserving the most important information like major trends or patterns. This reduction can decrease the time needed to train a machine learning model and helps avoid overfitting in a model.


