

The Sigmoid function takes a number as input and returns a new value between 0 and 1.
The Sigmoid function is often used as an activation function in the various layers of a neural network. It determines if a node should be activated or not, and thereby, if the node should contribute to the calculations of the network or not.
I recently learned how to implement my own neural network from scratch. This was valuable for my understanding of machine learning and especially the inner workings of neural networks.
What Is the Derivative of the Sigmoid Function?
The derivative of the Sigmoid function is calculated as the Sigmoid function multiplied by one minus the Sigmoid function. It’s used during the backpropagation step of a neural network in order to adjust weights of a model either up or down.
The network that I learned to implement used the Sigmoid function. However, there was very little information around how the math surrounding the Sigmoid function works. That left me scratching my head, and as a person that wants to understand everything about a tool that I use, I had to dive into the math and find out what was going on.
In this post I will walk you through it step by step, and attempt to make it as easy to understand as possible.
Why Is the Sigmoid Function Used in Neural Networks?
The training phase of a neural network consists of two parts.
Feedforward is the process where data flows through the neural network from the input node towards the output node. In other words, this is where the network is trying to make predictions.
These predictions are then evaluated by comparing them to the actual values. The error can be found as the difference between the two values.
error = actual_value - predicted_value
Backpropagation takes place next, and this is where the “learning” or “adjustment” takes place in the neural network. Now, the error value flows back through the network in the opposite direction as before, and it is then used in combination with the derivative of the Sigmoid function in order to adjust the weights of all the nodes throughout the layers of the network.
What Does the Derivative of the Sigmoid Function Do in a Neural Network?
The derivative of the Sigmoid function allows you to perform the adjustments via gradient descent. The derivative of a function will give us the angle/slope of the graph that the function describes. This value will let the network know whether to increase or decrease the value of the individual weights in the layers of the network. During backpropagation, the derivative of an activation function is calculated many times, and this is where the Sigmoid function really shines.
The Sigmoid function looks like this:
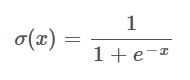
And the derivative of the Sigmoid function is simply:
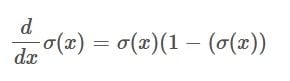
In other words, the derivative of the Sigmoid function is the Sigmoid function itself multiplied by one minus the Sigmoid function.
The cool thing is that during backpropagation we have already calculated all the parts of the derivative of the Sigmoid function during the feedforward step, and there is therefore nothing new to calculate. Instead, we can simply apply the result of the Sigmoid function in the two spots of the derivative equation.
This saves the neural network from doing a lot of computations, which is otherwise required when using other activation functions. Being able to avoid so many additional computations is one of the things that makes the Sigmoid function great for neural networks.
Now, to the part that I was struggling to understand: How come the derivative of the Sigmoid function is the Sigmoid function itself multiplied by one minus the Sigmoid function?
How to Calculate the Derivative of the Sigmoid Function
In order to obtain the derivative of the Sigmoid function, we are going to need two rules, the chain rule and the quotient rule.
We will go through the calculations step by step, and I will point out when the rules are being applied.
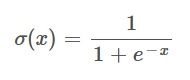
Since the Sigmoid function is a fraction, and both the numerator and the denominator are differentiable, we can use the quotient rule to find the derivative of the whole function.
The quotient rule says that we can get the derivative of a function in the following way:
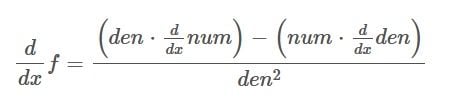
den is short for denominator, and num is short for numerator.
Taking the numerator and denominator of the Sigmoid function, along with the derivative of the numerator and the derivative of the denominator and placing them into the above function we get:
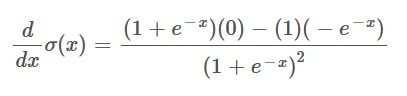
The derivative of the numerator becomes 0 as the numerator is a constant.
The derivative of the denominator becomes:
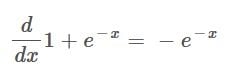
This is where the chain rule is used, and I think this step might require a bit more explanation and a detailed walkthrough.
1. Using the Chain Rule to Find the Derivative of the Outer Function
The chain rule tells us that the derivative of a compositional function, a function with another function inside of it, is calculated in the following way:
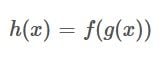
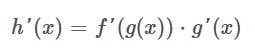
This can be read as: The derivative of the compositional function is the derivative of the outer function f, containing the inner function g, multiplied by the derivative of the inner function.
In this case:
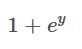
This is considered to be the outer function, y is representing the inner function. And the inner function is then -x. When applying the chain rule on the denominator of the Sigmoid function we get the following equation:
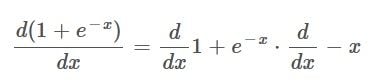
If we begin by finding the derivative of the outer function, then the 1 becomes 0 and the derivative of e to the power of something just stays the same, as seen in the equation below:
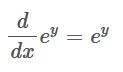
2. Calculate the Derivative of the Inner Function
At this point, we have the derivative of the outer function, and the next step is to find the derivative of the inner function. The inner function was simply -x. The derivative of that becomes -1.
Putting all that together we get:
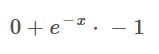
This expression can then be simplified to:
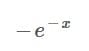
3. Reduce the Expression
This was the first difficult part, and we can now return to the quotient rule with our understanding of how we got the derivative of the denominator.
Remember that this is where we left off:
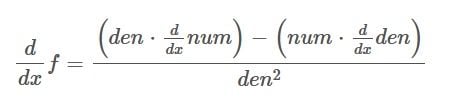
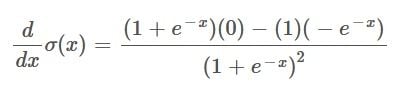
We can now reduce the above expression by removing the part that is multiplied by 0. Which then gives us the following:
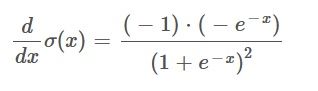
Next, we can multiply the two parentheses in the numerator which gives us:
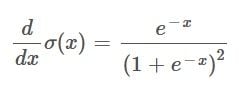
4. Split the Function Into Two Fractions
We are pretty close now, however the function is not quite in the desired form yet. In order to get there we first need to use a small trick where we add and subtract a one in the numerator. Doing that has no actual effect on the result of the equation, however it makes the following step possible. Like so:
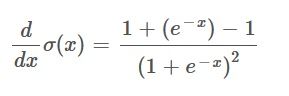
By doing this we can split the function into two separate fractions like this:

By having the function represented like this we are able to cancel out the e^-x in the first fraction. Thereby giving us the following:
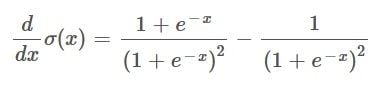
Now, it’s possible to rewrite this as:
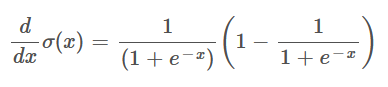
I think that this is one of the harder steps to immediately perceive, however, if you try calculating backwards by multiplying these two fractions, you should end up with the result of the step from before. If you first multiply the leftmost fraction with the value one from the parenthesis on the right, you just get the left fraction itself, which corresponds to the first fraction in the equation from before. Next, you multiply the left fraction with the negative fraction from the parenthesis, and thereby end up with a squared denominator, the second fraction from the previous equation.
5. Swap the Sigmoid Function Into the Equation
Now to the final step. If you look at the equation that we have just arrived at, you might spot that it actually includes the Sigmoid function itself. Which, as a reminder, looks like this:
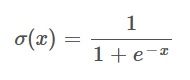
We can therefore swap the Sigmoid function into the equation above, which makes us arrive at the desired form:
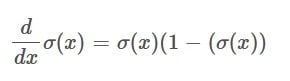
That’s it! This is the math behind why the derivative of the Sigmoid function is just the Sigmoid function itself multiplied by one minus the Sigmoid function.
Congratulations on making it all the way through all those equations.
Why Understanding the Derivative of the Sigmoid Function Is Important
You have now learned how to find the derivative of the Sigmoid function. The whole reason for doing that is because it’s used during the backpropagation step of a neural network in order to adjust weights either up or down. Since all equations needed for the derivative of the Sigmoid function are already found during the feedforward step, it saves us a ton of computations, and this is one of the benefits of using the Sigmoid function as an activation function in the layers of a neural network.
I hope you found this post useful, and that it is now clear why the derivative of the Sigmoid function is as it is.
Frequently Asked Questions
What is the derivative of the Sigmoid function?
The derivative of the Sigmoid function is the function itself multiplied by one minus the sigmoid function. It’s used in the backpropagation step to adjust the model weights up or down.
How do you calculate the derivative of the Sigmoid function?
There are five steps to calculate the derivative of the sigmoid function?
- Use the chain rule to find the derivative of the outer function.
- Calculate the derivative of the inner function.
- Reduce the expression.
- Split the function into two fractions.
- Swap the Sigmoid function into the equation.


