

Overfitting and underfitting are common problems in machine learning and can impact the performance of a model. Overfitting occurs when the model is too complex and fits the training data too closely. This leads to poor generalization. Underfitting happens when a model is too simple leading to poor performances.
Overfitting vs. Underfitting Defined
- Overfitting: Overfitting is a machine learning performance issue that occurs when the model is too complex and fits the training data too closely. This leads to poor generalization.
- Underfitting: Underfitting is an issue that occurs when a machine learning model is too simple leading to low model accuracy and poor performance.
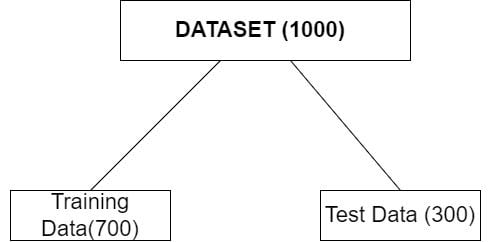
Understanding these concepts is essential for building effective machine learning models. Before building a machine learning model it’s common to split the data set into training data and test data.
The training data is used to train the machine learning model to find the patterns and relationships in the data. The trained model is then used on the test data set to make the predictions.
In short, training data is used to train the model while the test data is used to evaluate the performance of the trained data. How the model performs on these data sets is what reveals overfitting or underfitting.
Overfitting vs. Underfitting Explained
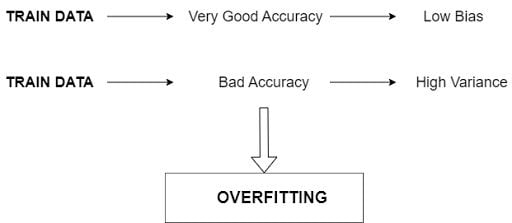
Overfitting occurs when the model is very complex and fits the training data very closely. This will result in poor generalization of the model. This means the model performs well on training data, but it won’t be able to predict accurate outcomes for new, unseen data.
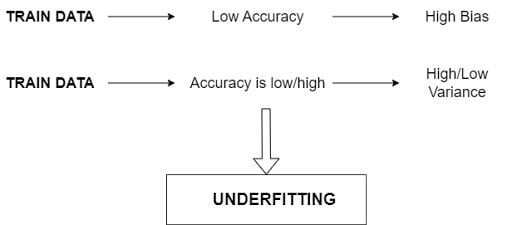
Underfitting occurs when a model is too simple and is unable to properly capture the patterns and relationships in the data. This means the model will perform poorly on both the training and the test data.
The aim of the machine learning model should be to produce good training and test accuracy.
What Causes Overfitting vs. Underfitting?
If a model uses too many parameters or if it’s too powerful for the given data set, it will lead to overfitting. On the other hand, when the model has too few parameters or isn’t powerful enough for a given data set, it will lead to underfitting.
How Bias and Variance Impact Overfitting vs. Underfitting
Bias and variance are two errors that can severely impact the performance of the machine learning model.
If a model has a very good training accuracy, it means the model has low variance. But if the training accuracy is bad, then the model has high variance. If the model has bad test accuracy, then it has a high variance. If the test accuracy is good, this means the model has low variance.
How to Fix Overfitting vs. Underfitting
- To solve the issue of overfitting and underfitting, it’s important to choose an appropriate model for the given data set.
- Hyper-performance tuning can also be performed.
- For overfitting, reducing the model complexity can help. Similarly, for underfitting, increasing the model complexity can improve results.
- Overfitting is caused by too many features in the data set, and underfitting is caused by too few features. During feature engineering the numbers of features can be decreased and increased to avoid overfitting and underfitting respectively.
Overfitting and Underfitting are two very common issues in machine learning. Both overfitting and underfitting can impact the model’s performance. Overfitting occurs when the model is complex and fits the data closely while underfitting occurs when the model is too simple and unable to find relationships and patterns accurately.
It’s very important to recognize both these issues while building the model and deal with them to improve its performance of the model.


