

I’ve been fascinated by natural language processing (NLP) since I got into data science. My background is in technical writing and rhetorical theory so I’m drawn to projects involving text like sentiment analysis and topic extraction because I wanted to develop an understanding of how machine learning can provide insight into written language.
I always wanted a guide like this one to break down how to extract data from popular social media platforms. With increasing accessibility to powerful pre-trained language models like BERT and ELMo, it is important to understand where to find and extract data. Luckily, social media is an abundant resource for collecting NLP data sets, and they’re easily accessible with just a few lines of Python.
NLP for Beginners: Web Scraping Social Media Sites
Prerequisites
This article teaches you how to extract data from Twitter, Reddit and Genius. I assume you already know the basics of Python libraries Pandas and SQLite.
Manage Your API Keys
Before getting into the code, it’s important to stress the value of an API key. If you’re new to managing API keys, make sure to save them into a config.py file instead of hard-coding them in your app. Make sure not to include them in any code shared online. API keys can be valuable (and sometimes very expensive) so you must protect them. If you’re worried your key has been leaked, most providers allow you to regenerate them.
Add the config file to your gitignore file to prevent it from being pushed to your repo too!
Twitter API
Twitter provides a plethora of data that is easy to access through their API. With the Tweepy Python library, you can easily pull a constant stream of tweets based on the desired topics. Twitter is great for mining trends and sentiment.
For this tutorial, you’ll need to register an app with Twitter to get API Keys. Check out the official Twitter documentation if you’re not familiar with their developer portal!
Use pip to install Tweepy and unidecode.
pip install tweepy
pip install unidecode
Save the following keys to a config file:

Using Tweepy
Connecting Tweepy to Twitter uses OAuth1. If you’re brand new to API authentication, check out the official Tweepy authentication tutorial.
To save the data from the incoming stream, I find it easiest to save it to an SQLite database. If you’re not familiar with SQL tables or need a refresher, check this free site for examples or check out my SQL tutorial.
The function unidecode() takes unicode data and tries to represent it in ASCII characters.
#import dependencies
import tweepy
from tweepy import OAuthHandler
from tweepy.streaming import StreamListener
import json
from unidecode import unidecode
import time
import datetime
#import the API keys from the config file.
from config import con_key, con_sec, a_token, a_secret
sqlite3conn = sqlite3.connect("twitterStream.sqlite")
c = conn.cursor()
I need to create the table and store the data. I use SQLite because it is lightweight and server-less. Plus I like keeping all the data in one place!
def create_table():
c.execute("CREATE TABLE IF NOT EXISTS Tweets(timestamp REAL, tweet TEXT)")
conn.commit()
create_table()
Notice I use IF NOT EXISTS to make sure the table doesn’t already exist in the database. Remember to commit the transaction using the conn.commit() call.
Create a StreamListener Class
Here is some boilerplate code to pull the tweet and a timestamp from the streamed twitter data and insert it into the database.
class Listener(StreamListener):
def on_data(self, data):
try:
data = json.loads(data)
tweet = unidecode(data['text'])
time_ms = data['timestamp_ms']
#print(tweet, time_ms)
c.execute("INSERT INTO Tweets (timestamp, tweet) VALUES (?, ?)", (time_ms, tweet))
conn.commit()
time.sleep(2)
except KeyError as e:
print(str(e))
return(True)
def on_error(self, status_code):
if status_code == 420:
#returning False in on_error disconnects the stream
return False
while True:
try:
auth = OAuthHandler(con_key, con_sec)
auth.set_access_token(a_token, a_secret)
twitterStream = tweepy.Stream(auth, Listener())
twitterStream.filter(track=['DataScience'])
except Exception as e:
print(str(e))
time.sleep(4)
Notice I slow the stream using time.sleep().
You can see the code is wrapped in a try/except to prevent potential hiccups from disrupting the stream. Additionally, the documentation recommends using an on_error() function to act as a circuit-breaker if the app is making too many requests.
You’ll also notice I wrap the stream object in a while condition. That way, it stops if it hits the 420 error.
Notice the twitterstream.filter uses trackto find keywords in tweets. If you want to follow a specific user’s tweets, use .filter(follow=[“”]).
Extract Data From the SQLite Database
sql = '''select tweet from Tweets
where tweet not like 'RT %'
order by timestamp desc'''
tweet_df = pd.read_sql(sql, conn)
tweet_df

Reddit API
Like Twitter, Reddit contains a jaw-dropping amount of information that is easy to scrape. If you don’t know, Reddit is a social network that works like an internet forum allowing users to post about whatever topic they want. Users form communities called subreddits, and they up-vote or down-vote posts in their communities to decide what gets viewed first and what sinks to the bottom.
I’ll explain how to get a Reddit API key and how to extract data from Reddit using the PRAW library. Although Reddit has an API, the Python Reddit API Wrapper, or PRAW for short, offers a simplified experience. PRAW supports Python 3.5+.
Getting Started with Reddit API
A Reddit user account is required to use the API. It’s completely free and only requires an email address.
Registering an App for Keys
If it is your first time, follow the steps below to get an API key after signing into Reddit. If you already have a key, go to your apps page.
Click the User Account droplist. User options display.

Click Visit Old Reddit from the user options. The page will change and the URL will become https://old.reddit.com/.
Click the preferences link next to the logout button.
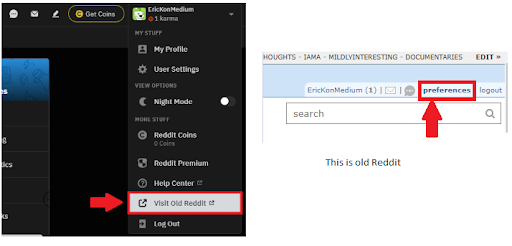
Click the apps tab on the preferences screen.
Click the are you a developer? create an app… button.
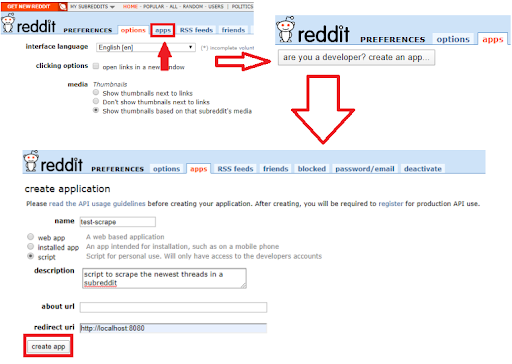
Register Reddit app.
Enter a name.
Select the type of app.
Enter a description.
Use https://localhost:8080 as the redirect URI.
Click create app after populating the fields.

The API information required to connect will display. Congratulations on getting set up to scrape Reddit data!
Using PRAW to Extract Reddit Data
The recommended way to install PRAW is to use pip, then install the following packages to create the dashboard.
pip install prawStart by importing the libraries and the config file:
import praw
import pandas as pd
from config import cid, csec, uaCreate a Reddit Instance
Create a read-only Reddit instance. That means you don’t need to enter Reddit credentials used to post responses or create new threads; the connection only reads data.
PRAW uses OAuth authentication to connect to the Reddit API.
#create a reddit connection
reddit = praw.Reddit(client_id= cid,
client_secret= csec,
user_agent= ua)
Identify Subreddits
Here’s a list of examples I think would be fun to explore:
news, datascience, learnmachinelearning, gaming, funny, politics
Exploring Objects and Attributes
Use the subreddit class in PRAW to retrieve the data from the desired subreddit. It’s possible to order the data based on the following Reddit options:
- hot — order by the posts getting the most traffic
- new — order by the newest posts in the thread
- top — order by the most up-voted posts
- rising — order by the posts gaining popularity
If you want to include multiple subreddits, use a + symbol:
#single subreddit new 5
subreddit = reddit.subreddit('news').new(limit = 5)
#multiple subreddits top 5
subreddit = reddit.subreddit('news' + 'datascience').top(limit = 5)This returns an object that holds the data in an attribute. The attribute is like a key in a dictionary.

The data is linked to an attribute owned by the object. If the attribute is the key, the data is the value. The attributes are dynamically generated, so it is best to check what is available using Python’s built-in vars() function.
Use this boilerplate code to see all the attributes owned by objects representing the Reddit post. It’s a LONG list!
subreddit = reddit.subreddit('news').new(limit = 1)
for post in subreddit:
pprint.pprint(vars(post))
Notice in the list the attributes of interest:
- title — returns post title
- score — returns number of up-votes or down-votes
- num_comments — returns the number of comments on the thread
- selftext — returns the body of the post
- created — returns a timestamp for the post
- pinned — indicates whether the thread was pinned
- total_awards_received — returns number of awards received by the post
Save the Reddit Data
Now that you’ve identified the attributes, load the data into a Pandas DataFrame or save them to an SQLite database like in the Twitter example above. In this example, I’ll save it to a Pandas DataFrame.

Genius Lyrics
I’m a fan of music, particularly heavy metal. In heavy metal, the lyrics can sometimes be quite difficult to understand, so I go to Genius to decipher them. Genius is a platform for annotating lyrics and collecting trivia about music, albums and artists. Genius allows users to register an API client.
API Client Registration

Either sign up or sign in.
Click the developers link.
Click create an API client.
Enter an app name.
Enter a website URL if you have one, otherwise https://127.0.0.1 will work.
Click save. The API client will display.
Click generate access token to generate an access token.

Extracting Lyrics
For legal reasons, the Genius API does not provide a way to download song lyrics. It’s possible to search lyrics, but not download them. Luckily for everyone, Medium author Ben Wallace developed a convenient wrapper for scraping lyrics. Check out his original code on GitHub.
I’ve modified Ben’s wrapper to make it easier to download an artist’s complete works rather than code the albums I want to include. I also added an artist column to store the artist name.
The wrapper uses the API to help the URLs link to the lyrics. From there, Beautiful Soup parses the HTML for each URL. The process results in a dataframe that contains the song title, URL, artist, album name and lyrics:

Review the GeniusArtistDataCollect Wrapper
The wrapper is a class named GeniusArtistDataCollect(). Use it to connect to the API and retrieve song lyrics for a specified artist. In the example, I use one of my favorite metal bands, The Black Dahlia Murder.
To use GeniusArtistDataCollect(), instantiate it, passing in the client access token and the artist name.
g = GeniusArtistDataCollect(token, 'The Black Dahlia Murder')Call get_artists_songs() from the GeniusArtistDataCollect object. This will return as a Pandas DataFrame.
songs_df = g.get_artist_songs()
The Wrapper
Here’s the modified wrapper:
import os
import re
import requests
import pandas as pd
import urllib.request
from bs4 import BeautifulSoup
from config import token
class GeniusArtistDataCollect:
"""A wrapper class that is able to retrieve, clean, and organize all the album songs of a given artist
Uses the Genius API and webscraping techniques to get the data."""
def __init__(self, client_access_token, artist_name):
"""
Instantiate a GeniusArtistDataCollect object
:param client_access_token: str - Token to access the Genius API. Create one at https://genius.com/developers
:param artist_name: str - The name of the artist of interest
THIS HAS BEEN REMOVED :param albums: list - A list of all the artist's albums to be collected
"""
self.client_access_token = client_access_token
self.artist_name = artist_name
#self.albums = albums
self.base_url = 'https://api.genius.com/'
self.headers = {'Authorization': 'Bearer ' + self.client_access_token}
self.artist_songs = None
def search(self, query):
"""Makes a search request in the Genius API based on the query parameter. Returns a JSON response."""
request_url = self.base_url + 'search'
data = {'q': query}
response = requests.get(request_url, data=data, headers=self.headers).json()
return response
def get_artist_songs(self):
"""Gets the songs of self.artist_name and places in a pandas.DataFrame"""
# Search for the artist and get their id
search_artist = self.search(self.artist_name)
artist_id = str(search_artist['response']['hits'][0]['result']['primary_artist']['id'])
print("ID: " + artist_id)
# Initialize DataFrame
df = pd.DataFrame(columns=['Title', 'URL'])
# Iterate through all the pages of the artist's songs
more_pages = True
page = 1
i = 0
while more_pages:
print("page: " + str(page))
# Make a request to get the songs of an artist on a given page
request_url = self.base_url + 'artists/' + artist_id + '/songs' + '?per_page=50&page=' + str(page)
response = requests.get(request_url, headers=self.headers).json()
print(response)
# For each song which the given artist is the primary_artist of the song, add the song title and
# Genius URL to the DataFrame
for song in response['response']['songs']:
if str(song['primary_artist']['id']) == artist_id:
title = song['title']
url = song['url']
df.loc[i] = [title, url]
i += 1
page += 1
if response['response']['next_page'] is None:
more_pages = False
# Get the HTML, Album Name, and Song Lyrics from helper methods in the class
df['Artist'] = self.artist_name
df['html'] = df['URL'].apply(self.get_song_html)
df['Album'] = df['html'].apply(self.get_album_from_html)
#df['InAnAlbum'] = df['Album'].apply(lambda a: self.is_track_in_an_album(a, self.albums))
#df = df[df['InAnAlbum'] == True]
df['Lyrics'] = df.apply(lambda row: self.get_lyrics(row.html), axis=1)
del df['html']
self.artist_songs = df
return self.artist_songs
def get_song_html(self, url):
"""Scrapes the entire HTML of the url parameter"""
request = urllib.request.Request(url)
request.add_header("Authorization", "Bearer " + self.client_access_token)
request.add_header("User-Agent",
"curl/7.9.8 (i686-pc-linux-gnu) libcurl 7.9.8 (OpenSSL 0.9.6b) (ipv6 enabled)")
page = urllib.request.urlopen(request)
html = BeautifulSoup(page, "html")
print("Scraped: " + url)
return html
def get_lyrics(self, html):
"""Scrapes the html parameter to get the song lyrics on a Genius page in one, large String object"""
lyrics = html.find("div", class_="lyrics")
all_words = ''
# Clean lyrics
for line in lyrics.get_text():
all_words += line
# Remove identifiers like chorus, verse, etc
all_words = re.sub(r'[\(\[].*?[\)\]]', '', all_words)
# remove empty lines, extra spaces, and special characters
all_words = os.linesep.join([s for s in all_words.splitlines() if s])
all_words = all_words.replace('\r', '')
all_words = all_words.replace('\n', ' ')
all_words = all_words.replace(' ', ' ')
return all_words
def get_album_from_html(self, html):
"""Scrapes the html parameter to get the album name of the song on a Genius page"""
parse = html.findAll("span")
album = ''
for i in range(len(parse)):
if parse[i].text == 'Album':
i += 1
album = parse[i].text.strip()
break
return album
Two More Examples of Web Scraping
The Genius lyrics example uses BeautifulSoup to scrape the lyrics from the website. Web scraping is a useful technique that makes it easy to collect a variety of data. I walk through an additional web scraping example in a previous article. Although I haven’t yet used his methods, fellow Built In Expert Contributor Will Koehrsen walks through scraping and parsing Wikipedia. Check out his work!
Kaggle and Google Dataset Search
Although I think it is fun to collect and create my own data sets, Kaggle and Google’s Dataset Search offer convenient ways to find structured and labeled data. Kaggle is a popular competitive data science platform. I’ve included a list of popular data sets for NLP projects.
- Determine whether a news story is from the Onion or not
- Youtube rankings and descriptions
- Netflix shows and descriptions
- Wine reviews (I’ve used this in several articles and projects.)
- A collection of Amazon food reviews
- News headlines for fake news
- Corpus for entity recognition tasks
- Tweets for airline sentiment analysis
- Yelp review data set
The Takeaway
As NLP becomes more mainstream, it’s important to understand how to easily collect rich, text-based data sets. Getting into natural language processing can be tough and I hope this guide simplifies methods to collect text data. With a few lines of Python, the amount of data available at everyone’s fingertips on Twitter, Reddit and Genius is staggering!


