

Data structures and algorithms allow us to organize, store and manage data for efficient access and modification. But which structures and algorithms do you use for your project? Let’s start with the simple stuff.
Data Structures and Algorithms in Python
- Built-in Data Structures
- User-Defined Data Structures
- Tree Traversal Algorithms
- Sorting Algorithms
- Searching Algorithms
Built-in Data Structures
First, let’s take a look at four built-in data structures in Python: list, tuple, set, and dictionary.
List
We define a list using square brackets that hold data separated by commas. The list is mutable, ordered and can contain a mix of data types.
months = ['january','february','march','april','may','june','july','august','september','october','november','december']
print(months[0]) # print the element with index 0
print(months[0:7]) # all the elements from index 0 to 6.
months[0] = 'birthday' # exchange the value in index 0 with the word birthday
print(months)Our output will look like this:
january
['january', 'february', 'march', 'april', 'may', 'june', 'july']
['birthday', 'february', 'march', 'april', 'may', 'june', 'july', 'august', 'september', 'october', 'november', 'december']Below there are some useful functions for the list.
# Join is a string method that takes a list of strings as an argument,
# and returns a string consisting of the list elements joined by a separator string.
first_str = "\n".join(["What","is","your","favourite","painting","?"])
second_str = "-".join(["Who","is","your","favourite","artist","?"])
print(first_str)
print(second_str)
Our output will look like this:
What
is
your
favourite
painting
?
Who-is-your-favourite-artist-?artist = ['Chagall', 'Kandinskij', 'Dalí', 'da Vinci', 'Picasso', 'Warhol']
artist.append('Basquiat') # append method permits us to add Basquiat in our list of artists
print(artist)Output:
['Chagall', 'Kandinskij', 'Dalí', 'da Vinci', 'Picasso', 'Warhol', 'Basquiat']Tuple
A tuple is another container. It’s a data type for immutable ordered sequences of elements. A tuple is immutable because you can’t add or remove elements from them, nor can you sort them in place.
length, width, height = 7, 3, 1 # we can assign multiple variables in one shot
print("The dimensions are {} x {} x {}".format(length, width, height))Output:
The dimensions are 7 x 3 x 1Set
Set is a mutable and unordered collection of unique elements. It permits us to remove duplicates from a list quickly.
numbers = [1, 2, 6, 3, 1, 1, 5]
unique_nums = set(numbers)
print(unique_nums)
artist = {'Chagall', 'Kandinskij', 'Dalí', 'da Vinci', 'Picasso', 'Warhol', 'Basquiat'}
print('Turner' in artist) # check if there is Turner in the set artist
artist.add('Turner')
print(artist.pop()) #remove the last itemThe output will look like this:
{1, 2, 3, 5, 6}
False
BasquiatDictionary
Dictionary is a mutable and unordered data structure. It permits storing a pair of items (i.e. keys and values). As the example below demonstrates, in the dictionary, it’s possible to include containers inside other containers to create compound data structures.
music = { 'jazz': {"Coltrane": "In a Sentimental Mood",
"M.Davis":"Blue in Green" ,
"T.Monk":"Don't Blame Me"},
"classical" : {"Bach": "Cello Suit",
"Mozart": "Lacrimosa",
"Satie": "Gymnopédie"}}
print(music["jazz"]["Coltrane"]) # we select the value of the key Coltrane
print(music["classical"]["Mozart"])The output will look like this:
In a Sentimental Mood
Lacrimosa
User-Defined Data Structures
Now I’ll introduce you to three user-defined data structures: ques, stack, and tree. (Please note, in what follows, I’m assuming you have a basic knowledge of classes and functions.)
Stack using arrays
The stack is a linear data structure where we arrange elements sequentially. It follows the principle last in, first out (LIFO). So, the last element inserted will be removed first. The operations are:
- Push → Inserting an element into the stack
- Pop → Deleting an element from the stack
The conditions to check:
- Overflow condition → This condition occurs when we try to put one more element into a stack that’s already at maximum capacity.
- Underflow condition → This condition occurs when we try to delete an element from an empty stack.
class mystack:
def __init__(self):
self.data =[]
def length(self): #length of the list
return len(self.data)
def is_full(self): #check if the list is full or not
if len(self.data) == 5:
return True
else:
return False
def push(self, element):# insert a new element
if len(self.data) < 5:
self.data.append(element)
else:
return "overflow"
def pop(self): # # remove the last element from a list
if len(self.data) == 0:
return "underflow"
else:
return self.data.pop()
a = mystack() # I create my object
a.push(10) # insert the element
a.push(23)
a.push(25)
a.push(27)
a.push(11)
print(a.length())
print(a.is_full())
print(a.data)
print(a.push(31)) # we try to insert one more element in the list - the output will be overflow
print(a.pop())
print(a.pop())
print(a.pop())
print(a.pop())
print(a.pop())
print(a.pop()) # try to delete an element in a list without elements - the output will be underflowThe output will look like this:
5
True
[10, 23, 25, 27, 11]
overflow
11
27
25
23
10
underflowQueue Using Arrays
The queue is a linear data structure where elements are sequential. It follows the FIFO principle (first in, first out). Think about when you go to the movies with your friends, as you can imagine the first of you that hands over your ticket is also the first one who steps out of line. The mechanism of the queue is the same.
The aspects that characterize a queue are:
Two ends:
- Front → Points to starting element
- Rear → Points to the last element
There are two operations:
- Enqueue → Inserting an element into the queue (at the end).
- Dequeue → Deleting an element from the queue (from the front).
There are two conditions:
- Overflow → Insertion into a full queue
- Underflow → Deletion from an empty queue
class myqueue:
def __init__(self):
self.data = []
def length(self):
return len(self.data)
def enque(self, element): # put the element in the queue
if len(self.data) < 5:
return self.data.append(element)
else:
return "overflow"
def deque(self): # remove the first element that we have put in queue
if len(self.data) == 0:
return "underflow"
else:
self.data.pop(0)
b = myqueue()
b.enque(2) # put the element into the queue
b.enque(3)
b.enque(4)
b.enque(5)
print(b.data)
b.deque()# # remove the first element that we have put in the queue
print(b.data)And the output will look like this:
[2, 3, 4, 5]
[3, 4, 5]General Tree
Trees are used to define hierarchy. It starts with the root node and goes further down. The last nodes are called child nodes.
Here we’ll focus on the binary tree. The binary tree is a tree data structure in which each node has (at most) two children, which are referred to as the left child and the right child. Below you can see a representation and an example of the binary tree in Python where I constructed a class called node and the objects that represent the different nodes (A, B, C, D, and E).

Algorithms
The concept of the algorithm has existed since antiquity. In fact, the ancient Egyptians used algorithms to solve their problems and they taught this approach to the Greeks.
The word algorithm derives from the ninth-century Persian mathematician Muḥammad ibn Mūsā al-Khwārizmī, whose name was Latinized as Algorithmi. Al-Khwārizmī was also an astronomer, geographer, and a scholar in the House of Wisdom in Baghdad.
As you already know, algorithms are instructions formulated in a finite and sequential order to solve problems.
When we write an algorithm, we have to know what the exact problem is, determine where we need to start and stop, and formulate the intermediate steps.
There are three main approaches to solve algorithms:
- Divide et Impera (also known as divide and conquer) → It divides the problem into sub-parts and solves each one separately.
- Dynamic programming → It divides the problem into sub-parts, remembers the results of the sub-parts, and applies it to similar ones.
- Greedy algorithms → This involves taking the easiest step while solving a problem without worrying about the complexity of the future steps.
Tree Traversal Algorithm
Trees in Python are non-linear data structures. They are characterized by roots and nodes. I take the class I constructed before for the binary tree.
Tree Traversal refers to visiting each node present in the tree exactly once, in order to update or check them.
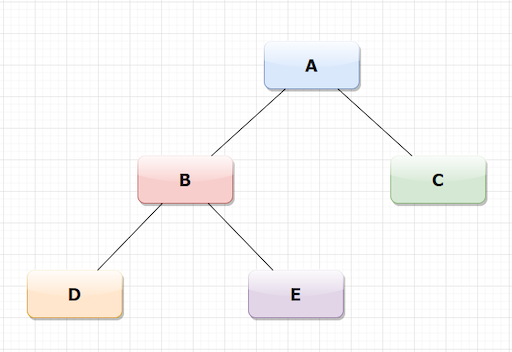
There are three types of tree traversals:
- In-order traversal
- Pre-order traversal
- Post-order traversal
In-Order Traversal
In-order traversal refers to visiting the left node, followed by the root and then the right nodes.
Here D is the leftmost node where the nearest root is B. The right of root B is E. Now the left sub-tree is completed, so I move towards the root node A and then to node C.
# create the class Node and the attributes
class Node:
def __init__(self, letter):
self.childleft = None
self.childright = None
self.nodedata = letter
# create the nodes for the tree
root = Node('A')
root.childleft = Node('B')
root.childright = Node('C')
root.childleft.childleft = Node('D')
root.childleft.childright = Node('E')The output will look like this:
D
B
E
A
CPre-Order Traversal
Pre-order traversal refers to visiting the root node followed by the left nodes and then the right nodes.
In this case, I move to the root node A and then to the left child node B and to the sub child node D. After that I can go to the nodes E and then C.
def PreOrd(root):
if root:
print(root.nodedata)
PreOrd(root.childleft)
PreOrd(root.childright)
PreOrd(root)Output:
A
B
D
E
CPost-Order Traversal
Post-order traversal refers to visiting the left nodes followed by the right nodes and then the root node.
I go to the most left node which is D and then to the right node E. Then, I can go from the left node B to the right node C. Finally, I move towards the root node A.
def PostOrd(root):
if root:
PostOrd(root.childleft)
PostOrd(root.childright)
print(root.nodedata)
PostOrd(root)Your output will look like:
D
E
B
C
ASorting Algorithm
We use the sorting algorithm to sort data in a given order. We can classify the data in merge sort and bubble sort.
Merge Sort
The merge sort algorithm follows the divide et impera rule. The algorithm first divides into smaller lists, compares adjacent lists and then reorders them in the desired sequence. In other words, from unordered elements as input, we need to have ordered elements as output. Here’s merge sort in practice:
def merge_sort(ourlist, left, right): #left and right corresponds to starting and ending element of ourlist
if right -left > 1: # check if the length of our list is greater than 1
middle = (left + right) // 2 # we divide the length in two parts
merge_sort(ourlist, left, middle) # recursively I call the merge_sort function from left to middle
merge_sort(ourlist, middle, right) # then from middle to right
merge_list(ourlist, left, middle, right) # finally I create ourlist in complete form(left, middle and right)
def merge_list(ourlist, left, middle, right):# I create the function merged_list
leftlist = ourlist[left:middle] # I define the leftlist
rightlist = ourlist[middle:right] # I define the right list
k = left # it is the the temporary variable
i = 0 # this variable that corresponds to the index of the first group help me to iterate from left to right
j = 0 # this variable that corresponds to the index of the second group help me to iterate from left to right
while (left + i < middle and middle+ j < right): # the condition that I want to achieve before to stop my iteration
if (leftlist[i] <= rightlist[j]): #if the element in the leftlist is less or equal to the element in the rightlist
ourlist[k] = leftlist[i] # In this case I fill the value of the leftlist in ourlist with index k
i = i + 1 #now I have to increment the value by 1
else: # if the above condition is not match
ourlist[k] = rightlist[j] # I fill the rightlist element in ourlist with index k
j = j + 1 # I increment index j by 1
k = k+1 # now I increment the value of k by 1
if left + i < middle: # check if left + i is less than middle
ourlist[k] = leftlist[i] # I place all elements of my left list in ourlist
i = i + 1
k = k + 1
else: # otherwise if my leftlist is empty
while k < right: # until k is less then right
ourlist[k] = rightlist[j] # I place all elements of rightlist in ourlist
j = j + 1
k = k + 1
ourlist = input('input - unordered elements: ').split() # insert the input and split
ourlist = [int(x) for x in ourlist]
merge_sort(ourlist, 0, len(ourlist))
print('output - ordered elements: ')
print(ourlist)The output looks like this:
input - unordered elements: 15 1 19 93
output - ordered elements:
[1, 15, 19, 93]Bubble Sort
This algorithm first compares and then sorts adjacent elements if they are not in the specified order. For example:
def bubble_sort(ourlist): # I create my function bubble_sort with the argument called ourlist
b=len(ourlist)-1 # for every list, I will have a minus 1 iteration
for x in range(b): # for each element in the range of b, I check if they are ordered or not
for y in range(b-x):
if ourlist[y]>ourlist[y+1]: # if one element is greater than the nearest element in the list
ourlist[y],ourlist[y+1]=ourlist[y+1],ourlist[y] # I have to swap the elements, in other words
# I exchange the position of the two elements
return ourlist
ourlist=[15,1,9,3]
bubble_sort(ourlist)Output:
[1, 3, 9, 15]Insertion Sort
This algorithm picks one item in a given list and places it at the exact spot where you want it.
def ins_sort(ourlist):
for x in range(1, len(ourlist)): # loop for each element starting from 1 to the length of our list
k = ourlist[x] # element with the index x
j = x-1 # j is the index previus the index x
while j >=0 and k < ourlist[j]: # untill each elermnt of the list are less than their previous element my loop don't stop
ourlist[j+1] = ourlist[j] # the elemnt indexed before the element considered is set to the next one index
j -= 1 # I decrement index j by 1
ourlist[j+1] = k # now k is the element in the index j+1
return ourlist
ourlist = [15, 1, 9, 3]
ins_sort(ourlist)Searching Algorithms
We use searching algorithms to seek for some elements present in a given data set. There are many types of search algorithms such as linear search, binary search, exponential search and interpolation search, among others. For now, we’ll focus on linear search and binary search.
Linear Search
In a single-dimensional array we have to search a particular key element. The input is the group of elements and the key element we want to find. So, we have to compare the key element with each element of the group. In the following code, I try to seek element 27 in our list.
def lin_search(ourlist, key):
for index in range(0, len(ourlist)):
if (ourlist[index] == key):
return index
else:
return "not found"
ourlist = [15, 1, 9, 3]
lin_search(ourlist, 27)Our output will look like this:
'not found'Binary Search
In this algorithm, we assume the list is in ascending order. So, if the value of the search key is less than the element in the middle of the list, we narrow the interval to the lower half. Otherwise, we narrow to the upper half. We continue our check until we find the value or the list is empty.
* * *
Now that you have some sense of basic data structures and algorithms, you can start going deeper and using more complex algorithms in Python.
Frequently Asked Questions
Can I use Python for data structures and algorithms?
Python features built-in data structures, and data in Python can be analyzed with algorithms like traversal, searching and sorting algorithms.
How long does it take to learn Python data structures and algorithms?
Learning Python data structures and algorithms typically takes anywhere from a few weeks to a few months, depending on one’s experience, dedication and the quality of their learning resources, among other factors.


