

K-nearest neighbor (KNN) is a non-parametric, instance-based supervised machine learning algorithm that stores all training examples and classifies new data points based on their similarity to stored examples using a distance metric. KNN algorithms can be used for both classification and regression tasks, depending on the output type.
What Is a K-Nearest Neighbor (KNN)?
Let’s break it down with a wine example examining two chemical components called rutin and myricetin. Consider a measurement of the rutin vs. myricetin level with two data points — red and white wines. After being tested, they’re placed on a graph based on how much rutin and how much myricetin chemical content is present in the wines.

The “K” in KNN is a parameter that refers to the number of nearest neighbors to include in the majority of the voting process.
Now suppose we add a new glass of wine in the data set, and we want to know whether this new wine is red or white.

To do so, we need to find out what the neighbors are in this case. Let’s say k = 5, and the new data point is classified by the majority of votes from its five neighbors. The new point would be classified as a red wine since four out of five neighbors are red. This is a case of majority voting among labeled points, and what happens in case of ties.

Determining the K-Nearest Neighbor Algorithm’s ‘K’ Value
The “K” in KNN refers to the number of nearest neighbors used in classification or regression, and is based on feature similarity. Choosing the right value for K is a process called parameter tuning, which improves the algorithm accuracy. Finding the value of K is not easy.
How to Define a ‘K’ Value in a K-Nearest Neighbor Algorithm
Below are some ideas on how to pick the value of K in a K-nearest neighbor algorithm:
- There is no structured method for finding the best value for K. We need to assume that the training data is unknown and find the best value through trial and error.
- Choosing smaller values for K can be noisy and will have a higher influence on the result.
- Larger values of K will have smoother decision boundaries, which means a lower variance but increased bias. Also, it can be computationally expensive.
- Choose K is through cross-validation. One way to select the cross-validation data set from the training data set is to take a small portion from the training data set and call it a validation data set. Then use the same process to evaluate different possible values of K. In this way, we are able to predict the label for every instance in the validation set using K equals to one, K equals to two, K equals to three, and so on. Then we look at what value of K gives us the best performance on the validation set. From there, we can take that value and use that as the final setting of our algorithm to minimize the validation error.
- A common heuristic for choosing the value of K is to use K = √N, where N is the number of training samples, but this should be validated through cross-validation.
- Try to keep the value of K odd in order to avoid confusion between two classes of data.
How Does a K-Nearest Neighbor Algorithm Work?
In the classification setting, the K-nearest neighbor algorithm essentially boils down to forming a majority vote between the K with most similar instances to a given unseen observation. Similarity is defined according to a distance metric between two data points, which is chosen depending on the nature of the data (normalized, categorical, etc.). A popular one is the Euclidean distance method.

Other methods are Manhattan, Minkowski, and Hamming distance methods. For categorical variables, the Hamming distance must be used.
Let’s take a small example examining age vs. loan amount.

We need to predict Andrew’s default status — either yes or no.

Then calculate the Euclidean distance for all the data points.

With K=5, there are two Default=N and three Default=Y out of five closest neighbors. We can safely say the default status for Andrew is “Y” based on the majority similarity in three points out of five.
KNN is also a lazy learner because it doesn’t learn a discriminative function from the training data, but “memorizes” the training data set instead. This results in slower predictions, as computation is deferred until inference time.
Types of K-Nearest Neighbor Algorithm Distance Metrics
Hamming Distance
Hamming distance is mostly used in text data, which calculates the distance between two binary vectors. Here, binary vector means the data represented in the form of binary digits 0 and 1. It is also called binary strings.
Mathematically, it’s represented by the following formula:

Euclidean Distance
Euclidean distance is the most popular distance measure. It helps to find the distance between two real-valued vectors, like integers or floats. Before using Euclidean distance, we must normalize or standardize the data, otherwise, data with larger values will dominate the outcome.
Mathematically, it’s represented by the following formula.

Manhattan Distance
Manhattan distance is the simplest measure, and it’s used to calculate the distance between two real-valued vectors. It is called “Taxicab” or “City Block” distance measure.
If we start from one place and move to another, Manhattan distance will calculate the absolute value between starting and destination points. Manhattan is preferred over Euclidean if the two data points are in an integer space.
The Manhattan distance between two points (X1, Y1) and (X2, Y2) is represented by |X1 – X2| + |Y1 – Y2|.
Minkowski Distance
Minkowski distance is used to calculate the distance between two real value vectors. It is a generalized form for Euclidean and Manhattan distance. In addition, it adds a parameter “p,” which helps to calculate the different distance measures.
Mathematically it’s represented by the following formula. Note that in Euclidean distance p = 2, and p =1 if it is Manhattan distance.
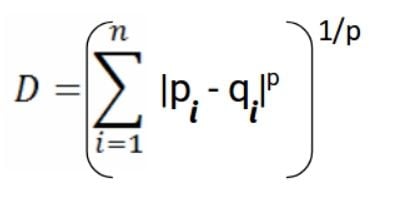
K-Nearest Neighbor Applications in Machine Learning
KNN is widely used in machine learning applications. Some of the most famous use cases are mentioned below.
Recommendation Engine
A recommendation engine provides product suggestions or services to the user based on the data. KNN has been used in the recommendation system to identify items or products based on the user’s data. However, it is unsuitable for high dimensional data due to computation. However, it is an excellent choice for the baseline approach.
Concept Search
Concept search involves searching semantically similar documents and classifying documents containing similar topics. In today’s world, data is generated exponentially, and it creates tons of documents. Each of those documents contains key concepts. Assume we have a use case to extract these key concepts from the set of documents, and these documents contain a vast amount of data. To find the key concepts from the data, we use the KNN algorithm.
Missing Data Imputation
Data sets frequently have missing values, which creates a problem for machine learning models or analysis. We need to replace the missing values before doing modeling or analysis. KNN is an effective algorithm for imputing the missing values in a process that’s called “nearest neighbor imputation.”
Pattern Recognition
KNN is used to identify the patterns in text or images. For example, it is used to identify handwritten digit recognition, detect patterns in credit card usage and image recognition.
Banking
KNN is widely used in banking and financial use cases. In the banking sector, it helps to predict whether giving a loan to the customer is risky or safe. In financial institutes, it helps to predict the credit rating of customers.
K-Nearest Neighbor Algorithm Pros
- It’s simple to implement.
- It’s flexible to different feature/distance choices.
- It naturally handles multi-class cases.
- It can do well in practice with enough representative data.
K-Nearest Neighbor Algorithm Cons
- We need to determine the value of parameter “K” (number of nearest neighbors).
- Computation cost is quite high because we need to compute the distance of each query instance to all training samples.
- It requires a large storage of data.
- We must have a meaningful distance function.
Frequently Asked Questions
What is K-Nearest Neighbor (KNN)?
K-nearest neighbor (KNN) is a non-parametric, supervised machine learning algorithm that classifies a new data point based on the classifications of its closest neighbors, and is used for classification and regression tasks. It stores all available cases and assigns a class to a new point by evaluating the majority class among its K nearest neighbors, determined using a distance metric like Euclidean or Hamming distance. KNN does not build a model during training, making it a lazy learner that "memorizes" the data set and defers computation to prediction time.
What is the K in K-Nearest Neighbor (KNN)?
The "K" in K-nearest neighbors (KNN) represents the number of nearest data points considered when classifying a new data point.
How do I choose the right value for K in KNN?
To choose the optimal value for K in a KNN algorithm you can use:
- Trial and error
- Cross-validation
- A common heuristic like √N, where N is the number of training samples.
It's often best to keep K an odd number to avoid ties.


