

On e-commerce platforms, product tags give users a snapshot of what to expect and help them to explore related products. If we don’t create tags with high accuracy, users will struggle to find the products they want and their interaction with the platform will be limited.
How to Use NLP to Tag Online Products With Doc2Vec
- Choose tags.
- Manually tag products.
- Convert product descriptions to machine-readable numbers.
- Build up an understanding of what that tag means.
- Use this general understanding to assign tags to products.
Creating accurate tags becomes increasingly difficult as the number of products increases. To solve this, I’ll show you how to create product tags by combining manual tagging with machine learning techniques. As an example we’ll use Rakuten Travel Experiences where the products are represented by activities.
Choose Tags
Choosing the right tags to use is not necessarily obvious. There are various approaches.
- User Based: What tags do users care the most about? For this approach, the first step is to talk to users or create a survey to find out which tags they’re interested in and what makes sense to them.
- Machine Learning: What tags are built into the data? Clustering algorithms such as k-means can be used to group together products and then topic modeling techniques can come up with the tags that represent the clusters.
- Market Research: What are competitors doing? Whatever the industry, it’s possible to find competitors who use tags in some way or another. Often they’ve done various types of research and testing to come up with their own tags and these can be a great starting point. Your research may also indicate industry standards users expect.
- Internal Expertise: What do you think is best? Within your company there should be various experts in the industry and they’ll likely have a great way to set tags based on their experience. This is another great starting point, though you should always be wary about making product decisions based on the ideas of just a few people.
Of course, these are only some of the approaches and it’s necessary to combine them all to come out with the best results. For example, you can run a machine learning algorithm to work out an initial set of clusters and then use your internal experts to choose precise tags and finally get feedback from users to see if the tags make sense and resonate well with the market.
For this example, we’ll use a list of tags corresponding to major categories of products:
'Culture', 'Nature', 'Relaxation', 'Crazy', 'Celebration', 'Adventure', 'Food', 'Romantic', 'Socializing', 'Instagrammable', 'Family', 'Theme Parks'Once you’ve landed on a list of tags, you’ve got to actually tag the products.
Why Should I Use Word2Vec for NLP?
Tag Products
For companies with hundreds of products, it’s feasible to manually tag them, but as the quantity of products increases this becomes an arduous practice to maintain and scale. In this situation it’s best to turn to an automated process.
The approach detailed below is:
- Manually tag products.
- Convert product descriptions to machine-readable numbers.
- Build up an understanding of what that tag means.
- Use this general understanding to assign tags to products.
This is an example of supervised learning, where we provide examples of input-output pairs and the model learns to predict what the output should be, given the input.
Manual Tagging
The first step is to manually tag some products. By manually tagging activities first, we introduce some so-called expert guidance for better performance. Choose a representative set of the products to give the most complete information to the model. For the techniques discussed we’ll tag just 10s of products in each class.
You can also manually tag using word matching. For example, if your product tag is “shirt,” then the word shirt is probably in the product description. This technique works well in specific cases but will fail with more generic tags.
As an example, we could assign the products manually, like this:
34% OFF Robot Restaurant Shinjuku Tokyo Discount E-Tickets (899)
=> Crazy
Studio Ghibli Museum Tickets — Preorder & Last-Minute Tickets (186)
=> Culture
Tokyo Disneyland Tickets — Maihama Station Pickup (10069)
=> Theme Parks
Reservation for Sushi Jiro Roppongi Michelin 2-star Tokyo (1690)
=> FoodGiving us a final JSON object with tags and product IDs to work with:
{
"Crazy": [123, 98, 899, etc.],
"Culture": [186, 1200, 323, etc.],
...
}While these were prepared by just one person, it’s often helpful to have at least three people go over each product to remove any biases that may exist.
Convert Products to Vectors
Once we have a set of tags to describe our products, we need to work out what they actually mean. We’ll do this with machine learning. For a machine learning algorithm to understand products it needs a way to reduce those products to numbers. In this case, we’ll refer to the numbers as a vector, because we often represent the product by a group of numbers. Typical things we would feed into the model would be product descriptions or product images. For product descriptions we have a few techniques to choose from, including:
Doc2Vec is a great technique and quite easy to implement in Python using Gensim. This model will reduce the product descriptions to a vector with a certain number of data points representing qualities of the products. These are unknown but often can be seen to align with particular qualities such as color, shape, size or, in our case, the tags or categories we are using.
from gensim.models.doc2vec import Doc2Vec
# Create a model with some pre-defined parameters.
model = Doc2Vec(vector_size=50, min_count=2, epochs=40)
# Build the vocabulary from some training data.
model.build_vocab(train_corpus)
# Train the model.
model.train(train_corpus, total_examples=model.corpus_count, epochs=model.epochs)In the case of product images, we can apply image recognition techniques. For example, we can convert the images to data, based on the color of each pixel and then train a neural network to predict which tag (class) a certain image belongs to. These models can be combined with those for product descriptions discussed below.
Decide the Meaning of a Tag
With the product descriptions reduced to vectors, we can think of what the definition of a certain tag means. A simple approach, which does fairly well for independent tags (i.e., a product belongs to one tag, but not another), is to take the average of the vectors for products with a certain tag. The result is a vector which represents the average product for that tag.
I’ve plotted an example for some product tags below. We see similar tags such as “Celebration” and “Instagrammable” (center-left) are so similar they almost completely overlap. We might want to reconsider these tags since they’re so similar. The tag “Crazy” is significantly removed from the other tags which makes sense; these products must be very distinct!

The vertical and horizontal axis represent some underlying meaning, such that the tags closer together are most similar.
Assign Tags
Now that we have the average product, we can find the products that should be tagged accordingly by finding any nearby vectors. If a vector is nearby, it should be similar. We can limit the distance to ensure we’re only capturing products that are sufficiently similar to the tag in question. We refer to this distance as a similarity measure.
At this point it’s helpful to plot a histogram of the similarity of products to tags to see what a good cutoff point might be. You want to make sure you’re tagging a good number of activities, but not tagging every product!
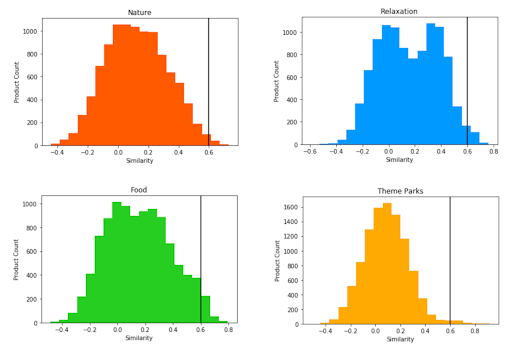
In the four examples shown above we have:
- Nature: We can see that many products don’t relate to this tag. The peak is around 0.1 similarity and then there’s a steady drop-off in nature-related products.
- Relaxation: As opposed to “Nature,” there is a secondary peak with many products around 0.4 similarity. We want to have a higher cutoff than this to avoid capturing all these products, which must have some similar aspects but are not fully related.
- Food: Similar to “Relaxation,” we can see a second peak, but this time it is much higher in similarity, around 0.6.
- Theme Parks: This has a clear plateau on the far right after 0.5 as we see that the similarity drops off quite quickly. This is likely because the “Theme Park” tag is straightforward, meaning we can easily say something is a theme park or not. Compare this to some of the previous tags such as “Relaxation.”
We might choose 0.6 as a cutoff point that balances having good meaning but not too few products tagged. Looking at the graphs you can see this isn’t perfect and we should be able to do better.
Validate Tags
Once we’ve prepared tags, the next step is to validate that they make sense. The simplest approach is to go through a random list of products under each tag and check they make sense. Ultimately, it comes down to how users respond to your tags. It’s useful to test your tags online and see how users interact with them. Are they using tags to research products? Do they view many products from tags or drop off at this point?
Next Steps
Within this article, we’ve created a list of tagged products using basic data processing and machine learning techniques. With these techniques it’s possible to get a decent quality tags system up and running quickly.
There are various ways we can try to improve upon our method. Rather than choosing the nearest products to our tags we can apply a machine learning algorithm such as a support vector machine (SVM) or multinomial naive Bayes which learn to predict the tag in a more sophisticated way. For these models, we require more training data but, in return, we’ll get greater predictive power.


