

Machine learning is the idea that computers can learn from examples and experience, without being explicitly programmed to do so. Instead of writing code, you feed data to the generic algorithm, and it builds logic based on the data given.
For example, one kind of algorithm is a classification algorithm. It can put data into different groups. The classification algorithm used to detect handwritten alphabets could also be used to classify emails into spam and not-spam.
A computer program is said to learn from experience E with some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.” -Tom M. Mitchell
Consider playing checkers:
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
What is Machine Learning For Beginners?

Examples of Machine Learning
Machine Learning Examples
- Facial Recognition
- Email Filtering
- Weather Prediction
- Medical Diagnosis
- Self-Driving Cars
- Recommendation Engines
- Virtual Personal Assistants
- Mapping Driving Routes For Efficiency
Over the last five years, machine learning has been widely researched due to the increase in computational speeds and hardware availability. These are now used in real time and deployed in several websites for better search procedures and recommendation systems. For example, because of machine learning, if you are searching Amazon for a product, for the next few days Amazon will show you similar items to your search.
Here are a few examples of classification problems where the goal is to categorize objects into a fixed set of categories.
Face detection: Identify faces in images (or indicate if a face is present).
Email filtering: Classify emails into spam and not-spam.
Medical diagnosis: Diagnose a patient as having or not having a disease.
Weather prediction: Predict, for instance, if it will rain tomorrow.
The Need FOR Machine Learning
Machine learning is a field raised out of artificial intelligence (AI). Through the application of AI, we sought to build better and intelligent machines. But except for a few mere tasks — like finding the shortest path between point A and B, for example — we were unable to program more complex and constantly evolving challenges. Then came the realization that the only way to achieve more advanced tasks was to let the machine learn from its own input, similar to how a child learns from their surroundings. So machine learning was developed as a new capability for computers, and is now present in so many segments of technology we may not even realize it's there.
Some data sets are so massive that the human brain needs help finding patterns, and this is where machine learning swings into action by helping people sift through large data sets faster.
If big data and cloud computing are gaining importance for their contributions, machine learning also deserves recognition for helping data scientists analyze large chunks of data via an automated process that saves time and effort.
The techniques we use for data mining have been around for years, but they're not effective without the power to run algorithms. When you run deep learning with access to better data, the output leads to dramatic breakthroughs, which is why there's such a need for machine learning.

Types of Machine Learning
There are three kinds of machine learning algorithms:
Supervised Learning
Much of practical machine learning uses supervised learning.
In this type, the system tries to learn from the previous examples its given. (On the other hand, in unsupervised learning the system attempts to find the patterns directly from the example given.)
Speaking mathematically, supervised learning is when you have both input variables (x) and output variables (y) and can use an algorithm to derive the mapping function from the input to the output.
The mapping function is expressed as Y = f(X).
Example :

Supervised learning problems can be further divided into two parts, namely classification and regression:
Classification: A classification problem is when the output variable is a category or a group, such as “black” or “white,” or “spam” and “no spam."
Regression: A regression problem is when the output variable is a real value, such as “Rupees” or “height.”
Unsupervised Learning
In unsupervised learning, the algorithms are left to themselves to discover interesting structures in the data.
Mathematically, unsupervised learning is when you have only input data (x) and no corresponding output variables.
This is called unsupervised learning because unlike supervised learning there are no given correct answers and the machine itself finds the solutions.
Unsupervised learning problems can be further divided into association and clustering:
Association: An association rule learning problem is the need to discover rules that describe large portions of data, like “people who buy X also tend to buy Y."
Clustering: A clustering problem is the need to discover inherent groupings in the data, such as grouping customers by purchasing behavior.
Reinforcement Learning
This is a particular type of machine learning where the computer program will interact with a dynamic environment in which it must perform a particular goal, such as playing a game with an opponent or driving a car. The program is provided feedback in the form of rewards and punishments as it navigates its problem space.
Using this algorithm, the machine is trained to make specific decisions. It works this way: the machine is exposed to an environment where it continuously trains itself using trial and error method.
Example:


Popular ML Languages For Beginners
Being new to the field of Machine Learning can seem like an overwhelming thing. New terminology, math is involved and now you have to figure out what programming languages to use. Here are five popular languages used widely throughout the ML world.
Python
Python is firmly the top programming language used in machine learning with 57% of data scientists using it. Python is well-known for being platform independent, easily readable and less complex than most languages. Because of this, ML engineers can use the built-in library ecosystem to easily access and handle data. The flexibility Python that offers allows engineers to choose various approaches and minimize errors with relative ease.
Java and Javascript
Java is another popular ML language because it makes it easy for engineers to integrate with existing repositories. Java, with large existing codebases and available open-source tools, makes it a perfect choice for beginners or software engineers looking to get into ML. Java is incredibly fast executing and allows for quick scalability because it’s already such a well-established language amongst most companies.
Though Javascript is primarily used for web development, it can also be easily used to build machine learning models in-browser. TensorFlow, an open-source library, allows a ML engineer to import pre-trained models, retrain models or even create models in-browser using Javascript.
C++
C++ has been a favorite language for AI and ML engineers for decades, specifically when it comes to gaming and robotics. 44% of ML engineers use C++ because of its level of control, efficiency and high performance. C++ is mainly used to build onto existing apps instead of building ones from scratch because the language is slightly more rigid to build with than Python.
R
R is an open source language rooted in data and statistics. It has become a fast favorite of new ML engineers because of its open-source community and support for object-oriented programming. One of R’s greatest strengths as a machine learning language is that it comes with a very large number of user-created extension packages that allow engineers to apply even the most specialized statistical techniques to their datasets.
The Math of Intelligence
Machine learning theory is a field that meets statistical, probabilistic, computer science and algorithmic aspects that arise from learning iteratively from data which can be used to build intelligent applications.
Why Worry About The Math?
The mathematics of machine learning are important for several reasons:
- Selecting the appropriate algorithm for the problem includes considerations of accuracy, training time, model complexity, number of parameters and number of characteristics.
- Identifying underfitting and overfitting by following the Bias-Variance tradeoff.
- Choosing parameter settings and validation strategies.
- Estimating the right determination period and uncertainty.
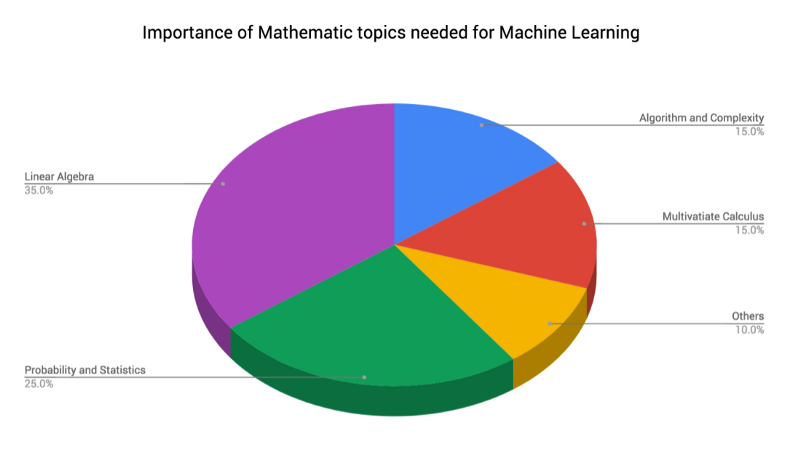
What Level of Maths Do We Need?
What level of mathematical understanding is required to understand machine learning systems? The answer is multidimensional and depends on the level and interest of the individual, but machine learning engineers and data scientists need to know at least the following:
- Linear algebra: Matrix operations, projections, factorisation, symmetric matrices, orthogonalisation
- Probability theory and statistics: Probability rules & axioms, Bayes’ Theorem, random variables, variance and expectation, conditional and joint distributions, standard distributions
- Calculus: Differential and integral calculus, partial derivatives
- Algorithms and complex optimizations: Binary trees, hashing, heap, stack
Vihar Kurama is a machine learning engineer who writes regularly about machine learning and data science.


