

Applying data science to business problems ultimately requires understanding what you are trying to achieve. For example, sales teams attempt to predict and increase revenue. Data science can help by more accurately predicting revenue throughout the quarter. A product team may attempt to build the right set of product features for target personas. Data science can help by analyzing event data from product usage. In these business cases, the first question may be, what is going to happen? How much revenue will our sales team be able to deliver? Do the product features we build resonate with users?
The second question becomes, then, what can I change to get a different result? Do I need to add more salespeople or sell to a different customer? Are users not finding what they need or do we need to build different features?
To answer such questions, this article will help you decide whether you should use deep learning or machine learning to solve different parts of a business problem.
What’s the Technical Difference Between Machine Learning and Deep Learning?
Deep learning is a subset of machine learning and it is helpful to understand high-level technical limitations in order to talk about business problems. There are four important constraints to consider: data volume, explainability, computational requirements and domain expertise.
- Data Volume: Deep learning requires very large amounts of data to perform better than other machine learning algorithms. But before you rule out deep learning entirely, you may be able to benefit from pre-trained deep learning models via transfer learning. This technique allows for refining existing models with smaller data sets after they’ve been trained on much larger data sets. A common use case is in natural language processing: A recent example is using a pre-trained BERT (Bidirectional Encoder Representations from Transformers) model to detect hate speech and racial bias on social media.
- Explainability: The hidden layers in deep learning networks are generally not inspectable. This means that you will not be able to know what your model is learning, or why. You may only be able to infer by using curated test sets to understand the differences in impact. In classical machine learning, data scientists select the features that the model is learning from and can choose models that allow for explainability.
- Computation Requirements: Because deep learning requires very large amounts of data and complex mathematical calculations, it requires the use of specialized hardware to provide results quickly enough for timely use in business use cases. Classical machine learning, however, can use more traditional distributed computing techniques or even just the use of a personal laptop.
- Domain Expertise: Classical machine learning benefits from domain expertise during the feature engineering and feature selection process. All machine learning models learn patterns in the data that is provided, supplying features that have known good relationships can increase performance and prevent overfitting. Deep learning, though, needs more data and does not require domain expertise to train a model because the network will learn what is important in the data. This means that, instead, you’ll need expertise in tuning hyperparameters.
Should You Use Deep Learning or Machine Learning?
Start with the end in mind: Ultimately, what are you trying to achieve? To illustrate how to approach this question, let’s look at predicting customer retention. Before choosing or eliminating deep learning based on the size of data you have, make sure you’re solving the right problem. For example, predicting customer retention is a solution and not what the business is hoping to achieve. Therefore, we need more information about business goals.
What Are You Trying to Achieve with Machine Learning or Deep Learning?
Let’s assume we’re a venture capital-backed, software-as-a-service (SaaS) tech startup selling subscriptions to other businesses (B2B). This means an account is another business and under that account, there are users of our software product. By listing out our B2B SaaS business goals, we can begin to evaluate solutions that might help us achieve those goals.
For instance, some common B2B SaaS business goals include:
- Setting targets for revenue and retention of subscriptions.
- Planning product, marketing and other interventions to achieve those goals.
- Retaining and growing accounts and users of the product and increasing usage.
- Predicting, as time passes, how well you are achieving those goals.
- Intervening with product, marketing and other interventions to get a better outcome.
Approaching these business goals together as a data scientist can change the way we architect solutions that include either deep learning or other machine learning options (or both). Now, instead of looking at the solution as predicting customer retention, we may instead see this as a multiple model system with different goals. The figure below is a simplified business diagram that depicts the continuous nature of software as well as where internal data can be gathered.

How Can Machine Learning Help?
If your example data set is small and you cannot augment it with much larger data sets, then deep learning cannot help.
However, before you come to the conclusion that you have less than millions of subscriptions and default to classical machine learning (or vice versa and default to deep learning), consider this:
Deep Learning vs Machine Learning
- Deep learning provides a prediction or classification without the ability to understand why the model made a decision where some classical machine learning techniques can be understood.
- Classical machine learning models require domain experts to narrow down the set of features to be able to make predictions without overfitting while deep learning can handle massive amounts of data and dimensions.
- You can expand your data by looking at micro retention interactions with users as well as macro retention decisions at the subscription level.
- You can expand your data by appending external information about your accounts and the context your business exists within.
In our example case, say we have just 1,000 subscriptions. But each subscription averages 100 users, we expect users to use the product once a week, the product has three key workflows, and each workflow has two dozen possible feature interactions. Over time your product is also growing. The data can then grow exponentially at the micro-level:
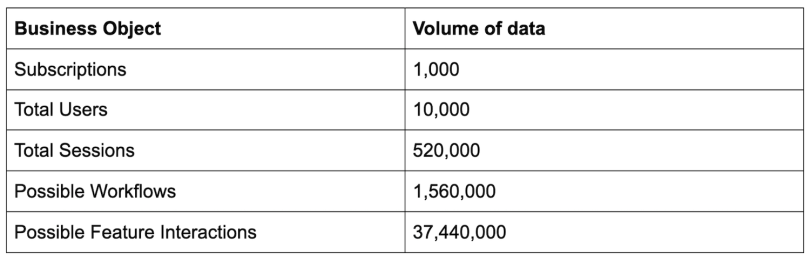
Moreover, marketing data, sales data, social data and advertising data can all dramatically increase the data available for machine learning.
So, if the scale of the data isn’t really an obstacle to making your decision between deep learning and classical machine learning, what is? Whether or not you need to understand why the algorithms are making their predictions.
Let’s revisit the goals. It is possible that, in some goals, it is more important to know what is going to happen instead of why it’s going to happen. In cases where you have the amount of data required to train (or at least use transfer learning to refine) a deep learning algorithm, use it.
In the cases where you need to understand what to change to get a different result, revert to classical machine learning models or use them in addition to deep learning models.
For example, if you want to understand:
- What is going to happen in order to set goals? Use deep learning.
- Why are some businesses buying and not others? Use classical machine learning or a combination.
- Why is usage so low with some customers and not others? Use classical or a combination.
- Is your sales team on target to hit their goal? Use deep learning.
- What intervention is going to change the outcome? Use classical or a combination.
It is common to use these techniques in combination to solve problems and model stacking can often provide the best of both worlds. Maybe a deep learning model classifies your users into a persona label that is then fed to a classical machine learning model to understand where to intervene with the user to retain them in the product. You may use a deep learning model to analyze the sentiment of the feedback collected about your product, which is common in natural language processing topic modeling, and use this sentiment to request a conversation with the user to understand why they are upset.
When you’re trying to decide between deep learning or machine learning, break apart what you’re hoping to achieve and see where you might be able to dive deeper into the technical limitations of various techniques. You might be able to expand the data you thought you had to allow for better outcomes by combining techniques. In both cases, be sure to measure the impact that your models have over time, otherwise, you could introduce unintentional consequences.


