

At Doximity, the largest community of healthcare professionals in the US, we work every day on challenging natural language processing (NLP), recommendation and classification modeling problems. As our data team grows to solve more sophisticated problems considering machine learning (ML) as a possible solution, we have created a recommended process to manage risk, enable cross-team learning, and encourage best practices.
In this two-part article, we’ll share what we’ve learned and encourage a reactive approach to risk management for ML, yielding smaller, incremental projects over large, revolutionary ones. Moreover, this method of risk management is also adopted in Agile software development, from which most current R&D processes derive. In this article, we will use Agile as inspiration to structure modeling processes that are traditionally experimental. In the follow-up post, we will discuss details of a proposed modeling life cycle structured on Agile principles and reactive risk management.
Our ambition isn’t exactly easy, due to the inherently experimental nature of modeling projects. The work between each stage can be highly interdependent, such that the completion of one stage may be invalidated by a result in the subsequent stage. Thus in the ML project life cycle, we are not talking about a single cycle, but various loops that can be initiated from any stage of an ML project.
We propose to NOT consider deployment as the final stage of a modeling project but instead an experiment report. That is, what’s delivered at each cycle is not a feature, a model, or a piece of code but a range of results on the data documented in an experiment report.
Agile Development as Reactive Risk Management
To illustrate, let’s first consider the traditional software development lifecycles (below). In a high investment, long-term project, like a NASA rocket launch, it is sensible to mitigate all risks early through the waterfall development process. We call this a proactive risk management approach. Hypothetical risks are identified, and solutions are determined primarily during the design phase, prior to the expensive investment of labor and materials. Once we arrive at the development and subsequent phases, the solution has been committed. This is a sensible and necessary process for projects in fairly stable environments (physics) with high investment (labor, materials, and fuel) and a high cost of failure (failed rocket launches mean the total destruction of the product and potential loss of life).
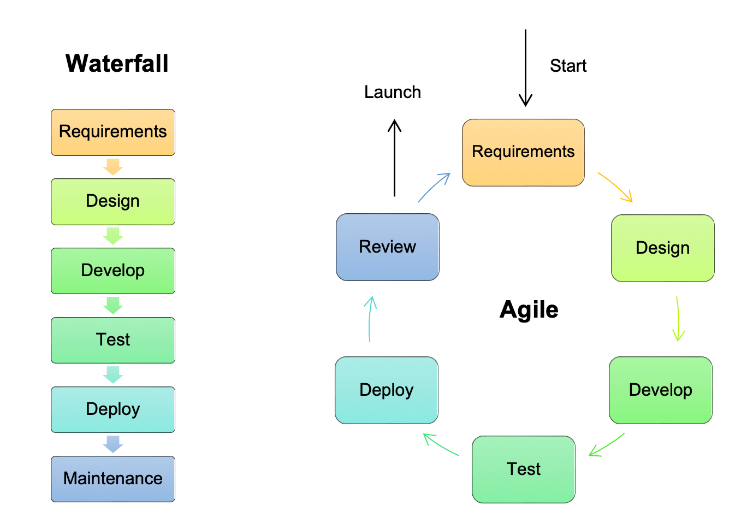
However, these requirements and benefits do not apply well to software development today. In a commercial software market, behaviors can change frequently and dramatically. The proactive risks assessed last year may be completely invalid this year. Conversely, the cost of delayed deployment is ever-increasing as competitors grow and the first-to-market advantage increases. Meanwhile, the capital investment in development is ever-lowering as workstations become consolidated into laptops and servers virtualized onto the cloud. Thus, in this highly volatile, quick-to-respond, low-cost environment, it is more sensible to embrace the uncertainties and respond to them. This is the reactive risk management for which we advocate. By utilizing small, heterogeneous teams with incremental, iterative deliverables, the process reduces the reaction time to changes, thereby increasing flexibility.
We believe that modeling projects need to embrace the business world’s inherent uncertainty. Thus, we propose a process with smaller iterative deliverables rather than a fully-working, sufficiently effective model.
Defining a Model Iteration
Before we outline our procedure, we should also consider the different variations of model iteration. We focus on three main aspects: algorithm, feature, and data changes. Each of these has different risks and thus requires different amounts of work and are inspired by the major, minor and patch differentiation in semantic versioning.
1. Algorithm Change Iteration
An algorithm change is analogous to a major version in semantic versioning. It occurs when we want to try a different algorithm (e.g., from random forest to gradient boosting) or platform (e.g., from scikit to Spark ML) used for modeling. Depending on the nature of the change, training and deployment might need to be heavily reworked. Feature and model evaluation will likely be redone, and large-scale model tuning is required.
2. Feature Change Iteration
A feature change is analogous to a minor version update in semantic versioning. It occurs when we want to add or remove feature(s) from the mode. Most of the training, evaluation and deployment pipelines are reused however, data balancing or imputation might need to be reapplied. Depending on the number and scale of feature changes, feature evaluation might need to be redone, and minor model tuning is needed for local optimization.
3. Data Change Iteration
A data change is analogous to a patch in semantic versioning. It occurs when we change the labeled data used for training with the latest data or a larger set. Existing training, evaluation, and deployment pipelines are reused however, data balancing or imputation might need to be reapplied. Depending on the dataset, model tuning may be required.
Introducing the Agile Modeling Lifecycle
Considering the different scopes and risks we’ve outlined, we propose a modeling lifecycle process where a report is generated and reviewed with the team at the end of each iteration. At that point, the stakeholders can decide whether to invest in the next iteration. The following roughly describes this process; note that, depending on the change scope, not all stages are necessary.
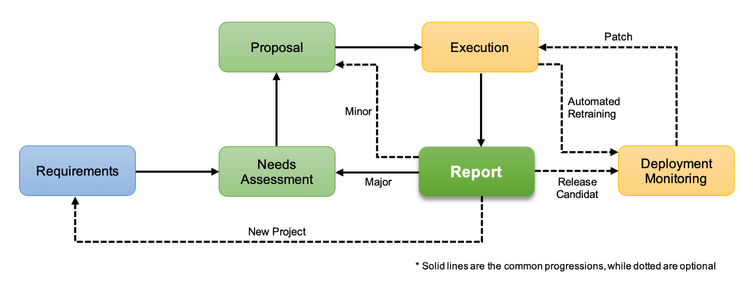
The blue stage designates the product/business task, the green indicates documentation, and the yellow identifies technical tasks. The cyclical relation of the green and yellow stages demonstrates the process’ iterative nature, with each cycle (iteration) consisting of a clearly defined experiment and corresponding version designation.
We would like to leave the reader with two key observations:
- Not all experiments will warrant a deployment.
- The iteration report, written by a data scientist or a machine learning engineer, is the most significant stage of the proposed process.
In the follow-up post, we will discuss each of the proposed stages in detail and also describe how the major, minor and patch iterations enable agile principles and reactive risk management.


