

Apache Kafka is a distributed streaming platform designed to handle large volumes of real-time data. It’s an open-source system used for stream processing, real-time data pipelines and data integration. LinkedIn originally developed Kafka in 2011 to handle real-time data feeds. It was built on the concept of publish/subscribe model and provides high throughput, reliability and fault tolerance. It can handle over a million messages per second, or trillions of messages per day.
Kafka is a critical tool for modern data feeds. As data continues to grow every day, we need tools to handle massive amounts of data. This introduces two challenges: First, how to collect a large amount of data, and second, how to analyze the collected data. To overcome these challenges, we need a messaging system.
What Is Kafka?
Apache Kafka is an open-sourced distributed streaming platform designed to handle large volumes of real-time data. It’s become a critical tool for modern data feeds as it helps them transfer data between applications and analyze the data to decide how to share it.
A messaging system helps to transfer data between applications. It helps applications to concentrate on data and the messaging system decides how to share the data.
Let’s take the data pipeline below. We have a source system and a target system, and we exchange the data between them. It looks pretty simple, right?

The source system can be any system such as an app, email, financial data, streaming data etc. The target system can also be any system such as a database, email or analytics, etc. We’ll call them the source and target systems in this article for easy illustration.
What happens if we have multiple sources and target systems, and they all have to exchange data with one another? For example, let’s assume we have five sources and four target systems as below.
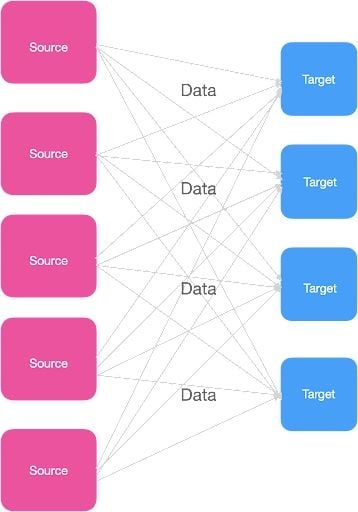
To exchange the data, each source system has to connect with the target system, which results in multiple integrations across the source and target systems. Each integration also comes with various difficulties, as follows:
- How the data is transported.
- How to format the data (parsing).
- Data schema and evolution (shape of the data in the future).
- Increasing load whenever we connect the source and target system.
It looks pretty messy, right? This is where Apache Kafka comes into the place.
What Is Kafka?
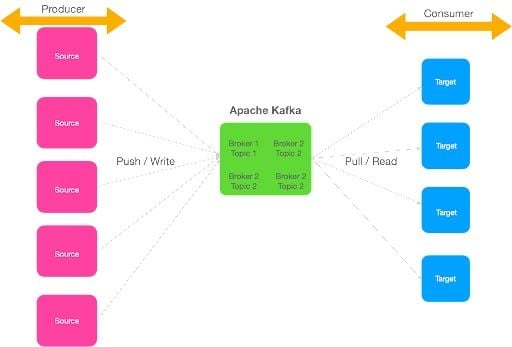
Let’s take our earlier example and integrate it through Apache Kafka.
We can see from the image above that Apache Kafka helps us to decouple the source and target system. Source systems are called producers, which can send multiple streams of data to the Kafka brokers. Target systems are called consumers, where clients can read the data from the brokers and process it. Multiple consumers can read the same data; it’s not limited to one single destination. Source and target systems are completely decoupled, avoiding complex integrations.
There are two types of messaging systems companies can use: Point-to-point and publish-subscribe messaging systems. In a point-to-point system, producers persist data in a queue and only one application can read the data from the queue. The message gets removed from the queue once this system reads the data.
In the publish-subscribe messaging system, consumers can subscribe to multiple topics in the message queue and receive specific messages relevant to their application. Apache Kafka is based on a publish-subscribe messaging system.
How Does Kafka Work?
Kafka is made up of six components. It’s important to understand how each of the components in Apache Kafka work together because they form the foundation of the system and also helps to effectively store and process data streams. These include:
- Producer: A producer generates a large amount of data and writes this into Kafka.
- Consumer: Consumers act as end-users that read data from Kafka that comes from producers.
- Topic: Topic is a category or label on which records are stored and published. All Kafka records coming from producers are organized into topics. Consumer applications read from topics.
- Brokers: These are the Kafka servers that handle the data. Kafka brokers receives message from producers and stores them on its data
- Partition: This is a unit of data storage. It’s a sequence of messages that is stored in a log and is identified by a unique ID, known as the partition offset. Each partition is ordered and immutable, meaning that once a message has been written to a partition, it cannot be modified or deleted. A topic can have multiple partitions to handle a larger amount of data.
- Zookeeper: This is a centralized service that is used to coordinate the activities of the brokers in a Kafka cluster. It is responsible for maintaining the list of brokers in the cluster and facilitating leader election for partitions.
The above six components provide a distributed, scalable and durable system for storing and processing streams of data in Apache Kafka.
What Is Kafka Used For?
Apache Kafka is used by a wide range of companies and organizations across various industries that need to build real-time data pipelines or streaming applications.
Developers with a strong understanding of distributed systems, data streaming techniques and good programming skills should take the time to become familiar with Apache Kafka. It’s written in Java, and it provides client libraries for other languages, such as C/C++, Python, Go, Node.js and Ruby. Primarily, software engineers, data engineers, machine learning engineers and data scientists work on Apache Kafka in the organization.
Below are some of the common use cases for Kafka across different industries.
E-Commerce
Kafka is often used to process real-time streams of data from customer interactions, such as purchases, browsing behavior and product reviews.
Financial Services
Kafka is often used to process real-time streams of financial data, such as stock prices and transactions, to enable real-time analysis and decision-making.
Internet of Things (IoT)
Kafka can be used to process real-time streams of data from IoT devices, such as sensors and smart home devices, to enable real-time analysis and actions.
Telecommunications
Kafka can be used to process real-time streams of data from telecom networks, such as call logs and network usage, to enable real-time analysis and optimization.
Social Media
Kafka can be used to process real-time streams of data from social media platforms, such as user posts and interactions, to enable real-time analysis and personalized experiences.
Building Event-Driven Architectures
Kafka can be used as the backbone of an event-driven architecture, where it acts as the central hub for receiving and distributing events between different applications and services. This can enable applications and services to communicate and react to events in real-time, making them more flexible and scalable.
Advantages of Kafka
Overall, any company that needs to process and analyze large volumes of real-time data may benefit from using Apache Kafka.
Some of its other advantages include:
- High performance: Kafka helps the platform to process messages at a very high speed. The processing rates can exceed beyond 100k/seconds (low latency). It maintains stable performance under extreme data loads (Terabytes of messages are stored). The data is processed in a partitioned and ordered fashion.
- Scalability: Kafka is a distributed system that can handle large volumes of data that can scale quickly without downtime. It provides scalability by allowing partitions to be distributed across different servers.
- Fault Tolerance: Kafka is a distributed system consisting of several nodes running together to serve the cluster. This distribution makes it resistant to a node or machine failure within the cluster.
- Durability: The Kafka system is highly durable. The message in Kafka can be persisted on disk as quickly as possible.
- Easy accessibility: Data can be easily accessible to anyone as all our data gets stored in Kafka.
- Eliminates multiple integrations: It eliminates multiple data source integrations as all a producer’s data goes to Kafka. This reduces complexity, time and cost.
Disadvantages of Kafka
Kafka isn’t perfect. Some of its disadvantages include:
- Not suitable for historical data: Kafka system doesn’t allow storing historical data for more than a few hours.
- Slow behavior: Kafka system becomes slow when the number of queues in a cluster increases.
- Lack of monitoring tools: Kafka system doesn’t have a complete set of monitoring and managing tools. To overcome this, we can use third-party tools like Kafka Monitor (developed by LinkedIn), Datadog and Prometheus help to monitor Kafka clusters. In addition, there are many other open-source and commercial options also available.
- No wildcard topic support: Kafka system only supports the exact topic name and won’t support wildcard topics. So, for example, if you have a topic
metric_2022_01_01 & metric_2022_01_02, then it won’t support wildcard topic selection likemetric_2022_*. - Reduces Performance: Brokers and consumers start compressing and decompressing the messages when their size increases. This will reduce the Kafka system’s performance and affect its throughput.
Frequently Asked Questions
What is Kafka?
Apache Kafka is an open-source event streaming platform that can capture and manage large amounts of real-time data at scale. It is a distributed software system made up of clusters of servers and clients.
Kafka works to facilitate event streaming, which refers to the continuous flow and interpretation of data from multiple sources like databases, mobile devices and software applications.
What is Kafka used for?
Apache Kafka is used to write, read, store and process streams of event data in real time, and is often utilized to build data pipelines and data integration technologies.
Some Kafka use cases include operational metrics and monitoring, log aggregation, event sourcing and being a message broker.
What is the difference between Apache and Kafka?
"Apache" in Apache Kafka signifies the software as a project developed under the Apache Software Foundation. "Kafka" is the event streaming platform and software itself.


