

Hashing is the practice of transforming a given key or string of characters into another value for the purpose of security. Although the terms “hashing” and “encryption” may be used interchangeably, hashing is always used for one-way encryption. Encryption always offers a decryption key, whereas hashed information cannot be decoded easily and is meant to be used as a method for validating the integrity of an object or piece of data.
What Is Hashing?
Hashing is the practice of transforming a given key or string of characters into another value for the purpose of security. Unlike standard encryption, hashing is always used for one-way encryption, and hashed values are very difficult to decode.
What Is Hashing Used for?
Hashing is primarily used for security purposes — specifically cybersecurity. A hashed value has many uses, but it’s primarily meant to encode a plaintext value so the enclosed information can’t be exposed. The hashing process is non-reversible or extremely difficult to decode, making it a popular cryptography technique.
Some of the most common applications of hashing in cybersecurity are:
- Message integrity
- File integrity
- Password validation
- Blockchain and transaction validation
Each of these use cases relies on the core function of hashing: to prevent interference or tampering with information or a file.
What Is Hashing in Data Structure?
Hashing in data structure refers to using a hash function to map a key to a given index, which represents the location of where a key’s value, or hash value, is stored. Indexes and values are stored in a hash table (or hash map) data structure, which is similar in format to an array. In hash tables, each index coincides with a specific key value to help retrieve key-value pair data and their elements quickly.
What Is a Hash Collision?
A hash collision is when two different keys generate the same index and key value. Collisions can happen if there are more keys to hash than there are value slots available in a database. Methods known as collision resolutions are used to resolve hash collisions, with the most common methods being open addressing (closed hashing) and separate chaining (open hashing).
Open Addressing
In open addressing, all keys and values are stored directly in the same hash table, so an equal number of keys and value slots remains and no overlapping occurs. To accomplish this, linear probing, quadratic probing or double hashing is used. With linear and quadratic probing, slots in a hash table are “probed” or looked through until an empty slot is found to store the colliding key value. With double hashing, two hash functions are applied, where the second function offsets and moves the colliding key value until an empty slot is found.
Separate Chaining
In separate chaining, a slot in a hash table would act as a linked list, or a chain. One slot and index would then be able to hold multiple key values if a collision occurs. However, every index will have its own separate linked list in separate chaining, meaning more storage space is required for this method.
Hashing and Message Integrity
The integrity of an email relies on a one-way hash function, typically referred to as a digital signature, that’s applied by the sender. Digital signatures provide message integrity via a public/private key pair and the use of a hashing algorithm.
To digitally sign an email, the message is encrypted using a one-way hashing function and then signed with the sender’s private key. Upon receipt, the message is decrypted using the sender’s public key, and the same hashing algorithm is applied. The result is compared to the initial hash value to confirm it matches. A matching value ensures the message hasn’t been tampered with, whereas a mismatch indicates the recipient can no longer trust the integrity of the message.

Hashing and File Integrity
Hashing works in a similar fashion for file integrity. Technology vendors with publicly available downloads often provide what are referred to as checksums. Checksums validate that a file or program hasn’t been altered during transmission, typically a download from a server to your local client.
Checksums are commonly used in the IT field when professionals are downloading operating system images or software to be installed on one or more systems. To confirm they’ve downloaded a safe version of the file, the individual will compare the checksum of the downloaded version with the checksum listed on the vendor’s site. If the two values match, the file is trustworthy. If they don’t match, the file may not be safe to use.
As with digital signatures, a checksum is the output of a hashing algorithm’s application to a piece of data — in this case, a file or program. Checksums are common in the technology industry for verifying files and helping security vendors track the reputation of files. The checksums, or hash values, of malicious files are stored in security databases, creating a library of known bad files. Once a piece of malware is tagged in a reputation database and that information is shared across vendors in the industry, it is more difficult for the malicious file to successfully be downloaded or run on a protected system.
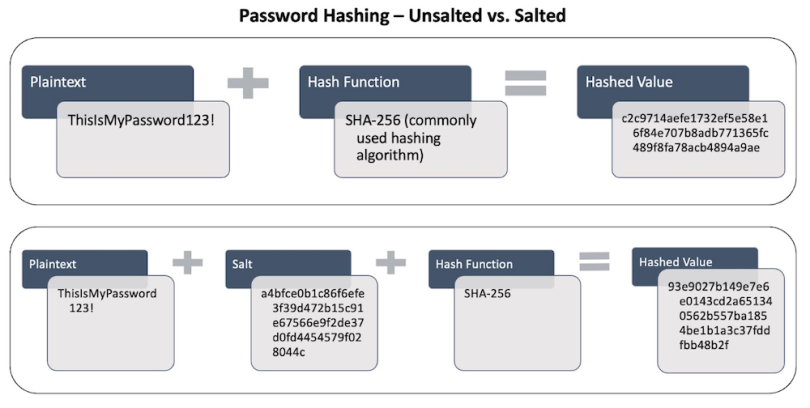
Hashing and Password Validation
When you enter your password to log in to a device or account, the system isn’t validating your password directly. Instead, it’s hashing what you’ve entered and then comparing it with the hash value stored in the system or back-end database.
Historically, passwords were stored in plaintext. This meant the system or back-end server of the site you were logging into had the plaintext value of your password stored in a file or database. As computers became common household items and the boom of the internet led to more online activity, security researchers quickly realized plaintext passwords wouldn’t suffice when it came to information privacy and protection.
Today, most systems store hashed values of your password within their databases so that when you authenticate, the system has a way to validate your identity against an encrypted version of your password.
For additional security, some systems (Linux-based ones, for instance), add a salt, which is a 32-character string, to the end of the password before it’s hashed. This step prevents two of the same hashes from occurring as a result of two people having the same password, like “Pa$$word123.” By adding a unique salt to each, it’s impossible for the two hash values to be the same. The salting of passwords also makes them much harder to crack, which is valuable in the event of a data breach.
Hashing and Blockchain
Blockchain is a modern technology that enables efficient and immutable transactions. It has many uses, including cryptocurrency, NFT marketplaces and international payments. Blockchains operate in a peer-to-peer fashion where the transactions are recorded and shared across all computers in the blockchain network. But how exactly can transactions be made immutable? Enter cryptographic hashing.
Hashing within a blockchain works the same as it does for other use cases: A hash function is applied to a data block to provide a hashed value. The difference is that blockchains use nonces, and each transaction requires the additional data block to be hashed. A nonce is a random or semi-random number that’s used once and serves to prevent replay attacks within a blockchain. Replay attacks occur when an attacker intercepts communication occurring across a network and then retransmits that communication from their own system. This can significantly impact the security of a blockchain, so the use of nonces helps to prevent successful attacks.
As mentioned, each transaction results in a new data block that must be hashed. Hash functions come into play in various ways throughout the continuous loop that is the blockchain.
First, each block includes the value of the hashed header of the previous block. Before the new transaction is added, the header of the previous block is validated using that hash value. Like message and file integrity, the blockchain uses hash values to perform similar validation to ensure previous data blocks haven’t been tampered with.
Once that’s validated, the new data block is added, along with a nonce, and the hashing algorithm is applied to generate a new hash value. This process creates a repeated cycle of hashing that’s used to protect the integrity of the transactions.
Advantages of Hashing
Besides granting users peace of mind, hashing comes with several perks involving the security and efficiency of storing data.
Faster Retrieval
Hashing assigns a key to each value, making it easier to track down specific strings of characters. It also lets users compare two files without ever opening them, speeding up the process of identifying individual documents.
Increased Security
Hashing uses one-way encryption, meaning it is very difficult to decode. There’s also the option to add a string of characters to the end of passwords before they’re hashed, making it even more tedious to crack hashed information.
Improved Data Integrity
Modifying data that has already been hashed will produce an entirely brand-new hash. This allows organizations to detect if any changes have been made and avoid using documents, files and other information that could be compromised.
Reduced Storage and Memory Needs
Hashing stores data in a finite space, using up limited memory in the process. And because each value is paired with a unique hash, hashing can be used to track down and delete duplicate data. These attributes of hashing enable companies to maximize their storage space.
Disadvantages of Hashing
Hashing enhances the security of data, but there are still some security vulnerabilities and operational costs to keep in mind.
Chances for Collisions
While hashing is designed to prevent two inputs from generating the same hash value, collisions can still happen. Hash functions also consist of a fixed string of characters, limiting their output range and raising the odds of a collision when there’s a large number of inputs.
Limits to Performance
Working with complex data or massive volumes of data can turn hashing into a resource-intensive process. This can slow down the performance of a hashing function and lead to major backlogs.
Gaps in Security
Hashed data is designed to be nearly impossible to decode, but there’s still a possibility advanced techniques can reverse-engineer the process. Poorly done hashing can also produce weaker protection and expose data to a wider range of cyber attacks.
Elements Out of Order
Hash tables do not account for the order of elements. As a result, hashing is not the best method if a task involves entering and retrieving elements in a particular order.
Hashing Origins
The idea of hashing was introduced in the early 1950s by IBM researcher Hans Peter Luhn. Although Luhn didn’t invent today’s algorithms, his work ultimately led to the first forms of hashing. His colleagues presented him with a challenge: They needed to efficiently search a list of chemical compounds that had been stored in a coded format. Luhn knew there must be a way to improve information retrieval for cases like this, and so the process of indexing was born.
Over the next 30 years, scientists built upon his invention of indexing to develop a way to codify plaintext, known as hashing. Hashing requires two components: a plaintext value and a hashing algorithm. The application of the algorithm against the plaintext value results in a hashed output.
Why Hashing Is Important
Hashing continues to be a valuable security mechanism for making data unreadable to the human eye, preventing its interception by malicious individuals, and providing a way to validate its integrity. Over the years, hashing algorithms have become more secure and advanced, making it difficult for bad actors to reverse engineer hashed values. Although hashes will always be crackable, the complex mathematical operations behind them along with the use of salts and nonces make it less possible without massive amounts of computing power.
Frequently Asked Questions
What is hashing?
Hashing is a one-way process that uses an algorithm to transform input data of any size into a value of fixed length. This action is designed to be nearly impossible to reverse or decode, making hashing a key technique in the realm of digital security.
What is hashing in cybersecurity?
In cybersecurity, hashing is the process of converting input data like a file, document or password into a string of indecipherable characters. The process is one-way and acts as a digital fingerprint, allowing users to track and verify data.
What is an example of hashing?
Entering a password for a website account is a common example of hashing. During this process, the system compares the input data with a hash value that’s already stored in the password database. If there’s a match, a user is granted access to the account.
What is hashing vs. encryption?
Hashing and encryption are used interchangeably, but there are clear distinctions between the two. Hashing relies solely on one-way encryption, making it difficult to undo the process. Meanwhile, encryption is a two-way process that comes with a decryption key. The two techniques can then complement each other as part of a company’s security strategy.


