

A robots.txt file is a simple text file that communicates with web crawlers — also known as bots or spiders — about which parts of a website they are and aren’t allowed to access. It serves as a bridge between website owners and automated crawlers, helping to manage traffic, optimize SEO performance and protect sensitive areas of a website.
Robots.txt Definition
A robots.txt file is a text file instructing web crawlers on which parts of a website they can and cannot access.
Robots.txt files are part of the robots exclusion protocol (REP), a standard that web administrators use to control how search engines index and interact with their websites. While not legally required, most reputable bots respect the instructions outlined in these files.
What Is a Robots.txt File?
Introduced by software engineer Martijn Koster in an early-internet-adopters mailing list in 1994, robots.txt files are text-based files that tell web crawlers which parts of the site they may access. They are located in the source files of most websites, allowing site owners to control how their content is crawled and indexed. Although they are not followed by all crawlers — such as malicious bots — most search engines and automated systems adhere to the rules outlined in a robots.txt file.
The syntax (or computer language) of a robot.txt file is fairly straightforward, often including terms like:
- User-agent denotes the specific web crawler being instructed (Googlebot, Bingbot, Yandex Bot etc.). For example, if the instructions are for Google, it would be written as “User-agent: Googlebot”.
- Disallow tells the user-agent not to crawl a particular URL. This can be a specific file or page, or an entire section of a website. For example, “Disallow: /checkout/” would prevent a crawler from accessing a site’s checkout page.
- Allow tells Googlebot specifically it can access a page or subfolder, even if its parent page is disallowed.
- Sitemap specifies the location of any XML sitemaps associated with the URL, helping crawlers understand the site’s structure and find content more efficiently. For example “Sitemap: https://builtin.com/sitemap.xml” points to Built In’s XML sitemap.
- Crawl-delay specifies how long (in milliseconds) a bot should wait before indexing a page. For example “Crawl-delay: 5” means the crawler should wait 5 milliseconds. This helps prevent the server from being overtaxed, which can slow down a website. While Google does not recognize this command, other search engines do.
Examples of a Robots.txt File
Companies customize their robots.txt files to emphasize certain areas of their websites, protect user privacy and highlight their brand identities.
Cloudflare
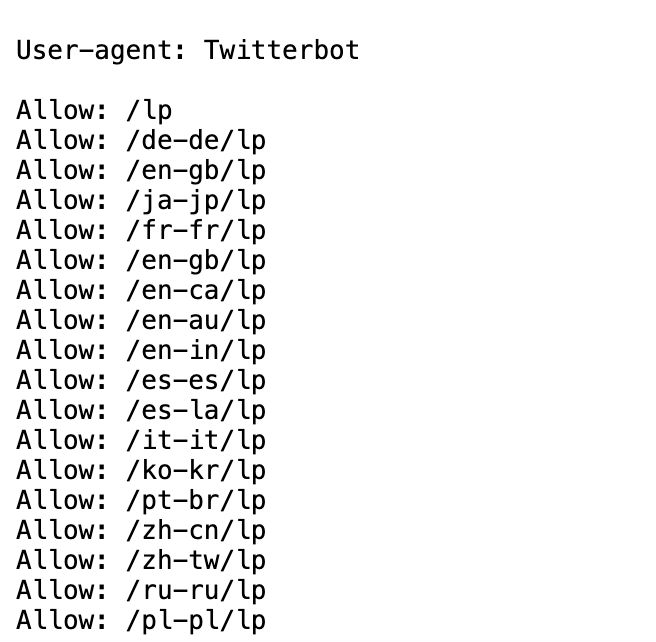
Cloudflare’s robots.txt files direct bots to crawl their regional and language-specific pages. This helps the website rank across geographic regions.
YouTube
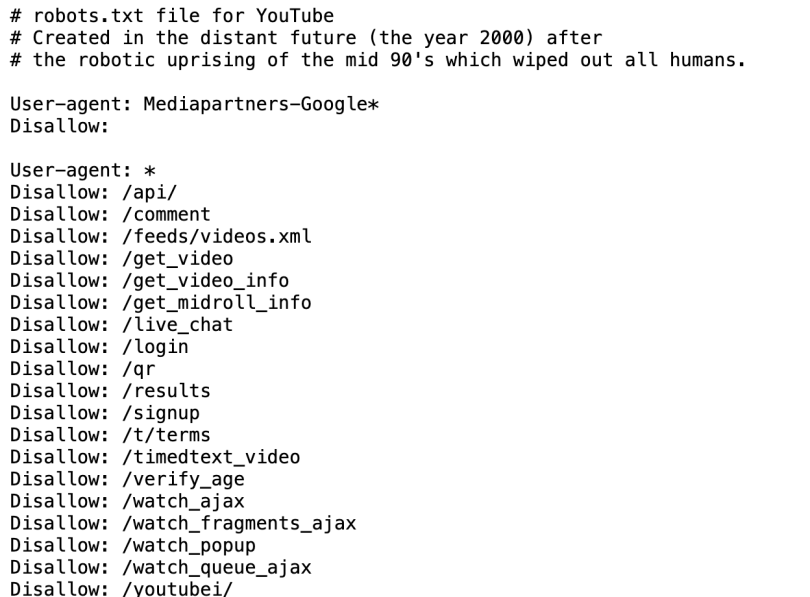
YouTube directs bots away from user login pages, chat logs and its age verification page, among others. It also includes a fictional message that addresses robots in a dystopian future in which humans have been “wiped out” by a robot uprising.
Nike
Nike’s robots.txt file blocks crawling in areas of its site like individuals’ inboxes, settings and shopping carts. It even uses the “#” symbol — which tells crawlers to ignore the text that follows — to include its signature Nike swoop. This is a common practice among developers who want to incorporate notes or easter eggs within their robots.txt files.

TikTok
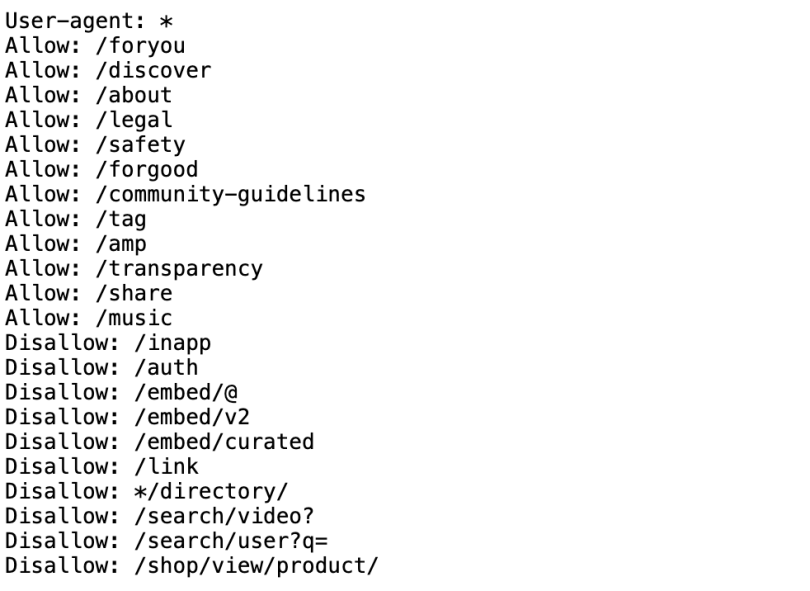
TikTok directs bots to crawl its For You page, community guidelines and “share” page, while disallowing spiders to crawl specific users and their search history.
Google’s extensive robots.txt file includes explicit rules for large language model (LLM) bots, barring those powering tools like ChatGPT and Claude AI from scraping the website to collect training data.

How Does a Robots.txt File Work?
Search engine crawlers have two primary objectives: finding content on the web and indexing it so it can appear in search results. They use robots.txt to navigate through websites. This process involves:
- Locating the robots.txt file: When a crawler visits a website, it looks for a robots.txt file at the root level.
- Reading the rules: If the file is found, the crawler parses through its instructions line by line, determining which areas of the site it can and cannot access.
- Accessing the site: The crawler follows the directives (unless it’s been maliciously programmed to ignore them), indexing or skipping parts of the site based on the rules.
How to Find a Robots.tx File
To locate a website’s robots.txt file, go to the root URL of the domain and add /robots.txt. For example, https://www.builtin.com/robots.txt will direct you to Built In’s robots.txt file. You can open the URL in a browser or use tools like cURL or online robots.txt validators. If a robots.txt file is absent, crawlers will assume they can access all publicly available content.
Robots.txt Protocols
A protocol is the format for providing instructions in a network setting. Robots.txt files follow several protocols to function correctly, including:
- Placement: The file must be located at the domain’s root — https://www.builtin.com/robots.txt, for example. Subdomains require their own file, such as https://builtinaustin.com/robots.txt.
- Case sensitivity: The file name must be lowercase for crawlers to recognize it.
- Syntax: Each directive should follow a structured format. Errors like misspellings or misplaced symbols can render the file ineffective.
- Wildcards: Asterisks (*) are used to denote “all,” while the dollar sign ($) is used to mark the end of a URL. These symbols are called “wildcards” within the context of a robots.txt file.
- Priority: Specific rules for individual crawlers take precedence over general ones. For example, webmasters might specifically include “User-agent: Googlebot” versus “User-agent: *” to specifically guide Google’s crawlers through their site.
Best Practices for Robots.txt
These best practices help web admins manage how bots access their site, optimizing interactions and data security.
- Test files regularly: Use tools like the robots.txt tester in Google Search Console to ensure directives are functioning correctly.
- Leverage sitemaps: Include links to sitemaps in the robots.txt file to help search engine crawlers discover and index pages efficiently.
- Place in the root directory: Always store the robots.txt file in the main folder of the website, where all files needed for the site to run properly are stored.
- Ensure domain and protocol accuracy: Remember that a robots.txt file applies only to the specific domain and protocol (HTTP or HTTPS) where it resides.
- Understand search engine behavior: Different search engines interpret directives in their own way. Prioritize specificity in rules, especially for Google, where the most specific directive takes precedence.
- Avoid Crawl-Delay Directives: Refrain from using the crawl-delay directive, as it can cause unintended issues with search engine crawling.
- Focus on SEO Value: Make important pages crawlable, and block pages that do not contribute value to search results.
- Use Correct Capitalization: Pay attention to the capitalization of directory, subdirectory and file names in robots.txt directives, as incorrect capitalization could cause bots to misinterpret or ignore instructions.
- Name the File Correctly: The file must be named “robots.txt” with no variations.
Why Is a Robots.txt File Important?
Robots.txt serves several important functions.
Controls Crawl Budget
Search engines have a limited crawl budget for each site. By implementing a robots.txt file, web admins can make sure the most relevant pages are indexed by blocking less critical sections. If a website has more pages than its crawl budget can handle, important pages might not get indexed and ranked.
Protects Sensitive Data
Although they shouldn’t be relied upon for security, robots.txt files can dissuade crawlers from accessing sensitive areas like admin dashboards or test environments.
Prevents Duplicate Content Issues
Crawl bots don’t need to sift through every page of a site because not every page is designed to appear on a search engine results page (SERP). By restricting access to certain duplicate pages, robots.txt files can help web admins improve their SEO and prevent dilution of search rankings.
Optimizes Server Resources
Blocking unnecessary crawlers can reduce server strain, helping to ensure websites remain accessible to legitimate users.
Limitations of Robots.txt
Do Not Provide Security
Robots.txt files provide guidance, not protection. Sensitive areas of a website should be secured using authentication, encryption or other measures to prevent unauthorized access, as relying solely on robots.txt files for protection is not sufficient.
Can Be Ignored by Malicious Bots
Some bots ignore robots.txt directives, indexing restricted or sensitive areas of a website that are meant to be excluded. To combat this, web admins can enact additional security measures like server-level blocking or CAPTCHA requirements.
May Block Important Web Pages
Robots.txt files can accidentally block important web pages from being crawled or indexed if the directives are overly broad or incorrectly configured. This can significantly reduce organic traffic by preventing search engines from displaying those pages in search results.
Exclude Certain Rules
Not all bots interpret robots.txt directives the same way. For example, Google does not support the crawl-delay directive, which may result in pages being crawled more frequently than intended. This inconsistency can lead to unintended crawling behavior, potentially impacting server performance or exposing pages you intended to restrict.
Alternatives to Robots.txt Files
Robots.txt files aren’t the only tools for guiding search engines — meta robots tags and x-robots tags also tell search engines how to handle a website’s content in specific contexts.
Meta Robot Tags
Meta robots tags are snippets of code within the “<head>” section of individual web pages that provide page-specific instructions on whether to index and crawl links within each page.
X-Robot Tags
Located in the HTTP header of non-HTML files, x-robot tags are code snippets used for files like images and PDFs.
Frequently Asked Questions
What is robots.txt used for?
Robots.txt guides web crawlers on which areas of a website they can access.
Is a robots.txt file necessary?
No, but robots.txt is highly recommended for managing crawler behavior and optimizing site performance.
What happens if you don’t use a robots.txt file?
Without a robots.txt file, crawlers may index the entire site. This can strain servers, create security risks and diminish SEO.
Is robots.txt legal?
Robots.txt is a widely accepted standard, but it is not legally binding. Compliance depends on the web crawler’s integrity.


