
 Function in Python With Examples")
Are you feeling overwhelmed by data scattered across a million spreadsheets? You’re not alone. Whether you’re a coding rookie or a seasoned developer, understanding pandas.concat() is like adding a superpower to your Python toolkit — but let’s start at the beginning.
Pandas, a powerful, open-source library built on top of the Python programming language, helps you handle, analyze, and visualize data efficiently. The pandas.concat() function concatenates and combines multiple DataFrames or Series into a single, unified DataFrame or Series.
Its flexibility and efficiency make it a valuable tool for anyone working with data analysis and manipulation in Python. The key to using pandas.concat() lies in understanding your data and using the appropriate join options to create a meaningful and accurate combined dataset.
So, no matter if you’re a data newbie feeling lost in the Python jungle or a seasoned analyst swamped in siloed information, this guide is your fast track to data harmony.
Let’s break down the function, looking into the values it can return, examples of its use, and alternative functions. Time to dive in.
Pandas.concat() Function Syntax
The basic syntax for the concat() function within a Python script is:
pandas.concat(objs, *, axis=0, join='outer', ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
sort=False, copy=None)Pandas concat() Parameters
objs: This is the sequence or mapping of Series or DataFrame objects you want to concatenate.axis: This specifies the axis along which the concatenation will occur. By default, it is set to zero, which means concatenation along rows. If you want to concatenate along columns, you can adjust this setting.join: This specifies how to handle the overlapping labels along the specified axis. It can take values like “outer” (default), “inner,” “left,” or “right.”ignore_index: If set to True, it will reset the resulting object's index, but the default value is False.keys: This parameter lets you build a hierarchical index in either a sequence or mapping.levels: This lets you configure the levels that make up the resulting hierarchical index.names: This provides names for the levels generated.verify_integrity: If True, it checks whether the new concatenated axis contains duplicates. If it does, it raises aValueError. The default is False, however.sort: If True, it sorts the resulting DataFrame or Series by the keys.copy: If set to False, it avoids copying data unnecessarily.
Pandas concat() Default Values
axis: 0join: 'outer'ignore_index: Falseverify_integrity: Falsesort: Falsecopy: None
When to Use the Pandas.concat() Function
Put simply, users employ the concat() function in the Pandas library when there’s a need to concatenate two or more Pandas objects along a particular axis, meaning either rows or columns. And there are various circumstances when the concat() function comes in handy. Here are some examples.
- Building comprehensive data sets: Say you’ve got data scattered across different sources and want to create a complete data set. Concatenating allows you to merge these data sets, creating a unified and holistic view of your information.
- Time-series data: Users can easily concatenate DataFrames with chronological information, ensuring a smooth flow of time-related insights.
- Handling missing data: When dealing with missing data, the
concat()function lets you cleverly fill in the gaps, combining DataFrames with complementary information to create a more complete data set.
Although pandas.concat() is a fantastic function, there are some circumstances in which it isn’t ideal. For instance, concatenating massive DataFrames can be resource-intensive; users should consider alternative approaches like merging or appending if performance is critical.
Furthermore, users must ensure their DataFrames or Series have compatible columns and data types before concatenating, as mismatched data can lead to errors or inaccurate results.
Pandas.concat() Examples
Now, let’s look at some examples of pandas.concat() in practice.
1. pandas.concat() to Concatenate Two DataFrames
For example, imagine you work for a real estate agency, and you have two DataFrames:
- DataFrame One contains information about listed properties, including address, price, square footage, number of bedrooms, and amenities.
- DataFrame Two records past sales transactions, including the sale price, date, address, and property type.
Concatenating these DataFrames and developing a rich data set can help you predict property values, identify market trends, and analyze buyer preferences.
Here’s an example showing before and after concatenating two DataFrames:
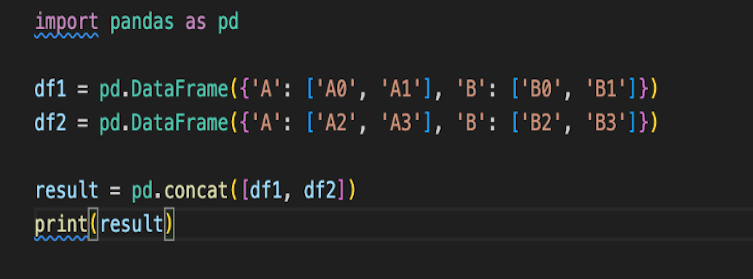
Result:
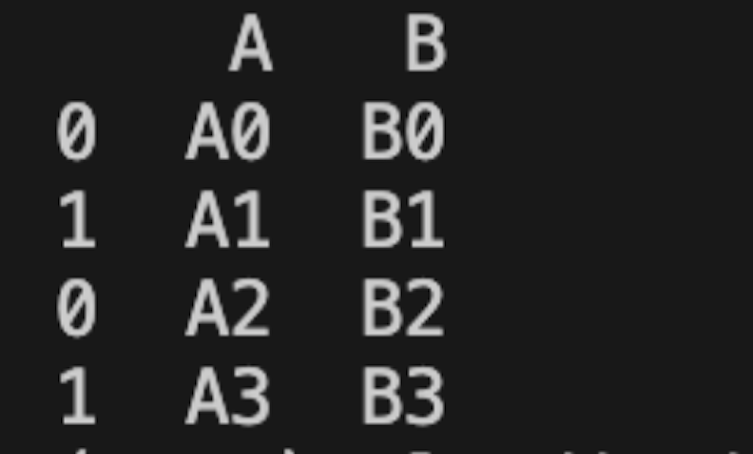
This example shows how concatenating seemingly separate data sets can unlock valuable insights and optimize your decision-making in a real-world business context.
2. pandas.concat() To Join Two DataFrames
The join parameter lets you configure the handling of overlapping columns during DataFrame concatenation.
For instance, one DataFrame could include customer information like names and emails, and another with their purchase history, including product IDs and prices. You can use concat() to combine them, creating a single DataFrame with all relevant customer data for personalized recommendations or marketing campaigns.
Here’s an example to illustrate the use of the join parameter:
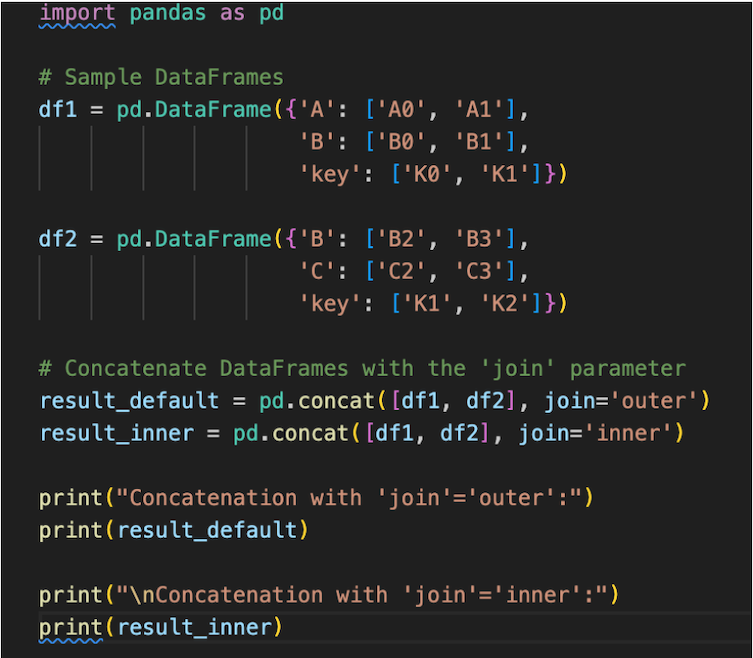
Result:
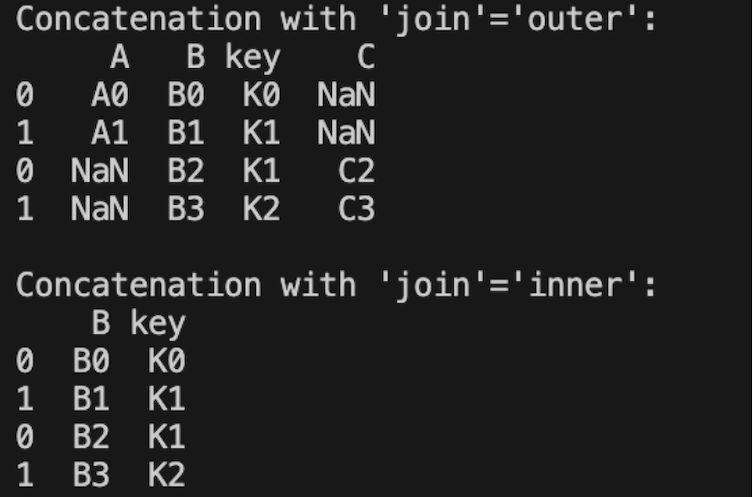
Join=outer takes the union of columns, and missing values are filled with NaN — not a number.
Join=inner takes the intersection of columns, keeping only the common columns.
So there you have it: Your ultimate guide to wielding the power of pandas.concat(). Build comprehensive data landscapes, unveil hidden patterns, and conquer data chaos confidently. The world of data analytics is your oyster.
Frequently Asked Questions
What does the concat() function return in Pandas?
The return value of pandas.concat() in Python depends on several factors, including the input data, the chosen arguments, and the specific context of your operation. Depending on the combined objects and the chosen axis, the function generates a new Series or DataFrame as the output.
When you concatenate all Series objects along the index (axis=0) using the pandas.concat() function, the returned object is a Series. This is because, when combining Series objects vertically (axis=0), they become stacked on top of each other, resulting in a single column with the combined data points.
When you use pandas.concat() and at least one of the objects in the "objs" parameter is a DataFrame, the returned value will always be a DataFrame, regardless of whether you concatenate along the index (axis=0) or columns (axis=1). If you concatenate a Series with a DataFrame, it is essentially absorbed into the DataFrame, becoming one of its columns.
When combining different types, the dominant data type takes precedence. So, since DataFrames are more complex and versatile, they take priority over Series in the returned object.
Some additional factors influence the return value:
- The
joinparameter specifies how to handle overlapping indexes when combining DataFrames. Different values, like 'inner' and 'outer', can lead to different index lengths in the resulting DataFrame.
- The
ignore_indexparameter: If set to True, the returned DataFrame will have a new, automatically generated index, regardless of the input DataFrames’ original indexes.
- The
keysparameter: Specifying this parameter will create a MultiIndex DataFrame with the provided keys as levels in the index.
What is the difference between appends and concat in Pandas?
pandas.append is a function that adds rows of one DataFrame or Series to the bottom of another. Think of it as extending a table by adding new rows sequentially. And it's a shorthand method for concatenating along axis zero.
It's a valuable tool for adding new data points or observations sequentially to an existing DataFrame/Series, appending results from multiple iterations or calculations, one after another. and extending a DataFrame with additional rows when the order of data matters.
Here is the syntax:
DataFrame.append(other,ignore_index=False, verify_integrity=False, sort=False)
Here are the properties:
other: The DataFrame or Series to be appended.ignore_index: If True, the resulting DataFrame will have a new range of indices, ignoring the existing indices in both DataFrames.verify_integrity: If True, it will raise a ValueError if the resulting DataFrame has duplicate indices.sort: This checks whether the columns of the DataFrame are correctly organized.
A significant benefit is that it’s easy to use for basic appending tasks, especially compared to pandas.concat(). Though functional, however, Pandas plans to remove the function in a future update, so it encourages using concat() for most data-combining tasks due to its greater flexibility and functionality.


