

A fact table contains foreign keys that reference the primary keys of related dimension tables, along with quantitative metrics. A dimension table provides descriptive attributes for those foreign keys, enriching the context of each recorded event.
As organizations generate and consume an increasing volume of data, effective data management is becoming more challenging, particularly when it comes to data storage and modeling. Therefore, establishing a proper data structure is critical for managing data effectively.
Fact Table vs. Dimension Table Defined
- A fact table stores quantitative measurements about business events, such as sales, transactions, or inventory levels. It includes foreign keys that reference dimension tables, which provide context.
- A dimension table contains descriptive, qualitative attributes (e.g., customer name, product type, or region) that enrich the facts and enable deeper analysis. Each dimension table has a primary key, which the fact table uses as a foreign key.
In this article, we’ll explore a widely used principle in data engineering known as star schema, and delve into its two primary components: fact and dimension tables.
We’ll discuss their differences in further detail and provide an end-to-end example to demonstrate how these concepts are utilized in real-world projects.
What Is a Fact Table?
A fact table in a data warehouse stores quantitative data related to business processes, such as orders, inventory levels or revenue. It includes numerical measures and foreign keys that reference dimension tables, which provide contextual details without duplicating descriptive data.
A fact table is the central table in star schema or snowflake schema, and tends to be the largest table of the schema. Both star and snowflake schemas typically have one fact table.
In a fact table, each row corresponds to one event or measurement, with some rows being associated with a dimension table in the schema. Every row referencing a dimension table has its own foreign key, which links the data in the fact table to the referenced dimension table. Foreign keys in a fact table reference the primary keys of related dimension tables, linking quantitative measures to descriptive context.
Characteristics of a Fact Table
- Contains quantitative data about the events or measurements of a business process.
- Holds foreign keys (the primary keys) of referenced dimension tables, plus its own primary key.
- Often one, central table of star schema or snowflake schema.
- Often the largest table in star schema or snowflake schema.
What Is a Dimension Table?
A dimension table is a table in a data warehouse schema that stores qualitative data or descriptive attributes for related data in the fact table, such as customer information, store location or product name. Data inside a dimension table represent the different aspects of a business process, and is linked alongside the events or measurements recorded in the fact table to help provide context.
There are typically multiple dimension tables that surround the central fact table in star schema or snowflake schema.
Each dimension table in a schema holds its own primary key, which is used to identify an associated record in the fact table. A dimension table’s primary key is known as a foreign key when inside the fact table.
Characteristics of a Dimension Table
- Contains qualitative, descriptive data about the numerical data in a fact table.
- Holds its own primary key.
- Often multiple tables that surround the fact table in star schema or snowflake schema.
- Often smaller in size than the fact table in star schema or snowflake schema.
Fact Table vs. Dimension Table in Star Schema
In a star schema, a single fact table is surrounded by multiple dimension tables. The fact table records business events and links to dimension tables using foreign keys. This design supports fast, readable queries by avoiding excessive joins, though it introduces some data redundancy due to the denormalized structure of the dimension tables.
Additionally, in a star schema model, fact tables have a defined level of granularity, which determines the level of detail recorded — for example, daily transactions versus monthly summaries. High granularity means more detailed data, and low granularity means less detailed data. Dimension tables typically support this granularity with consistent descriptive attributes.
How to Differentiate a Fact Table vs. Dimension Table
A straightforward approach to differentiating fact tables from dimension tables is to examine whether a table refers to a noun, such as a physical object or person. For instance, a product or a customer may exist independently of any specific business event. Dimension tables typically represent real-world entities — such as customers, products or stores — that provide context for business events recorded in the fact table.
On the other hand, a verb usually corresponds to a fact table. Each record corresponds to an event in which entries from dimension tables are involved. For example, an order involves a customer and a product (or potentially more). The act of placing an order is made by a specific customer for a specific product.
As an example, let’s consider a use-case where customers purchase products in physical stores. The star schema is illustrated below.
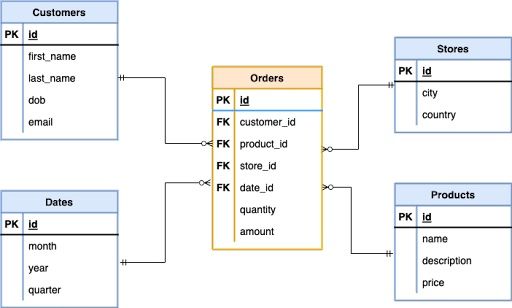
Dimension tables, which are in blue, correspond to the tables containing information about the “Customers,” “Stores,” “Products” and “Dates.” These are the nouns of the business case.
The fact table shown in orange contains all the primary keys (PK) of the dimension tables, which are the foreign keys (FK) in the fact table, along with two quantitative fields — namely quantity and amount.
Fact tables are typically assigned a surrogate primary key to ensure each row is uniquely identifiable. While it’s technically possible to omit a primary key, doing so is uncommon and may complicate data management and query performance.
Benefits of Fact Table and Dimension Table in Star Schema
Makes Schema Faster, Simpler and Easier to Design
Due to the denormalized nature of the model, star schema tends to be faster in terms of performance. At the same time, star schema tends to be fairly simple, and thus, the overall structure is easier to be designed. Additionally, it’s much more readable, even if it’s not as maintainable as snowflake schema.
Facilitates Data Aggregation
The structure of the star schema facilitates data aggregation, with a fact table typically joined to only one level of dimension tables.
Reduces Query Complexity and Simplifies Testing
This simplicity reduces the complexity of queries for data engineers and scientists and may also simplify the testing process.
Minimizes Risk of Affecting Other OLAP Technologies
Additionally, the efficient query performance of the star schema helps minimize the risk of adversely affecting other online analytical processing (OLAP) technologies.
Disadvantages of Fact Table and Dimension Table in Star Schema
Denormalization and Data Repetition
As previously mentioned, dimensions in the star schema are denormalized, potentially leading to repeating values within a table.
Large Schema Storage Size
Consequently, storage requirements for star schema are relatively larger than those of other schemas, such as the normalized snowflake schema. If storage size is a concern, this data redundancy may warrant reconsideration of the star schema.
Risks to Data Integrity
Furthermore, the data redundancy in the star schema heightens the risk to data integrity, as new updates, deletions, and insertions may affect the overall data integrity due to data being repeated in multiple records.
Although the star schema is simple to design and implement because of the straightforward relationships between tables, maintaining it may pose a challenge due to the aforementioned data integrity concerns. With new data ingested and the potential creation of new tables, validating and preserving data integrity throughout the data warehouse may become difficult.
Understanding Fact Table vs. Dimension Table
In this article, we highlighted the importance of having a proper structure for data storage to enable effective management of data. We discussed the star schema, a commonly used principle in data engineering, and its two main components: fact and dimension tables.
In addition, we’ve seen how to apply these concepts in real use-cases. We also examined the pros and cons of the star schema, including its potential storage and data integrity issues.
Ultimately, the decision to use star schema depends on the specific circumstances, and alternative approaches such as the snowflake schema should be considered as necessary. By understanding star schema, data engineers and scientists can build efficient data storage structures and perform effective data analysis.
Frequently Asked Questions
What is the difference between dimension and fact table?
In a data warehouse schema, a dimension table provides descriptive context (e.g., customer or product details), while a fact table records measurable business events using those descriptions as foreign keys.
Each dimension table has its own primary key, while a single, central fact table contains foreign keys referencing those dimension tables (along with its own primary key).
What is an example of a fact table?
Examples of a fact table include sales transactions, order histories or inventory changes — each record measures a business event.
What is an example of a dimension table?
Examples of a dimension table include customer profiles, product catalogs and time/date hierarchies — each record adds context to a fact.


