

In a database, normalization and denormalization impact how data is stored and accessed, so having a good grasp of these principles can protect your users from creating errors in your database.
Database Normalization vs. Denormalization: What’s the Difference?
- Database normalization is a method of organizing data inside of a relational database based on normal form. This principle is one of the foundations of relational databases, which connect information from different tables via a key, or a unique identifier.
- Database denormalization is the merging of database tables to reduce query complexity and improve read performance. It introduces some redundancy to avoid joins, trading storage efficiency and data integrity for faster access.
In this article, we’ll delve into each topic so you can manage your databases as efficiently as possible.
What Is Normalization in a Database?
Database normalization is a method of organizing data inside of a relational database based on normal form. Computer scientist Edgar F. Codd proposed normal form as a way to reduce anomalies that can happen when injecting data into a database. This principle is one of the foundations of relational databases, which connect information from different tables via a key, or a unique identifier.
By using normal form as a method of organization, you can reduce the possibility of creating anomalies in the database. The three anomalies — insertion, update, and deletion — can ruin the integrity of a database.
Types of Database Anomalies
- Insertion anomaly occurs when data is inserted into a table data that doesn’t correspond to the structure of the table. For example, say you can’t add a new student to a database because there’s no associated class record yet — even though the student exists, the database structure prevents the entry.
- Update anomaly occurs when data isn’t updated in all areas. For example, when you update something, say an address, in one place but not others.
- Deletion anomaly occurs when data is deleted in a way that means more data has to get deleted. For example, you might want to delete one item but then have to delete everything since it’s all in one row.
How Normalization Works
You normalize by splitting data into separate tables to ensure each piece of information is stored only once and referenced via keys.
Here is an example. This is a denormalized set of data:
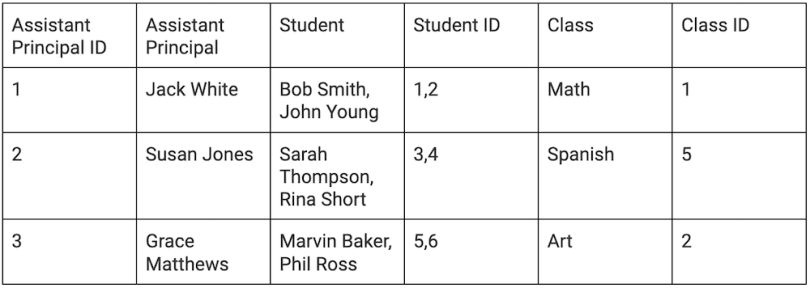
This is this same data broken down into atomic elements:
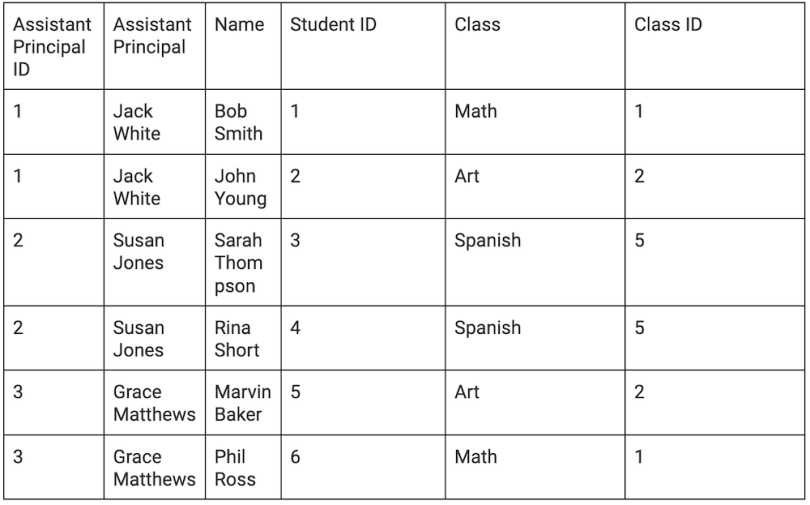
As you can see, the data is organized to create one row per class. We’re on the path to normalization because the table’s atomic elements represent first normal form (1NF). 1NF notes that each box in the table only represents one piece of information.
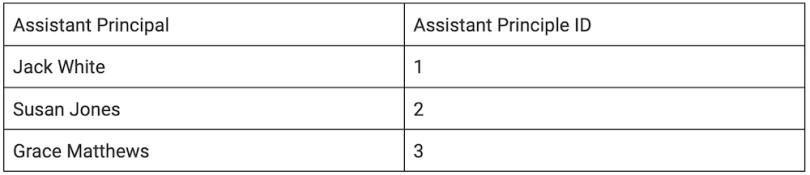
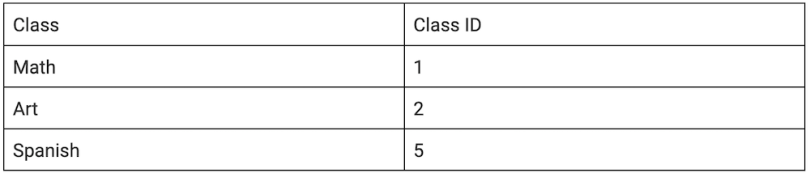
Next, we’ll move this into the second normal form (2NF). 2NF involves separating the information into a table with a unique key. For this purpose, we will use the assistant principals since they represent multiple students.
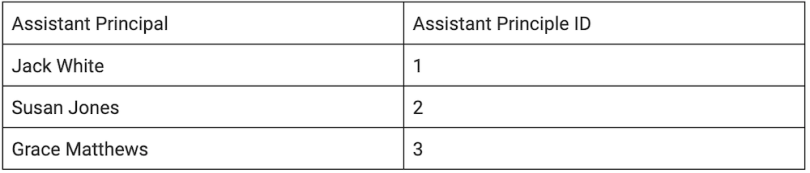
We then pull that information out of this table since it will be referenced.
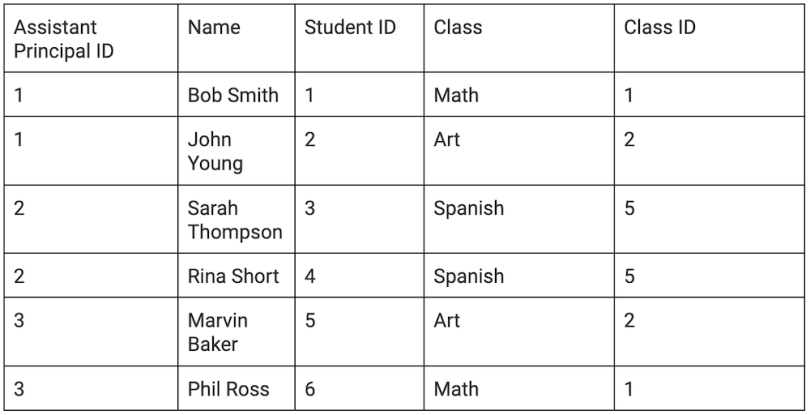
The next step is to fully normalize the table in third normal form (3NF). 3NF decomposes any transitive functional dependencies, that is, removing anything that can be referenced into its own table. This creates tables like so.
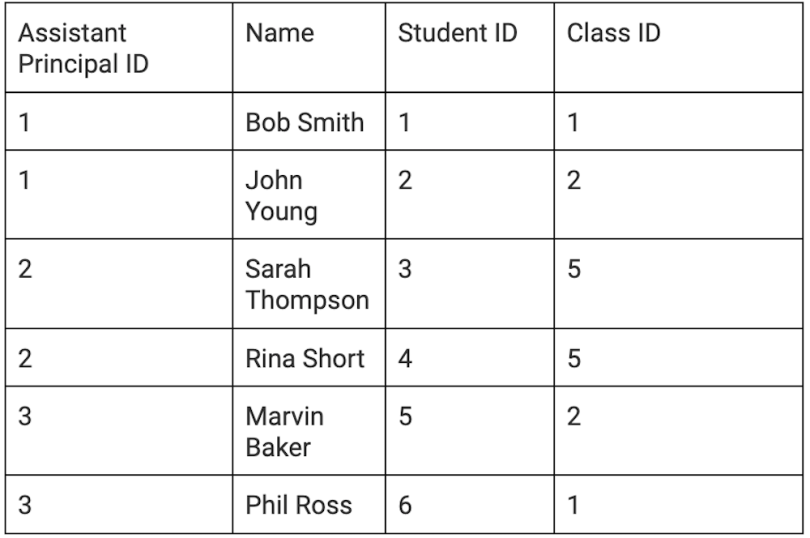
Pros and Cons of Normalization
Pros of Normalization
Database normalization helps reduce data redundancy by putting data in unique tables to be referenced. Reducing the redundancy also creates a more compact data set. Compactness helps clarity for reading purposes and makes them easier to edit because it’s easier to see the classes above in a separate table instead of one large one.
A normalized table also minimizes the chance of getting a null value or null entry, since normalized structure makes it easier to isolate and identify data issues during query debugging. For example, the size of the class is much easier to query with separate tables instead of one mass of data.
A normalized table makes it easier to add data to your tables since you’re only adding one form of it. For example, if you want to add a class, you can just add a class. You don’t have to worry about the other data, avoiding the chance for an insertion error. Further, since the data is separated, you can extend without impacting it.
Cons of Normalization
These benefits come at the cost of speed since multiple tables have to be read instead of one. This issue isn’t a big deal with small databases. In larger ones, however, especially those whose queries are tied to service level agreements (SLAs), this can create serious problems.
What Is Denormalization in a Database?
Database denormalization is the condition where all the data lives in one table instead of separate ones. Essentially, you take the tables we created above and join them back into the original state like so:
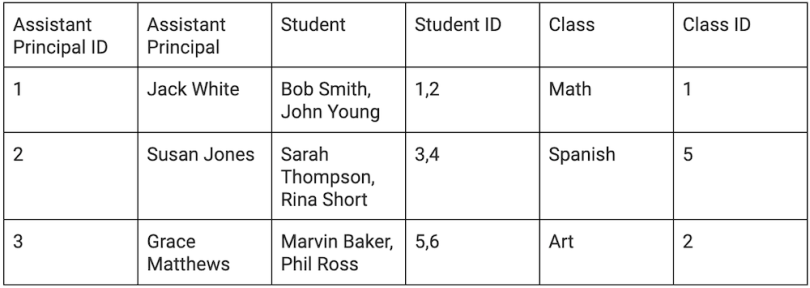
Consider this similar to code minimization, where the code is harder to read or edit but runs faster since everything is crunched together.
Pros and Cons of Denormalization
Pros of Denormalization
Denormalization also has benefits. First, accessing the data is much quicker since a query doesn’t need to search in multiple tables and join information. Generating reports is also much faster.
The table can also be easier to manage if you aren’t adding data since all the information is functionally in one place.
Cons of Denormalization
On the other hand, denormalized data can be more prone to update and consistency errors, since redundant information stored in multiple places must be kept in sync. Centralizing data in one table may simplify access but increases the risk of anomalies.
Normalization vs. Denormalization in Databases
Normalized databases are focused on reducing redundant information. They make better use of space since the data is organized. They also offer high integrity by minimizing the chance of the anomalies thanks to separating the tables. Finally, normalization is useful for databases where change happens often, such as social media profiles.
Denormalized databases primarily offer data retrieval speed and faster query execution. They’re also cheaper to maintain because fewer database joins can mean less server load (but this can increase storage costs). Denormalization is useful for information that is often queried but rarely updated, such as tax information.
Frequently Asked Questions
What is database denormalization?
Denormalization in a database is the process of combining tables to improve read performance. It adds redundancy to reduce the need for joins, trading data integrity for faster access in read-heavy scenarios.
What is database normalization?
Database normalization is a method of organizing data into separate tables based on normal forms to reduce redundancy and avoid data anomalies like insertion, update, and deletion errors.


