

The glob module is a useful part of the Python standard library. Short for global, glob is used to return all file paths names that match a specific pattern.
What Is the Glob Module in Python?
The glob module in Python is used to search for file path names that match a specific pattern. It includes the glob.glob() and glob.iglob() functions, and can be helpful when searching CSV files and for text in files.
We can use glob to search for a specific file pattern, or perhaps more usefully, use wildcard characters to search for files where the file name matches a certain pattern:
- Asterisk (*): Matches zero or more characters.
- Question mark (?): Matches exactly one character.
Glob patterns can be thought of as similar to regular expressions but much simpler.
While glob can be used to search for a file with a specific file name, I find it especially handy for reading through several files with similar names. After identifying these files, they can then be concatenated into one dataframe for further analysis.
Using Glob to Search CSV Files
Here we have an input folder with several CSV files containing stock data. Let’s use glob to identify the files:
import pandas as pd
import glob
# set search path and glob for files
# here we want to look for csv files in the input directory
path = 'input'
files = glob.glob(path + '/*.csv')
# create empty list to store dataframes
li = []
# loop through list of files and read each one into a dataframe and append to list
for f in files:
# read in csv
temp_df = pd.read_csv(f)
# append df to list
li.append(temp_df)
print(f'Successfully created dataframe for {f} with shape {temp_df.shape}')
# concatenate our list of dataframes into one!
df = pd.concat(li, axis=0)
print(df.shape)
df.head()
>> Successfully created dataframe for input/KRO.csv with shape (1258, 6)
>> Successfully created dataframe for input/MSFT.csv with shape (1258, 6)
>> Successfully created dataframe for input/TSLA.csv with shape (1258, 6)
>> Successfully created dataframe for input/GHC.csv with shape (1258, 6)
>> Successfully created dataframe for input/AAPL.csv with shape (1258, 6)
>> (6290, 6)We searched through all the CSV files in our input folder and concatenated them into a pandas DataFrame.
We can see a small problem with this in the sample output below: We don’t know which file the row belongs to. The stock ticker was only the name of each file and wasn’t included in our concatenated dataframe.
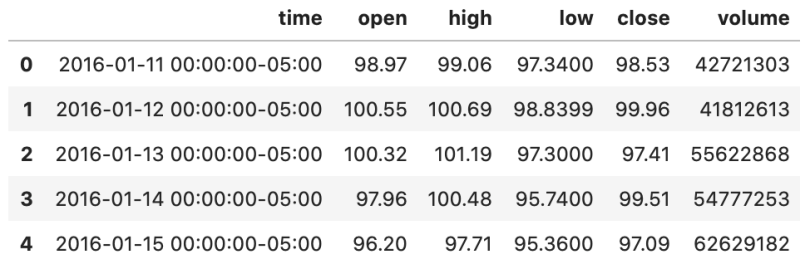
We can add a column with the ticker symbol to solve the problem of the missing stock ticker.
We create a new column with the file name, then use replace to clean the data, removing the unwanted file extension:
import pandas as pd
import glob
import os
# set search path and glob for files
# here we want to look for csv files in the input directory
path = 'input'
files = glob.glob(path + '/*.csv')
# create empty list to store dataframes
li = []
# loop through list of files and read each one into a dataframe and append to list
for f in files:
# get filename
stock = os.path.basename(f)
# read in csv
temp_df = pd.read_csv(f)
# create new column with filename
temp_df['ticker'] = stock
# data cleaning to remove the .csv
temp_df['ticker'] = temp_df['ticker'].replace('.csv', '', regex=True)
# append df to list
li.append(temp_df)
print(f'Successfully created dataframe for {stock} with shape {temp_df.shape}')
# concatenate our list of dataframes into one!
df = pd.concat(li, axis=0)
print(df.shape)
df.head()
>> Successfully created dataframe for KRO.csv with shape (1258, 7)
>> Successfully created dataframe for MSFT.csv with shape (1258, 7)
>> Successfully created dataframe for TSLA.csv with shape (1258, 7)
>> Successfully created dataframe for GHC.csv with shape (1258, 7)
>> Successfully created dataframe for AAPL.csv with shape (1258, 7)
>> (6290, 7)This looks much better. We can now tell which ticker each row belongs to.
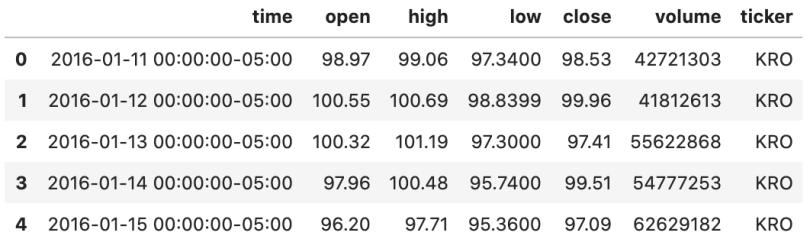
Now we have a useful dataframe with all our stock data. This can then be used for further analysis.
Using Glob to Find Text Files
The glob module is also very useful for finding text in files. I use glob extensively to identify files with a matching string.
Many times, I know I’ve already written code that I need, but can’t remember where to find it, or I need to find every program that contains a certain e-mail address or hard-coded value that needs to be removed or updated.
First, we can use glob to find all files in a directory and its subdirectories that match a search pattern. Then, we read the file as a string and search for the matching search pattern.
For example, I know I’ve made a KDE plot before, but I can’t remember where to find it.
Let’s find all .ipynb files and search for the string “kdeplot”:
import pandas as pd
import glob
# set filepath to search
path = '/Users/tara/ml_guides/' + '**/*.ipynb'
# string to search for
search_term = 'kdeplot'
# empty list to hold files that contain matching string
files_to_check = []
# looping through all the filenames returned
# set recursive = True to look in sub-directories too
for filename in glob.iglob(path, recursive=True):
# adding error handling just in case!
try:
with open(filename) as f:
# read the file as a string
contents = f.read()
# if the search term is found append to the list of files
if(search_term in contents):
files_to_check.append(filename)
except:
pass
files_to_check
>> ['/Users/tara/ml_guides/superhero-exploratory-analysis.ipynb',
'/Users/tara/ml_guides/glob/glob_tutorial.ipynb']We found two files that contain the string “kdeplot.” The file, superhero_exploratory_analysis.ipynb should be what we’re looking for.
The other file glob_tutorial.ipynb is the name of the file where this example lives, so it’s definitely not the example we’re looking for.
Differences Between Glob and Iglob
Two items in this example differ from the above. We specified recursive=True and used iglob instead of glob.
Adding the argument recursive=True tells glob to search all sub-directories as well as the ml_guides directory. This can be very helpful if we aren’t sure exactly which folder our search term will be in.
When the recursive argument is not specified, or is set to False, we only search in the folder specified in our search path.
Searching a large number of directories could take a long time and use a lot of memory. A solution to this is to use iglob.
iglob differs from glob in that it returns an iterator “which yields the same values as glob without storing them all simultaneously,” according to the documentation. This should provide improved performance versus glob.
We’ve now reviewed Python’s glob module and two use cases for this powerful asset to Python’s standard library.
We demonstrated the use of glob to find all files path names in a directory that match a given pattern. The files were then concatenated into a single DataFrame to be used for further analysis.
We also discussed the use of iglob to recursively search many directories for files containing a given string.
This guide is only a brief look at some possible uses of the glob module.
Frequently Asked Questions
What is the glob module in Python?
The glob module in Python is used to search for file path names that match a specific pattern, using wildcard characters like * and ?. It helps in locating and handling multiple files based on their paths efficiently.
What is the difference between glob.glob() and glob.iglob()?
In the Python glob module, glob.glob() returns a list of matching file path names, while glob.iglob() returns an iterator with the same values as glob.glob(), which can make it more memory-efficient for large searches.
Can glob be used to search for text inside files?
No, the Python glob module itself cannot search for text inside files and can only finds file path names that match a pattern. To search for text within files with glob, you need to also open and read them manually using Python’s file-handling features.


