

Long ago, whether you were grabbing candy at a five and dime or shopping at a clothing retailer, the store owners were keeping track of what you were purchasing. In fact, they were tracking what everyone was purchasing and making informed decisions on what to restock based on which items were selling out faster than others. This data maintenance was done in a logbook with a pen and some mental math and then stored in a filing cabinet.
Today, with online shopping, social media networks and even digital payment options in-store, the insights into customer habits have grown far beyond what was once manageable for in-store shopping. With an estimated 224 million online shoppers in the US alone, storing and making sense of all that data is no small task. Not only does a company need to store the data, but it also needs to extract relevant information from it. Fortunately, we have techniques like data warehousing to help tackle the challenge.
In this article, I’ll give you an overview of what data warehousing is, how it works, and key techniques behind it. This is all information I draw on from my 30-plus years of experience in data warehousing and my course, Data Warehouse Fundamentals for Beginners, where I cover the best practices for the architecture, dimensional design and data interchange needed to implement data warehousing in your organization.
Let’s get started with the basics of data warehousing.
What Is Data Warehousing?
Data warehousing is the aggregation of data into one storage place — at least, logically, and often, physically. We can derive numerous valuable insights about our businesses when we integrate data from multiple source applications and operational systems, mostly from within our enterprises but also from external data providers.
Information from relational databases that contain the records of a company’s daily transactions is the type of data typically stored in a warehouse. The data within this central repository is then reorganized to support reporting, business intelligence (BI) and analytics — all tools necessary for data-driven decision-making to keep your company competitive.
Data warehousing was born in the very late 1980s and early 1990s based on several different analytical data management theories that came together. IBM researchers Barry Devlin and Paul Murphy are thought to be the first people to create a “business data warehouse” in the late 1980s. Then, as early efforts in distributed database management systems fizzled, Bill Inmon defined the rules for data warehousing that took hold throughout the 1990s into the 2000s. At the same time, Ralph Kimball also made major contributions to the discipline, particularly in data warehouse design via dimensional modeling. The concept of the data warehouse has since developed into what we see today — a complex system that has grown with the evolution of the computer.
Data Warehousing vs. Databases
Let’s clear up a common point of confusion — a data warehouse is not the same as a database. To put it simply, a database records data, while a data warehouse is best thought of as an environment that analyzes the historical data and the commutative data it has collected.
A data warehouse is usually built on top of a database. The database is the platform, while the data warehouse is the usage. The more data sources present, the more complex your data warehouse will become.
Some of the most popular data warehouse vendors today include Amazon Redshift, Google BigQuery, Snowflake, Oracle and IBM Db2 Warehouse among others.
What Are the Benefits of Data Warehousing?
Data warehousing offers insights into what a company’s data might mean and enables data-driven decision-making. For a broad example, executives and managers look at information from their data warehouse to understand how their business is doing and what, if any, trends are emerging. They then interpret the data in a way that will lead to strategic changes. Those changes can provide a competitive advantage and increase a business’s longevity.
In a more narrow sense, these data-driven insights and the resultant decision-making span the breadth of our enterprises, from sales to marketing to finance, and from manufacturing to supply chains to human resources and personnel. Further, these data-driven insights can coalesce in a geographical manner — findings for all of a company’s North American operations, for example, or all its operations in Europe. Those insights can be produced at an enterprise level or down to an organizational level. Essentially, data warehousing is responsible for gathering and organizing the data, while its sibling discipline of business intelligence is responsible for the delivery of the insights.
Data warehousing uses BI tools to make sense of analytics and to strategize effective ways to improve a business’s future based on its past and current state.
Data Lake vs. Data Warehouse
A term heard often with data warehousing is “data lake.” These are two different types of data storage uses, but the lines between each are becoming increasingly blurred.
Data warehousing is largely built on top of relational database management systems (DBMSs) such as Microsoft SQL Server, Oracle or IBM Db2. Data warehousing typically includes only structured data such as numbers, character strings, dates, etc.
A data lake brings any type of data — whether structured, unstructured or semi-structured — together from many different sources and applications to support analytics. Essentially, the data lake helps break through application and platform barriers and provides one-stop shopping for data. Data lakes are used to manage extremely large volumes of data, rapid intake and updates of data, and — as noted above — “data variety” by handling structured, semi-structured and unstructured data. They’re built on top of big data environments such as Hadoop or Amazon Web Services (AWS) data platforms such as S3, Redshift, Aurora and other AWS data platforms.
In some ways, a data lake could be thought of as a successor to a data warehouse. Most organizations still have the foundation of their data analysis coming from a data warehouse, but they use it alongside artificial intelligence, machine learning and other advanced analytics driven by a data lake.
Ideally, organizations should have a well-architected integration between their data warehousing and data lake environments to avoid unnecessary fragmentation between the two.
What Are Some Data Warehousing Techniques?
Data warehousing can be thought of as a collection of sub-disciplines, each of which is a set of specialized techniques, including:
ETL – Extract, Transform, Load
When data moves from its source into the warehouse, a group of processes occurs called extract, transform and load (ETL). These three processes work together to format and normalize incoming data so that it can be properly loaded into the warehouse.
The extraction process imports data from its original source and feeds that data into the data warehousing environment as quickly as possible. Minimal changes are made to the incoming data; the idea is to be able to ingest potentially large amounts of data in a finite time window.
Next up is the transformation phase. This is the stage that reorganizes and transforms data into a unified schema by making values and structure consistent. Data quality assurance and validation occur as part of transformation by fixing known errors or otherwise trying to prevent erroneous data from making its way into what users can access.
Once the data is formatted uniformly, the load phase can begin. This consists of taking the data that was temporarily held in the extraction phase and placing it permanently into the target database.
The load phase is the final phase, although the whole ETL process is repeated — and is repeated often — to keep the data warehouse up-to-date. One important aspect of data retrieval for data warehouses is dimensional modeling, which makes it easier and faster to retrieve data.
Dimensional modeling
The technique of dimensional modeling closely aligns with data warehousing’s sibling discipline of BI and helps us structure data as facts (or measurements) and dimensions (how we slice, dice and filter those facts).
Dimensional modeling of data is, in itself, a complex sub-discipline of data warehousing. In order to return accurate insights, a data warehouse must be kept up-to-date through the regular addition of new and updated content from source systems. Some of the additional or modified content is in the form of new facts such as new sales, or returns and refunds. Or in other domains, facts might be end-of-semester grades at a university. Other additional or modified content is for the dimensions — a brand-new product, a newly hired faculty member or the demographic information about a customer who placed their first order.
Even within dimensional modeling, we can structure our database tables into different schemas depending on the architectural approaches of your data team. Either way, database rules govern how we build database tables within a data warehouse and how we relate those tables to one another.
Star and snowflake schemas
Schemas are a part of the data warehouse architecture and they play a role in the organization and analysis of the data. Data warehouses frequently use two types of schemas, star schemas and snowflake schemas.
The star schema has a center table called the fact table, and from that table of data, other dimension tables stem that have associated data. The dimension tables are not joined to each other — only to the fact table — thus giving it a star shape. It’s the most simple form of schema in a data warehouse and it is used to query large data sets.

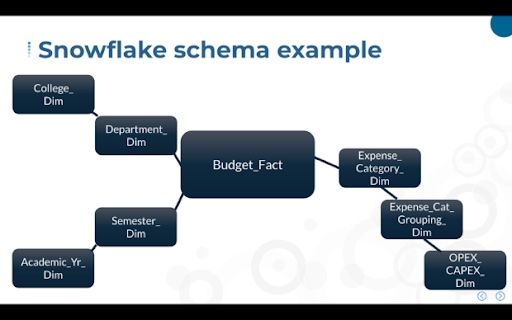
The snowflake schema, as its name suggests, is shaped in a snowflake pattern. Like the star schema, a snowflake schema still has a main fact table, but it has dimension tables that stem from other dimension tables.
Business intelligence tools typically provide guidance to data warehouse designers whether star or snowflake schema models should be used. Some BI tools work better with star schemas, while others are optimized for snowflake schemas. Regardless of which model is implemented, both star and snowflake schemas are designed to support dimensional analysis of our data.
Why Use Data Warehouses?
Data engineers and people in similar positions who deal with massive amounts of data often find data warehouses a useful tool. Organizations that want a more simplified approach to accessing large amounts of data might also prefer to work with data warehouses rather than data lakes.
There are many ways professionals may work with data warehouses. Some data warehousing specialists concentrate solely on the data warehouse itself, such as the dimensional modeling or ETL development of the warehouse. Others work solely with classic, relational-based data warehouses, while others work with the decision-science side of how the data warehouse is used, such as in fields like business intelligence, data visualization and other analytics forms.
The ability to inform data-driven business decisions requires a team to have demonstrable skills in data warehousing. Professionals with these skills see consistently high demand for their knowledge as organizations understand the importance of data skills both for new development as well as the ongoing maintenance and enhancement of existing data warehouses.
How Data Warehousing Enables Better Decision-Making
What is data warehousing going to do for your company? It’ll make your business more efficient and competitive by streamlining once time-consuming processes, bringing data-backed awareness to business performance and empowering employees to better articulate insights using data.
With company data consolidated, it becomes more accessible, consistent and high quality, all of which are imperative to operating a business that thrives on strong decision-making. The less time you spend having to repeatedly gather, consolidate, clean and organize data from different sources, the more time you can spend troubleshooting ways to move your company forward and improving what you do.
Master the techniques needed to plan, build, and design data warehouses, and you’ll transform how your organization organizes data. It’ll serve as an important step in building reliable data insights.
***
This article was originally posted on Udemy’s blog as What is Data Warehousing? Understand the Importance of Data Structures and Architecture.


