

Python is an easy language to pick up, but mastering it requires understanding a lot of concepts.
In my last post, I talked about using a multiprocessing module to do parallel processing. Python also offers users the power to work with concurrency using the Asyncio module from version 3.4 forward.
For people who come from a JavaScript background, this concept might not be new, but for people coming from Python 2.7, (yes, that’s me) Asyncio may prove to be hard to understand, as does the difference between concurrency and parallelism. Due to its growing popularity, though, it has really become an important concept to master.
In this post, I want to mitigate some of the confusion around Asyncio, explaining it in the simplest terms possible.
What Is Python Asyncio?
Concurrency vs. Parallelism
People are often confused about the difference between concurrency and parallelism. The way I understand them is that concurrency can happen with a single process, whereas parallelism demands multiple processes. Suppose you had some number n of tasks to perform. If you perform them simultaneously using multiple cores in your machine, you’re using parallelism. When using concurrency, however, you run the tasks in overlapping time periods, pausing one task when needed and running another when the first one is paused. So, concurrency is sort of multitasking on a single-core machine.
Another way to distinguish these processes is that parallelism is suited for CPU-bound tasks while concurrency is suited for tasks that are dominated by a lot of waiting on input or output to complete. So, if you were to train multiple models, you would use parallelism, as it is a CPU-bound task, and there are no times where the CPU has to wait for inputs. In the example I look at below, however, we have to wait for inputs from the server, and so concurrency will suit us a lot better.
What Is Python Asyncio?
According to Python Docs, “Asyncio is a library to write concurrent code using the async/await syntax.”
To understand Asyncio, we first need to understand blocking calls. So, what is a blocking call? In simple terms, it’s a process that takes time to finish but no CPU processing power. For instance, time.sleep(10) is a good example. The call tells the machine to sleep for 10 seconds and not do anything else. Another example of a blocking call is when you wait for a response from a server and your CPU is just sitting idle.
For a more real-world example, let’s assume you have to complete some tasks — wash clothes, cook food and bake a cake. Let's say for convenience that each of these tasks take 60 minutes. If you were to do these tasks sequentially, you would take three hours to finish everything.

Normally, though, when we have to do such tasks, we switch between them. For example, you can work on cooking food while the washing machine is running. You’re also free when the pan is on the stove or the cake is in the oven. So, your workflow might actually look something like this:
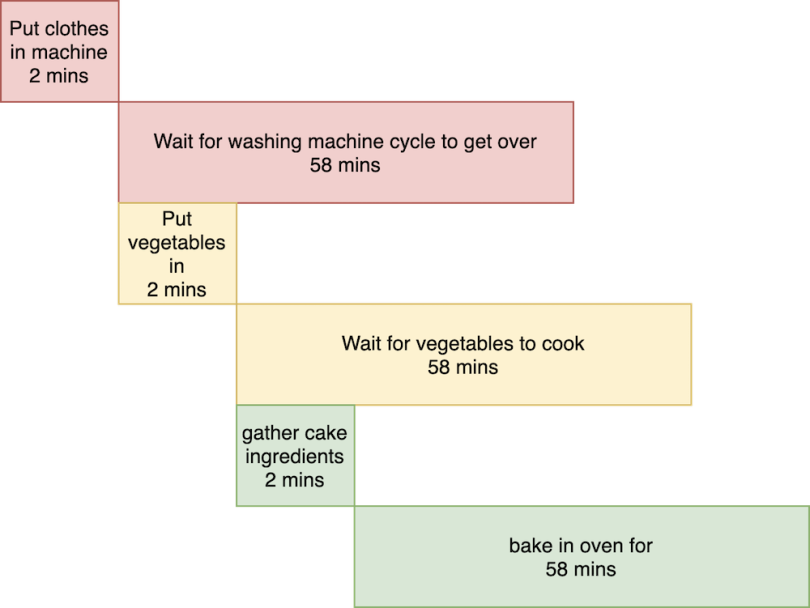
Here, all the waiting parts of the tasks are the blocking calls. And you would take around one hour in total to finish all three of your tasks.
Asyncio is just a framework that allows you to do exactly this with your machine. You can ask a single process to switch and begin working on another task whenever it encounters a blocking call.
Python Asyncio in Action
Let’s start with a simple example to get an understanding of how Asyncio works. Let’s say we want to execute this code, which just returns something after sleeping for a little while. This example is remarkably similar to the sort of tasks we saw above where we had a blocking call. Here, the blocking call is time.sleep. If we were to do this sequentially, we would get the following result:
import time
def return_something():
time.sleep(1)
return "hello!"
def main():
result = []
for i in range(3):
result.append(return_something())
return result
if __name__ == "__main__":
import time
s = time.perf_counter()
result = main()
elapsed = time.perf_counter() - s
print(result)
print(f"Executed in {elapsed:0.2f} seconds.")
--------------------------------------------------------------------
['hello!', 'hello!', 'hello!']
Executed in 3.01 seconds.In a sequential setting, the code takes around three seconds to run. How can we rewrite this code using Asyncio?
import asyncio
import time
async def return_something():
await asyncio.sleep(1)
return "hello!"
async def run_multiple_times():
tasks = []
for i in range(3):
tasks.append(return_something())
result = await asyncio.gather(*tasks)
return result
if __name__ == "__main__":
s = time.perf_counter()
result = await run_multiple_times()
elapsed = time.perf_counter() - s
print(result)
print(f"Executed in {elapsed:0.2f} seconds.")
--------------------------------------------------------------------
['hello!', 'hello!', 'hello!']
Executed in 1.01 seconds.So, what’s happening here? What are these await and async keywords?
In very simple terms, the async and await keywords are how Python tells the single-process thread to switch between tasks whenever it encounters a blocking call.
In this code, we start by defining asynchronous functions, typically called coroutines, using the async keyword. In this boilerplate code, we have done two things:
-
Defined a simple asynchronous function return_something that contains a blocking call. We ask Python to switch to another task by adding await in front of the blocking call asyncio.sleep(1)
-
Run that asynchronous function multiple times using asyncio.gather(*tasks) in the run_multiple_times function, which is also asynchronous.
One thing you might note is that we use asyncio.sleep(1) rather than time.sleep(1). This is because time.sleep is a normal Python function, and we can only await coroutines and Asyncio functions defined using the async keyword in front.
Also, note that the await keyword is required to call any async function. You can see this in the result await run_multiple_times() and await asyncio.gather(*tasks). For this reason, tasks.append(return_something()) doesn’t result in running return_something() and instead just adds the task to the tasks list.
This might all seem a little complex. In practice, though, whenever you have to use Asyncio, you can just use the code above as is while also doing these three things:
-
Write an asynchronous function with some blocking call that does something. For example, getting an HTML response for a URL or, in the above case, our return_something function.
-
Write an asynchronous function that can run the above function multiple times after adding that to tasks and using asyncio.gather.
-
Run the second function using await.
A Real-World Python Asyncio Example
So, now that we understand a little about Asyncio, let’s try to use it for a simple scraping example. Suppose we have to get data for a lot of movies from IMDB. Let’s first try to get the HTML for a single IMDB movie page.
import requests
from bs4 import BeautifulSoup
def get_html_by_movie_id(movie_id):
url = f"https://www.imdb.com/title/{movie_id}/fullcredits"
response = requests.get(url)
return response.textHere, we created a function that can get us the HTML text for an IMDB movie page by just supplying some movie ID. For example:
get_html_by_movie_id('tt2560140')
------------------------------------------------------------------
Output: Some HTML Here...Given a movie list like below, how can we get HTMLs for all these movie IDs? I will try to do this in three different ways — sequentially, using multiprocessing and using Asyncio.
movies_list = ['tt2935510','tt7131622','tt5463162','tt4758646','tt3640424','tt6024606','tt1596363','tt3707106','tt2713180','tt2193215','tt2024544','tt0816711','tt1764234','tt1402488','tt1210166','tt0478304','tt1001526','tt0361748','tt0421715','tt0887883','tt0443680','tt0496806','tt0449467','tt0356910','tt0349903','tt0332452','tt0165982','tt0270288','tt0240772','tt0266987','tt0236493','tt0208092','tt0137523','tt0120601','tt0119643','tt0120102','tt0118972','tt0117665','tt0114746','tt0114369','tt0110322','tt0110148','tt0109783','tt0108399','tt0107302','tt0105265','tt0104009','tt0104567','tt0103074','tt0101268','tt0097478','tt0097136','tt0118930','tt0093407','tt0093638','tt0093640','tt0093231']
Sequential
We can run this code to check how much time would it take to scrape all these movies:
s = time.perf_counter()
result = []
for movie in movies_list:
result.append(get_html_by_movie_id(movie))
elapsed = time.perf_counter() - s
print(f"Executed in {elapsed:0.2f} seconds.")
--------------------------------------------------------------------
Executed in 44.47 seconds.
Multiprocessing (Parallelism)
Yes, we can use multiprocessing to do this, and it works well. For more information on how multiprocessing works, look at this post.
from joblib import Parallel, delayed
s = time.perf_counter()
result = Parallel(n_jobs=8)(delayed(get_html_by_movie_id)(movie_id) for movie_id in movies_list)
elapsed = time.perf_counter() - s
print(f"Executed in {elapsed:0.2f} seconds.")
--------------------------------------------------------------------
Executed in 9.72 seconds.
Asyncio (Concurrency)
And here is the Asyncio version:
import aiohttp
from aiohttp import ClientSession
async def get_html_by_movie_id_new(movie_id, session):
url = f"https://www.imdb.com/title/{movie_id}/fullcredits"
response = await session.request(method="GET", url=url)
html = await response.text()
return html
async def scrape_all_titles(movies_list):
async with ClientSession() as session:
tasks = []
for movie_id in movies_list:
tasks.append(get_html_by_movie_id_new(movie_id,session))
result = await asyncio.gather(*tasks)
return result
if __name__ == "__main__":
s = time.perf_counter()
result = await scrape_all_titles(movies_list)
elapsed = time.perf_counter() - s
print(f"Executed in {elapsed:0.2f} seconds.")
--------------------------------------------------------------------
Executed in 4.42 seconds.The Asyncio version worked the fastest of all three for this process, though we needed to write a bit of code for it to do so.
So, what is happening in this code? Three things.
-
We start by defining the async function get_html_by_movie_id_new to get HTML for a single movie. See how we used await session.request to await the response from the URL? This is similar to the asyncio.sleep call in the previous code. And there are a lot of libraries that have started using this syntax in Python. The ones I like the best are aiohttp (async requests module), aiofiles (async write to files), puppeteer (async selenium) and FastAPI (async APIs).
-
We created the asynchronous function scrape_all_titles that calls the above function multiple times after adding that to tasks and then using asyncio.gather.
-
We run the second function using await.
Below is a simple function that lets us see the difference in Asyncio’s performance versus Joblib.
import pandas as pd
import plotly.express as px
new_movies_list = movies_list*8
times_taken = []
for i in range(50, len(new_movies_list),50):
# for i in range(50, 101,50):
print(i)
movies_to_process = new_movies_list[:i]
# Multiprocess:
s = time.perf_counter()
result_multiprocess = Parallel(n_jobs=8)(delayed(get_html_by_movie_id)(movie_id) for movie_id in movies_to_process)
time_joblib = time.perf_counter() - s
# Asyncio
s = time.perf_counter()
result_asyncio = await scrape_all_titles(movies_to_process)
time_asyncio = time.perf_counter() - s
times_taken.append([i,"Joblib", time_joblib])
times_taken.append([i,"Asyncio", time_asyncio])
timedf = pd.DataFrame(times_taken,columns = ['num_movies', 'process', 'time_taken'])
fig = px.line(timedf,x = 'num_movies',y='time_taken',color='process')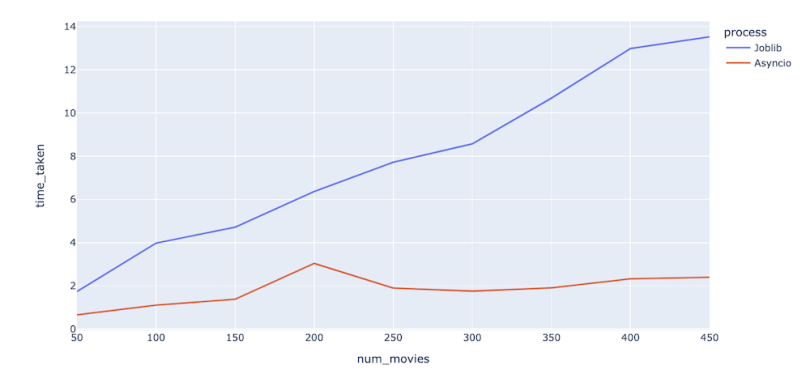
It just took two seconds for Asyncio to scrape data for 450 movie IDs! We can see, then, that Asyncio is good for this task, and it beats multiprocessing dramatically as the number of movies to be scraped increases. And the best thing is that it just uses a single core, whereas multiprocessing uses eight cores.
Add Concurrency to Your Toolkit
When we use Asyncio, we use a single process thread that ran all our tasks concurrently. Conversely, when we use Joblib, we ran eight multiple processes that ran our tasks in parallel.
Asyncio is a neat concept and something that every data scientist should at least know about when looking to make their code run faster. Getting a good working knowledge of the process will also as well help you to understand various upcoming libraries like FastAPI, aiohttp, aiofiles, puppeteer, among others.


