

Large language models (LLMs) have provided new capabilities for modern applications, specifically, the ability to generate text in response to a prompt or user query. Common examples of LLMs include: GPT3.5, GPT-4, Bard and Llama, among others. To improve the capabilities of LLMs to respond to user queries using contextually relevant and accurate information, AI engineers and developers have developed two main approaches.
The first is to fine-tune the baseline LLM with propriety and context-relevant data. The second, and most cost-effective, approach is to connect the LLM to a data store with a retrieval model that extracts semantically relevant information from the database to add context to the LLM user input. This approach is referred to as retrieval augmented generation (RAG).
Retrieval Augmented Generation (RAG) Explained
Retrieval augmented generation (RAG) systems connects an LLM to a data store with a retrieval model that returns semantically relevant results. It improves responses adding relevant information from information sources to user queries. RAG systems are a cost-effective approach to developing LLM applications that provide up-to-date and relevant information compared to fine-tuning.
RAG systems are an improvement on fine-tuning models for the following reasons:
- Fine-tuning requires a substantial amount of proprietary, domain-specific data, which can be resource-intensive to collect and prepare.
- Fine-tuning an LLM for every new context or application demands considerable computational resources and time, making it a less scalable solution for applications needing to adapt to various domains or data sets swiftly.
What Is Retrieval Augmented Generation (RAG)?
RAG is a system design pattern that leverages information retrieval techniques and generative AI models to provide accurate and relevant responses to user queries. It does so by retrieving semantically relevant data to supplement user queries by additional context, combined as input to LLMs.
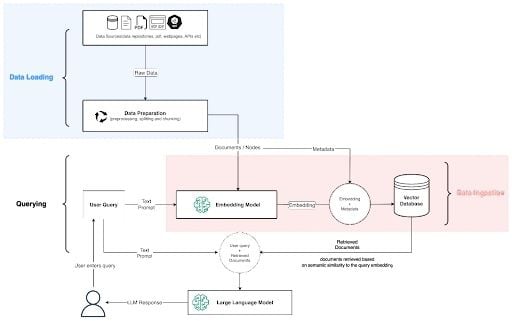
The RAG architectural design pattern for LLM applications enhances the relevance and accuracy of LLM responses by incorporating context from external data sources. However, integrating and maintaining the retrieval component can increase complexity, which can add to the system’s overall latency. Also, the quality of the generated responses heavily depends on the relevance and quality of the data in the external source.
RAG pipelines and systems rely on an AI stack, also known as either a modern AI stack or Gen AI stack.
This refers to the composition of models, databases, libraries and frameworks used to build modern applications with generative AI capabilities. The infrastructure leverages parametric knowledge from the LLM and non-parametric knowledge from data to augment user queries.
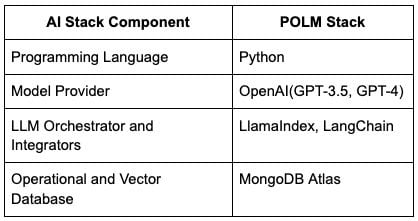
Components of the AI Stack include the following: Models, orchestrators or Integrators and operational and vector databases. In this tutorial, MongoDB will act as the operational and vector database.
How to Create a RAG System
The tutorial outlines the steps for implementing the standard stages of a RAG pipeline. Specifically, it focuses on creating a chatbot-like system to respond to user inquiries about Airbnb listings by offering recommendations or general information.
1. Install Libraries
The following code snippet installs various libraries that provide functionalities to access large language models, reranking models, and database connection methods. These libraries abstract away some complexities associated with writing extensive code to achieve results that the imported libraries condense to just a few lines and method calls.
- LlamaIndex: This is an LLM/data framework that provides functionalities to connect data sources — files, PDFs and websites, etc. — to both closed (OpenAI or Cohere) and open-source (Llama) large language models. The LlamaIndex framework abstracts complexities associated with data ingestion, RAG pipeline implementation and development of LLM applications.
- PyMongo: A Python driver for MongoDB that enables functionalities to connect to a MongoDB database and query data stored as documented in the database using various methods provided by the library
- Data sets: This is a Hugging Face library that provides access to a suite of data collections via specification of their path on the Hugging Face platform.
- Pandas: A library that enables the creation of data structures that facilitate efficient data processing and modification in Python environments.
!pip install llama-index
!pip install llama-index-vector-stores-mongodb
!pip install llama-index-embeddings-openai
!pip install pymongo
!pip install datasets
!pip install pandas
2. Data Loading and OpenAI Key SetUp
The command below assigns an OpenAI API key to the environment variable OPENAI_API_KEY. This is required to ensure LlamaIndex creates an OpenAI client with the provided OpenAI API key to access features such as LLM models (GPT-3, GPT-3.5-turbo and GPT-4) and embedding models (text-embedding-ada-002, text-embedding-3-small, and text-embedding-3-large).
import os
os.environ["OPENAI_API_KEY"] = ""The next step is to load the data within the development environment. The data for this tutorial is sourced from the Hugging Face platform, more specifically, the Airbnb data set made available via MongoDB. This data set comprises Airbnb listings, complete with property descriptions, reviews, and various metadata.
Additionally, it features text embeddings for the property descriptions and image embeddings for the listing photos. The text embeddings have been generated using OpenAI’s text-embedding-3-small model, while the image embeddings are produced with OpenAI’s CLIP-ViT-B/32 model, both accessible on Hugging Face.
from datasets import load_dataset
import pandas as pd
# https://huggingface.co/datasets/MongoDB/embedded_movies
# Make sure you have an Hugging Face token(HF_TOKEN) in your development environemnt
dataset = load_dataset("MongoDB/airbnb_embeddings")
# Convert the dataset to a pandas dataframe
dataset_df = pd.DataFrame(dataset['train'])
dataset_df.head(5)To fully demonstrate LlamaIndex’s capabilities and utilization, the ‘text-embeddings’ field must be removed from the original data set. This step enables the creation of a new embedding field tailored to the attributes specified by the LlamaIndex document configuration.
The following code snippet effectively removes the ‘text-embeddings’ attribute from every data point in the data set.
dataset_df = dataset_df.drop(columns=['text_embeddings'])
3. LlamaIndex LLM Configuration
The code snippet below is designed to configure the foundational and embedding models necessary for the RAG pipeline.
Within this setup, the base model selected for text generation is the ‘gpt-3.5-turbo’ model from OpenAI, which is the default choice within the LlamaIndex library. While the LlamaIndex OpenAIEmbedding class typically defaults to the ‘text-embedding-ada-002’ model for retrieval and embedding, this tutorial will switch to using the ‘text-embedding-3-small’ model, which features an embedding dimension of 256.
The embedding and base models are scoped globally using the Settings module from LlamaIndex. This means that downstream processes of the RAG pipeline do not need to specify the models utilized and, by default, will use the globally specified models.
from llama_index.core.settings import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=256)
llm = OpenAI()
Settings.llm = llm
Settings.embed_model = embed_model
4. Creating LlamaIndex custom Documents and Nodes
Next, we’ll create custom documents and nodes, which are considered first-class citizens within the LlamaIndex ecosystem. Documents are data structures that reference an object created from a data source, allowing for the specification of metadata and the behavior of data when provided to LLMs for text generation and embedding.
The code snippet provided below creates a list of documents, with specific attributes extracted from each data point in the data set. Additionally, the code snippet demonstrates how the original types of some attributes in the data set are converted into appropriate types recognized by LlamaIndex.
import json
from llama_index.core import Document
from llama_index.core.schema import MetadataMode
# Convert the DataFrame to a JSON string representation
documents_json = dataset_df.to_json(orient='records')
# Load the JSON string into a Python list of dictionaries
documents_list = json.loads(documents_json)
llama_documents = []
for document in documents_list:
# Value for metadata must be one of (str, int, float, None)
document["amenities"] = json.dumps(document["amenities"])
document["images"] = json.dumps(document["images"])
document["host"] = json.dumps(document["host"])
document["address"] = json.dumps(document["address"])
document["availability"] = json.dumps(document["availability"])
document["review_scores"] = json.dumps(document["review_scores"])
document["reviews"] = json.dumps(document["reviews"])
document["image_embeddings"] = json.dumps(document["image_embeddings"])
# Create a Document object with the text and excluded metadata for llm and embedding models
llama_document = Document(
text=document["description"],
metadata=document,
excluded_llm_metadata_keys=["_id", "transit", "minimum_nights", "maximum_nights", "cancellation_policy", "last_scraped", "calendar_last_scraped", "first_review", "last_review", "security_deposit", "cleaning_fee", "guests_included", "host", "availability", "reviews", "image_embeddings"],
excluded_embed_metadata_keys=["_id", "transit", "minimum_nights", "maximum_nights", "cancellation_policy", "last_scraped", "calendar_last_scraped", "first_review", "last_review", "security_deposit", "cleaning_fee", "guests_included", "host", "availability", "reviews", "image_embeddings"],
metadata_template="{key}=>{value}",
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
llama_documents.append(llama_document)
# Observing an example of what the LLM and Embedding model receive as input
print(
"\nThe LLM sees this: \n",
llama_documents[0].get_content(metadata_mode=MetadataMode.LLM),
)
print(
"\nThe Embedding model sees this: \n",
llama_documents[0].get_content(metadata_mode=MetadataMode.EMBED),
)The next step is to create nodes from the documents after creating a list of documents and specifying the metadata and LLM behavior. Nodes are the objects that are ingested into the MongoDB vector database and will enable the utilization of both vector data and operational data to conduct searches
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.schema import MetadataMode
parser = SentenceSplitter(chunk_size=5000)
nodes = parser.get_nodes_from_documents(llama_documents)
for node in nodes:
node_embedding = embed_model.get_text_embedding(
node.get_content(metadata_mode=MetadataMode.EMBED)
)
node.embedding = node_embedding
5. MongoDB Vector Database Connection and Setup
MongoDB acts as both an operational and a vector database for the RAG system. MongoDB Atlas specifically provides a database solution that efficiently stores, queries and retrieves vector embeddings.
Creating a database and collection within MongoDB is made simple with MongoDB Atlas.
- First, register for a MongoDB Atlas account. For existing users, sign into MongoDB Atlas.
- Follow the instructions. Select Atlas UI as the procedure to deploy your first cluster.
- Create the database: `airbnb`.
- Within the database` airbnb`, create the collection ‘listings_reviews’.
- Create a vector search index named vector_index for the ‘listings_reviews’ collection. This index enables the RAG application to retrieve records as additional context to supplement user queries via vector search. Below is the JSON definition of the data collection vector search index.
{
"fields": [
{
"numDimensions": 256,
"path": "embedding",
"similarity": "cosine",
"type": "vector"
}
]
}Below is an explanation of each vector search index JSON definition field.
fields: This is a list that specifies the fields to be indexed in the MongoDB collection and defines the characteristics of the index itself.numDimensions: Within each field item,numDimensionsspecifies the number of dimensions of the vector data. In this case, it’s set to 256. This number should match the dimensionality of the vector data stored in the field, and it is also one of the dimensions that OpenAI’stext-embedding-3-smallcreates vector embeddings.path: The path field indicates the path to the data within the database documents to be indexed. Here, it’s set to embedding.similarity: The similarity field defines the type of similarity distance metric that will be used to compare vectors during the search process. Here, it’s set to cosine, which measures the cosine of the angle between two vectors, effectively determining how similar or different these vectors are in their orientation in the vector space. Other similarity distance metric measures are Euclidean and dot products.type: This field specifies the data type the index will handle. In this case, it is set to vector, indicating that this index is specifically designed for handling and optimizing searches over vector data.
By the end of this step, you should have a database with one collection and a defined vector search index. The final step of this section is to obtain the connection to the uniform resource identifier (URI) string to the created Atlas cluster to establish a connection between the databases and the current development environment.
Don’t forget to whitelist the IP for the Python host or 0.0.0.0/0 for any IP when creating proof of concepts.
Follow MongoDB’s steps to get the connection string from the Atlas UI. After setting up the database and obtaining the Atlas cluster connection URI, securely store the URI within your development environment.
This guide uses Google Colab, which offers a feature for securely storing environment secrets. These secrets can then be accessed within the development environment. Specifically, the line mongo_uri = userdata.get('MONGO_URI') retrieves the URI from the secure storage.
The following steps utilize PyMongo to create a connection to the cluster and obtain reference objects to both the database and collection.
import pymongo
from google.colab import userdata
def get_mongo_client(mongo_uri):
"""Establish connection to the MongoDB."""
try:
client = pymongo.MongoClient(mongo_uri, appname="devrel.content.python")
print("Connection to MongoDB successful")
return client
except pymongo.errors.ConnectionFailure as e:
print(f"Connection failed: {e}")
return None
mongo_uri = userdata.get('MONGO_URI')
if not mongo_uri:
print("MONGO_URI not set in environment variables")
mongo_client = get_mongo_client(mongo_uri)
DB_NAME="airbnb"
COLLECTION_NAME="listings_reviews"
db = mongo_client[DB_NAME]
collection = db[COLLECTION_NAME]The next step deletes any existing records in the collection to ensure the data ingestion destination is empty.
# Delete any existing records in the collection
collection.delete_many({})
6. Data Ingestion
Using LlamaIndex, vector store initialization and data ingestion is a trivial process that can be established in just two lines of code. The snippet below initializes a MongoDB atlas vector store object via the LlamaIndex constructor MongoDBAtlasVectorSearch. Using the ‘add()’ method of the vector store instance, the nodes are directly ingested into the MongoDB database.
It’s important to note that in this step, we reference the name of the vector search index that’s going to be created via the MongoDB Cloud Atlas interface. For this specific use case, the index name: “vector_index”.
Vector Store Initialization
From llama_index.vector_stores.mongodb, import MongoDBAtlasVectorSearch.
from llama_index.vector_stores.mongodb import MongoDBAtlasVectorSearch
vector_store = MongoDBAtlasVectorSearch(mongo_client, db_name=DB_NAME, collection_name=COLLECTION_NAME, index_name="vector_index")
vector_store.add(nodes)- Create an instance of a MongoDB Atlas Vector Store:
vector_storeusing theMongoDBAtlasVectorSearchconstructor. db_name="airbnb": This specifies the name of the database within MongoDB Atlas where the documents, along with vector embeddings, are stored.collection_name="listings_reviews": Specifies the name of the collection within the database where the documents are stored.index_name="vector_index: This is a reference to the name of the vector search index created for the MongoDB collection.
Data Ingestion
vector_store.add(nodes): Ingests each node into the MongoDB vector database where each node represents a document entry.
7. Querying the Index With User Queries
To utilize the vector store capabilities with LlamaIndex, an index is initialized from the MongoDB vector store, as demonstrated in the code snippet below.
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_vector_store(vector_store)The next step involves creating a LlamaIndex query engine. The query engine enables the functionality to utilize natural language to retrieve relevant, contextually appropriate information from a vast index of data. LlamaIndex’s **as_query_engine** method abstracts the complexities of AI engineers and developers writing the implementation code to process queries appropriately for extracting information from a data source.
For our use case, the query engine satisfies the requirement of building a question-and-answer application, although LlamaIndex does provide the ability to construct a chat-like application with the Chat Engine functionality.
import pprint
from llama_index.core.response.notebook_utils import display_response
query_engine = index.as_query_engine(similarity_top_k=3)
query = "I want to stay in a place that's warm and friendly, and not too far from resturants, can you recommend a place? Include a reason as to why you've chosen your selection"
response = query_engine.query(query)
display_response(response)
pprint.pprint(response.source_nodes)
Initialization of Query Engine
- The process starts with initializing a query engine from an existing index by calling
index.as_query_engine(similarity_top_k=3). - This prepares the engine to sift through the indexed data to identify the top k (3 in this case) entries that are most similar to the content of the query.
- For this scenario, the query posed is: “I want to stay in a place that’s warm and friendly and not too far from restaurants, can you recommend a place? Include a reason as to why you’ve chosen your selection.”
- The query engine processes the input query to find and retrieve relevant responses.
Observing the Source Nodes
The LlamaIndex response object from the query engine provides additional insight into the data points contributing to the generated answer.
Understanding How to Build a RAG System
In this tutorial, we’ve developed a straightforward query system that leverages the RAG architectural design pattern for LLM applications, utilizing LlamaIndex as the LLM framework and MongoDB as the vector database. We also demonstrated how to customize metadata for consumption by databases and LLMs using LlamaIndex’s primary data structures, documents and nodes. This enables more metadata controllability when building LLM applications and data ingestion processes. Additionally, it shows how to use MongoDB as a Vector Database and carry out data ingestion.
By focusing on a practical use case — a chatbot-like system for Airbnb listings — this guide walks you through the step-by-step process of implementing a RAG pipeline and highlights the distinct advantages of RAG over traditional fine-tuning methods. Through the POLM AI Stack — combining Python, OpenAI models, LlamaIndex for orchestration and MongoDB Atlas as the dual-purpose database, developers are provided with a comprehensive tool kit to innovate and deploy generative AI applications efficiently.


