

Imagine a world where businesses can quickly collect and analyze both structured and unstructured data from various sources, making well-informed decisions in minutes. This is the potential of AI-powered business intelligence, where AI handles the heavy lifting and humans reap the rewards.
How Generative AI Works in Text Data Extraction
Generative AI specializes in extracting entities from unstructured text. It starts with using NLP to clean the text data, which then prepares the data for consumption by generative AI models. Transformers then process the cleaned data to extract relevant information and the models identify patterns.
Recent evolutions in hardware, notably the Nvidia H100 GPU, have substantially boosted computational power to make this possible. The GPU is nine times faster than its predecessor, the Nvidia A100, making it highly effective for deep learning tasks. It has accelerated the use of generative AI in fields like natural language processing (NLP) and computer vision, facilitating smart and automated data extraction. Here’s what that means for businesses.
Traditional Methods of Data Extraction
Manual Data Entry
Manual data entry is still a popular choice for many businesses due to its low initial cost. However, this method is tedious and error-prone, and it poses a security risk with sensitive data, making it less suitable in today’s automated and secure digital environment. In the long run, its slow speed and need for a large team result in higher operational costs.
Optical Character Recognition (OCR)
OCR technology converts images and handwritten content into machine-readable data, providing a quicker, more cost-effective data extraction method. However, its reliability can vary. For instance, it might confuse the character “S” with “8”. OCR performs best with high-resolution images that are free from orientation tilts, watermarks, or overwritten text but struggles with complex or intricate handwritten text. While many OCR-based tools enhance accuracy through extensive post-processing, they still can't ensure 100 percent accuracy
Named Entity Recognition (NER)
NER is an NLP technique that identifies and categorizes key information in text, such as organization names, locations, personal names, and dates. However, NER is limited to these predefined entities and cannot extract custom entities specific to certain domains or use cases. Additionally, NER is not effective for extracting data from tables, which restricts its use with more complex or structured data.
Text Pattern Matching
Text pattern matching is a method used to identify and extract specific information from text using predefined rules or patterns. This approach is faster and offers a higher ROI compared to other methods. It is highly effective and ensures 100 percent accuracy for files with similar layouts.
While this method is effective when dealing with consistently formatted unstructured reports, creating these templates is a labor-intensive process. It takes about 10 minutes to set up a template. This process is cumbersome and impractical for large-scale data extraction, where creating hundreds of templates could take over 1,000 minutes.
How Generative AI Works in Data Extraction
Generative AI has rapidly advanced thanks to the widespread availability of big data and significant improvements in computing power, particularly GPUs. This progress has enhanced deep neural networks (DNNs) in areas such as NLP and unstructured data management.
A key application of generative AI is extracting entities from unstructured text. This process begins with preprocessing and cleaning the text data using NLP techniques like tokenization, speech-to-text conversion and part-of-speech tagging. These steps prepare the data for consumption by generative AI models, especially transformers, which then process the cleaned data to extract relevant information. Trained on extensive data sets of text and code, these models can identify patterns and correlations that are challenging for traditional methods.
Transformers, used in large language models like GPT, BERT and OPT, operate on an “attention” mechanism that enhances data processing by focusing on relationships within the data. For example, in invoice processing, the self-attention feature of transformers recognizes relevant dates for payments, while multi-head attention allows the model to focus simultaneously on different data aspects, such as amounts and vendor names. This multifaceted attention ensures a comprehensive understanding and extraction of data, improving both accuracy and efficiency in handling complex documents like software manuals, legal contracts and financial documents.
Overcoming Challenges in Generative AI Data Extraction
Eliminating manual tasks has been a consistent challenge for our data extraction solution, Astera ReportMiner. Over time, Astera has introduced semi-automatic features to aid in template generation.
To minimize manual effort, we combined computer vision and natural language processing with a heuristics layer to automate the layout generation for simpler invoices and purchase orders. This feature called Auto Generate Layout (AGL), leverages open-source Python libraries like tabula-py for table detection and spaCy for key-value pair extraction to construct layouts automatically. However, this method has faced limitations, struggling to scale for more complex cases, which include processing a high volume of unstructured documents with both uniform and varying layouts while maintaining speed and accuracy.
To overcome these limitations, the shift to generative AI began with the introduction of GPT3.0, leading to two major innovations: AI-recommended templates and the generative information extractor (GenIE).
AI-recommended templates automate the creation of structured templates from unstructured reports at design-time, reducing manual effort by 99% during post-processing. These templates can be used in automation engines to process thousands of similar documents efficiently.
GenIE, on the other hand, is a run-time template-less conversion of unstructured data to structured tables. This technology solved our long-standing problem of extracting specific data points from documents with non-existent schema or a continuously changing layout, all while the process is running. The GPT-integrated technology also surpassed all traditional or handcrafted features in terms of accuracy, capability and processing speed.
In both AI-based methods, the extraction essentially works on the principles of semantic matching, output parsing and attention mechanism of generative pre-trained models. Both template-based and template-less methods cater to specific sets of use cases of their own.
AI Recommended Templates
The process begins by making consecutive real-time API calls to a large language model (LLM), functioning like a sequence-to-sequence Q&A task. Each API call processes a tokenized invoice document along with system-defined instructions. The “system” prompt sets up context-aware extraction and includes an output parser, while the “user” prompt inputs text segments from the source document. The data extraction API returns JSON output which is reverse engineered to display inside a report model template for a reusable and automated extraction process.
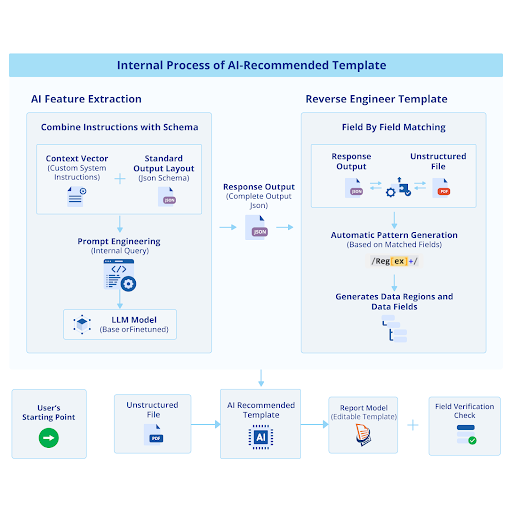
A field verification check is automatically performed at the end of the template generation to ensure accuracy. If any field does not pass this check, the template is dropped into the “Erroneous Report Model” folder with a warning flag to inform the user about the need for manual intervention. This efficient method allows for rapid data extraction from multiple templates in just a few seconds.
This method excels when processing a high frequency of unstructured data with little to no variations in the source layout. It is a design-time process.
Generative Information Extractor (GenIE)
We trained and fine-tuned a LLM to power a template-less data extraction process generative information extractor (GenIE). This process is structured into three main segments:
- Fine-tuning Pipeline: A pre-trained LLM is further refined using Astera’s training data. The enhanced model is then deployed via an API to the consolidation layer.
- Accuracy Computation Process: This stage involves processing unstructured files (such as PDFs) through an embedding model. The generated embedding vectors are stored in a vector database to measure accuracy.
- Consolidation Layer: Finally, the consolidation layer couples the finetuning layer and accuracy layer to orchestrate the extraction of data without traditional templates. It uses few-shot learning to generate a system prompt that includes both instructions and an output parser.
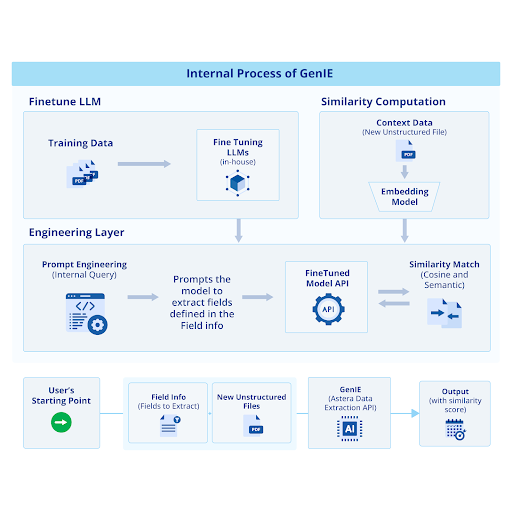
The three components of GenIE operate within a black box system. Users simply input an unstructured file and specify output fields, and the model quickly returns the extracted data along with its accuracy score.
It’s important to note that template-less extraction is not a replacement; rather, its purpose is to handle large variations of unstructured data or to extract data from files that have no structure at all, such as contracts and manuals.
However, both methods can be used systematically. For example, imagine there are 1000 different layouts of purchase orders. For simpler ones with fewer variations, AI-recommended templates are likely to be used. For those that are simple yet have a large number of variations, the template-less method will be employed. For those that are complex and not resolved by the template-less method, templates will be manually created.
Future of Generative AI in Data Extraction
Generative AI shows promise in extracting textual data from reports, yet it still has challenges to overcome such as errors from OCR processing and difficulties in text extraction from images within reports. Innovative solutions like multimodal data processing and token limit extensions in models like GPT-4, Claud3, and Gemini present a way forward.
It’s important to recognize that these AI models are typically accessed via APIs, which, while cost-effective and efficient, pose challenges such as latency, limited control, reliance on network connectivity, and potential data privacy and security risks. An alternative is using an in-house, fine-tuned LLM. This approach not only reduces privacy and security risks but also allows for greater customization and control. Fine-tuning an LLM to understand document layouts and perform context-aware semantic parsing is more effective for extracting data from structured documents like forms. By leveraging zero-shot and few-shot learning, such a model can adapt to various document layouts, providing efficient and accurate data extraction across different domains.


