

One of AI’s most prominent use cases is deep research. This process involves using AI agents to search the web for information, which then automatically compile that information into exhaustive reports with thoughtful analysis and citations. It’s also highly competitive. Several AI companies that have become household names including OpenAI, Gemini, Claude, Grok, Perplexity and DeepSeek, all provide their own automated research tools.
Modern AI can, of course, also be used for interactive human-in-the-loop research, whereby humans use AI to rapidly research and answer questions and ask new questions based on those answers. On an individual level, this describes many ChatGPT sessions; on an enterprise level, swarms of AI agents can be used to do research at scale. One example is analyzing every company in the S&P 500 and answering a given question for each of them.
But how good are these automated research tools? Which LLMs are best for interactive research? And is automated or interactive research better?
Until very recently, these questions were unanswerable. Since the introduction of modern AI, quantitative benchmarks have been used to compare different models and approaches, but no benchmarks have been developed to identify which tools are best suited — until now. We introduce that benchmark in our Deep Research Bench, a rigorously crafted benchmark that evaluates how effectively AI systems handle multistep, web-based research problems. Rather than quick fact‑lookup queries, its tasks mirror the messy, open‑ended investigations that real‑world analysts, policymakers and researchers routinely undertake.
Deep Research Vs. Interactive Research: What’s the Difference?
- Deep research involves an autonomous LLM agent that runs its own searches, uses multiple tools, self‑corrects and (in theory) persists or adapts when it hits roadblocks. This process involves no human steering once it is launched.
- Interactive research is a human‑in‑the‑loop-driven process in which a human guides smaller automated steps, inspects reasoning traces and iteratively refines or reruns portions of the analysis.
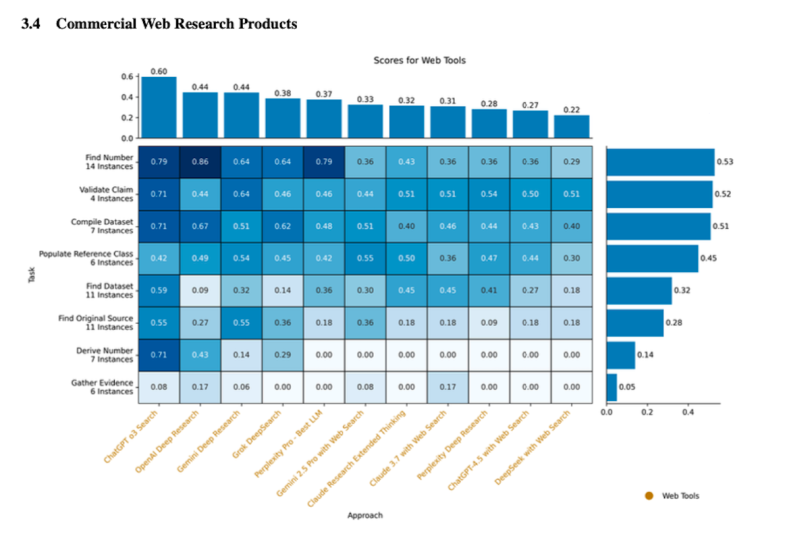
How Good Is Your Deep Research?
Our research found which LLMs are best suited for AI-assisted research and included an evaluation of a suite of commercial web research products:
- OpenAI Deep Research
- Gemini Deep Research
- Grok DeepSearch
- Perplexity Deep Research
- Claude Research
- DeepSeek with web search
Of those, OpenAI Deep Research and Gemini Deep Research performed best.
Two important notes:
- This is a relative ranking. None of these tools consistently succeeded at all or even a substantial majority of the individual tasks in the benchmark. No AI deep research tool is anywhere close to completely successful when precise, rigorous, quantified accuracy is required. They are very good at getting broad overviews when it’s not essential that every little detail be there or correct — which, to be fair, is very valuable — but they are not good in cases where any mistake is a big problem.
- The best-performing commercial tool was not a deep research tool, but rather ChatGPT-o3 with web search, which has a greater propensity than OpenAI Deep Research to try to carefully validate its answers before completing. o3’s reasoning traces tend to include the caveat, “What if this initial research is wrong? How can we double-check it?” It also includes secondary sources more often than Deep Research.
While some users may prefer using a particular deep research tool because they want additional background information rather than 100 percent accuracy, there are cases where users prefer a longer treatment of an unfamiliar subject. For instance, they may have a new position and want to catch up on as much as possible about the relevant subjects more than they want research conclusions.
When rigor and reliable accuracy are required, no current deep research tool is fit. The reasons for this include:
- Simple hallucinations, which remain a problem (and have even increased in recent models such as o3 and DeepSeek R1)
- Gullibility (mistaking unreliable sources for reliable ones.) It’s not unusual for an LLM to interpret a claim in a random blog post citing another random blog post as dispositive, without ever bothering to track down any original high-quality source for the claim. Satire and parody are even more problematic; Google Search recently took the joke “The final stage of your Ph.D. defense includes fighting a snake” seriously. This is very much an outlier, to be clear, but it illustrates the problem. Simple misjudgments can also add confusion to the mix; for example, seeing a reference to “in February” in a report dated March 2025 and wrongly interpreting that as meaning February 2024.
- Errors that start out small can cascade and grow in significance. Early errors lead to agents making increasingly poor decisions as they proceed through the research workflow.
We Still Need Humans in the Loop
It’s clear that automated AI research tools are extremely impressive and improving rapidly. It’s also clear that, for the foreseeable future, human oversight and error-checking will be necessary for rigor and accuracy. This is especially true given the recent resurgence in hallucination rates among frontier models.
The inevitable conclusion is that, when accuracy is crucial, interactive research, where humans assess AI outputs and make iterative decisions, will remain substantially better than existing deep research tools. This will be true as long as humans are better than AI at:
- Error-checking: Identifying hallucinations, gullibility, misjudgements and other AI errors; and
- Ideation: Interpreting answers and using that new information to dynamically decide the direction that the research should take.
We humans are currently much better at both of these things. We expect the gap between human and AI error-checking to close significantly over the coming years, as considerable work goes into teaching LLMs to recognize their own mistakes. Hallucinations are persistent, however, and judgement is tricky. Because any missed error is at risk of cascading, closing the gap will take longer than the frontier companies hope.
A more interesting question is how long the gap between human and AI ideation will persist. The heart of any research process is knowing the best next questions to ask, given a new set of answers. This is much closer to the elusive concept of AGI. The implication is that human-assisted interactive research will remain superior to fully automated deep research even when LLMs are as good at error-checking as humans ... until and unless AIs become as intelligent as humans more generally.


