

In this article, we’ll review a generic joins framework for entity relationship using GraphFrames on Databricks. The framework addresses the challenge of maintaining isolated data processing jobs by providing a scalable approach to entity relationships or generic joins. We demonstrate how GraphFrames can efficiently handle complex relationships between entities, supporting up to two levels of joins through a streaming architecture. The implementation significantly reduces development time for new data integration requirements while improving overall system performance.
The Value of Contextualized Data
Enterprise knowledge graphs typically store a vast array of disconnected entities. When applications require contextualized data, such as calendar events with their attendees and attachments or content pages with creators and subpages, developers often resort to creating one-off solutions involving complex joins, aggregations and data sinks. These custom solutions become difficult to maintain as product requirements evolve and new entity relationship types emerge.
We have used GraphFrames, a package for Apache Spark that provides DataFrame-based graphs. GraphFrames extends the functionality of GraphX while taking advantage of Spark DataFrames. The extended capabilities include motif finding, DataFrame-based serialization and highly expressive graph queries, making it ideal for our entity relationship management needs.
Problems With Contextualized Data in Databricks
On our Databricks platform, we have persistent knowledge data, but retrieving contextualized information (e.g., calendar events with attendees) requires building individual jobs that perform joins, aggregation and output to external systems. These jobs presented several challenges:
- High maintenance overhead due to isolated implementations.
- Inefficiency as product requirements evolved to include more relationship types.
- Redundant code across similar processing tasks.
- Lack of standardization in how entity relationships are processed.
- Performance issues with complex multi-level relationships.
Two-Level Generic Joins Framework
Our solution implements a generic framework using GraphFrames to efficiently handle entity relationships. The current implementation supports up to two levels of joins (though the architecture could extend further), enabling complex relationship patterns such as:
- GoogleCalendarEvent with attendees and attachments
- Google Document with comments and authors
Core Components
The framework consists of five primary steps implemented as a Databricks job:
5 Steps to a Generic Joins Framework
- Streaming query.
- Batch processing.
- Motif pattern finding.
- Grouped view generation.
- Delta merge.
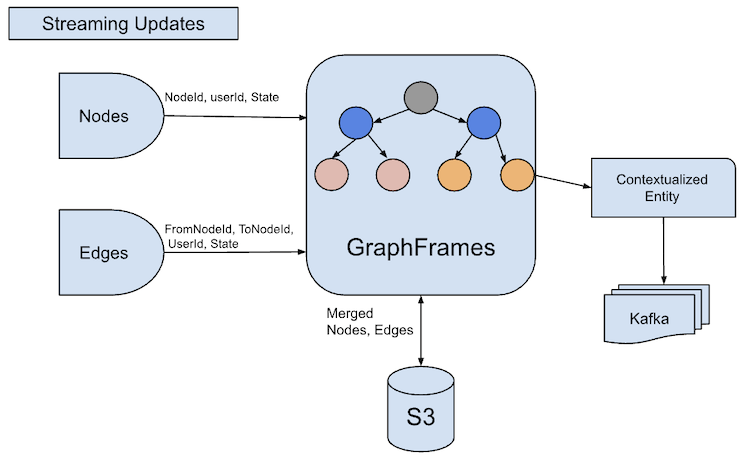
1. Streaming Query
- Processes streaming updates for nodes that have changed since the last batch.
- Monitors edge changes (fromNodeId, toNodeId) since the last batch.
- Joins the two streams and processes batches together to ensure consistency.
2. Batch Processing
- Reads consistent nodes and edges with appropriate filters to reduce data set size.
- Applies unique user ID filtering to limit the context to relevant data.
- Handles data deduplication based on event timestamps and data sources.
- Manages deletes as soft deleted records to publish changes related to deleted nodes.
3. Motif Pattern Finding
- Constructs a graph from the processed nodes and edges using GraphFrames.
- Executes motif queries to find one and two-level join patterns.
- Identifies all affected paths for nodes that changed in the current batch.
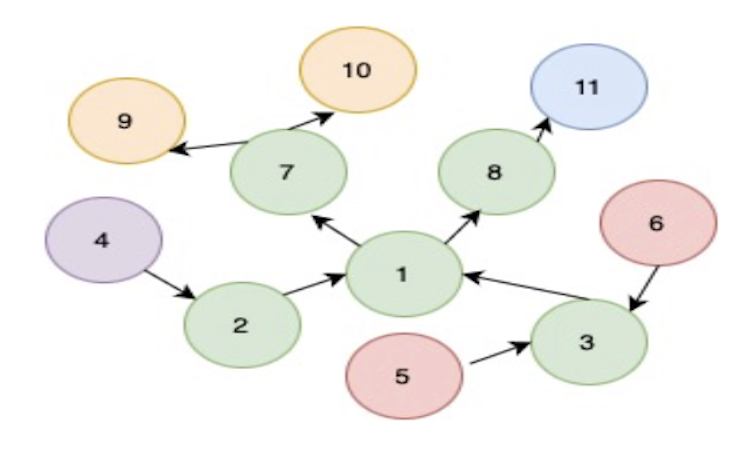
- Determines bidirectional impact (upstream and downstream) for comprehensive updates. For example, node one change could impact upstream nodes two through five and downstream nodes seven through 11 for two level joins.
4. Grouped View Generation
- Filters out deleted edges and nodes from the motif findings.
- Maintains a record of all impacted nodes to ensure complete update propagation.
- Generates a consolidated view for all identified graph IDs.
- Processes isolated nodes (those with no connections) separately.
- Publishes both connected and isolated nodes to ensure comprehensive updates.
5. Delta Merge
- Collects the grouped view into a unified contextualized entity format.
- Merges this data to a Delta table with upsert semantics.
- Ensures exactly one row per node ID in the final output.
- Applies change detection logic to only persist actual changes.
- Optimizes downstream data consumption by eliminating redundant updates.
Implementation Details
1. Graph Construction
The framework builds a graph representation using nodes (entities) and edges (relationships) where:
- Nodes represent distinct entities (e.g., calendar events, contacts, documents).
- Edges represent relationships between entities (e.g., “has attendee,” “created by”).
2. Motif Queries
GraphFrames provides powerful motif finding capabilities that we leverage for relationship discovery:
Level One Join
“(a)-[e0]->(b)”
This finds direct relationships (e.g., GoogleCalendarEvent a” that has attachment b”).
Level Two Join
“(a)-[e0]->(b); (b)-[e1]->(c)”
This discovers two-step relationships (e.g., GoogleCalendarEvent A that has attachment B created by GoogleContact C).
3. Change Propagation
When an entity or relationship changes, the framework:
- Identifies the affected node(s).
- Traces all paths up to two levels deep that include the changed elements.
- Updates the joined entity view to reflect the current state.
4. Grouped View Processing
The grouped view processing is critical for ensuring comprehensive updates:
- Filtering is applied after motif finding rather than during graph creation to ensure all impacted neighbors are identified.
- This approach captures the complete set of affected entities, even when relationships are being removed.
- The view consolidates all relationships for each node, providing a holistic representation.
- Both connected entities and isolated nodes are processed, ensuring no updates are missed.
5. Delta Table Management
The Delta merge step optimizes persistence and downstream consumption:
- Data is merged into a Delta table using upsert semantics to maintain a single source of truth.
- Change detection logic ensures only actual changes trigger downstream updates.
- The unified contextualized entity format standardizes how relationship data is stored.
- This approach significantly reduces the processing burden on downstream consumers.
Performance Considerations
Several optimizations ensure efficient processing:
1. Streaming Updates
Only processing changed nodes and edges rather than full data set scans.
2. Selective Loading
Filtering nodes and edges based on context to reduce the working data set.
3. Bidirectional Impact Analysis
Identifying only affected paths rather than rebuilding entire graphs.
4. Batch Processing
Grouping updates for efficient processing.
5. Change-Based Merging
Only persisting actual changes to minimize IO operations.
Results and Benefits
The implementation of this framework has yielded several significant benefits:
1. Reduced Development Time
New entity relationship requirements can be onboarded without custom join logic.
2. Standardized Processing
It introduces a consistent approach to entity relationships across the platform.
3. Improved Maintenance
The centralized framework reduces the number of specialized jobs.
4. Enhanced Performance
Optimized graph operations outperform traditional relational joins for complex relationships.
5. Flexibility
Support for different entity types and relationship patterns without code changes.
6. Efficient Downstream Consumption
Minimized updates reduce processing load for consumers.
Future Work
While the current implementation supports up to two levels of joins, future enhancements could include extending to deeper relationships (three or more levels), adding support for more complex graph patterns and filtering and creating visualization tools for entity relationship exploration.
The generic joins framework using GraphFrames provides an efficient and maintainable solution for entity relationship management in our knowledge graph. By using graph-based processing instead of traditional relational joins, we’ve created a scalable architecture that can adapt to evolving product requirements with minimal development overhead.
The streaming architecture ensures that changes propagate quickly through related entities, maintaining data consistency while optimizing processing resources. The grouped view generation and Delta merge steps further enhance the solution by providing optimized data persistence and consumption patterns. This approach not only solves the immediate challenge of maintaining isolated data processing jobs but also establishes a foundation for more sophisticated knowledge graph applications in the future.


