

Comma separated values (CSV) can be considered a type of database that stores data in a table format. CSV is used everywhere, from data reports to machine learning to storing the data set and beyond.
Querying a CSV File Stored in AWS S3 Using Athena Guide
- Prepare a CSV file.
- Create a bucket in Amazon S3.
- Create a table in AWS Athena.
Most companies still use CSV as a ‘db’. As a data analyst, it’s important to know how to analyze a CSV table using SQL in business intelligence (BI) tools. If you’re working in an AWS environment, here’s how to do it.
3 Steps to Query CSV File Stored in AWS S3 Using Athena
1. Prepare a CSV File
You can skip this step if you already have a CSV file on your local. If you don’t, here’s what you need to do:
- Install Python on your local machine.
- Install a
fakerlibrary to get dummy data. - Prepare the CSV with
'first_name','last_name','age'as headers. - Now, open the folder, and
dummy-data.csvshould be created inside it:
import csv
from faker import Faker
fake = Faker()
number_of_records = 8000
with open('dummy-data.csv', mode='w+') as file:
file_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
file_writer.writerow(['first_name', 'last_name', 'age'])
for _ in range(number_of_records):
file_writer.writerow([fake.first_name(), fake.last_name(), fake.numerify("@#")])2. Create a Bucket in Amazon S3
If you already have a bucket, you can use the existing one. Otherwise, you’ll need to create a bucket:
- Go to AWS Console, search S3 and click “Create Bucket.”

How to create a bucket in AWS console. | Screenshot: Mohamad Amzar - Fill up the necessary fields and create bucket.
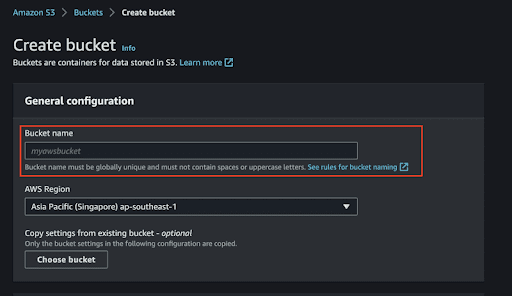
Filling in fields to create a bucket in Amazon S3. | Screenshot: Mohamad Amzar - A new bucket is created. Now you can decide whether to create a new folder inside the bucket. For me, I want to have a separate folder for dummy data, so, I created a
dummy_datafolder. - Click “Create folder.”
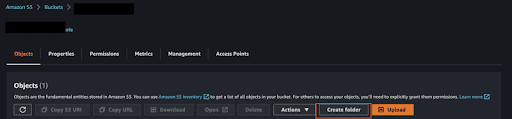
Creating a folder in Amazon S3. | Screenshot: Mohamad Amzar - Fill up the necessary fields and create folder.
- The new folder is created in the bucket.
- Now, upload the
.csvfile by drag to the page.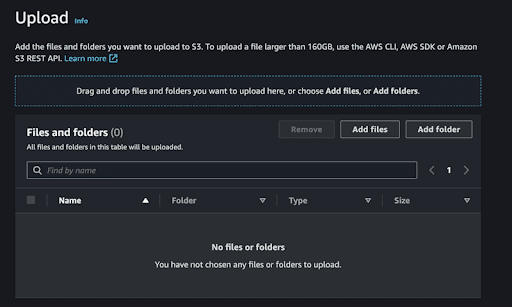
Uploading a CSV file in S3. | Screenshot: Mohamad Amzar - You can refresh or go back to the bucket folder to see the imported CSV file.
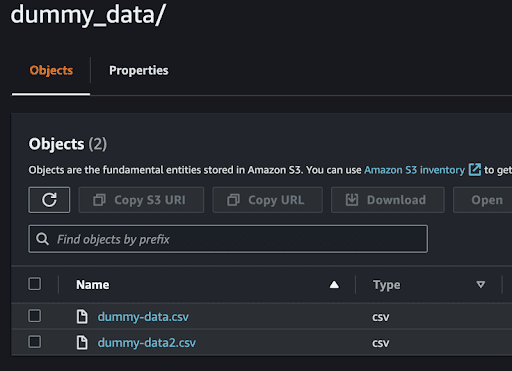
Finding the imported CSV file in S3. | Screenshot: Mohamad Amzar - Don’t forget to copy the S3 unique resource identifier of the folder to create an Athena table.
3. Create a Table in AWS Athena
If you want to create another database, you can use the below query: CREATE DATABASE myDataBase
To create a table in Athena, you first need to define the structure of the table so that Athena table is able to know the data structure is in CSV file. You can do this in the AWS Management Console or the AWS CLI.
For this post, I am using AWS Management Console. Like the S3 service, you can open your AWS Console and search Athena.
Populate the table using the query below:
CREATE EXTERNAL TABLE dummy_person (
first_name string,
last_name string,
age string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '"',
'escapeChar' = '\\'
)
LOCATION '[S3 URI]'
TBLPROPERTIES ("skip.header.line.count"="1");
Table is created.
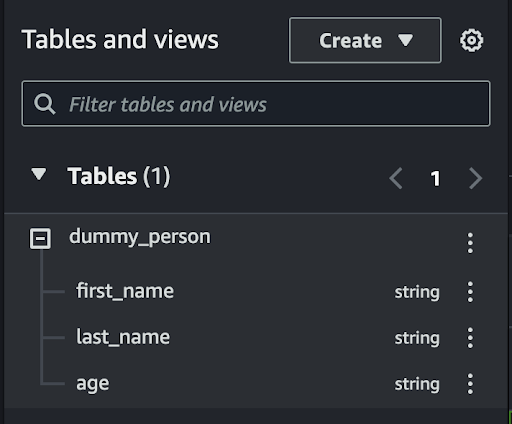
Run SQL queries to check the data has been populated.
select * from dummy_person Now, you can see the data.
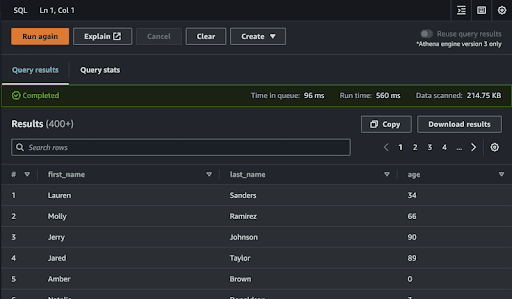
With that, you can connect Athena to your BI tools and start to develop the dashboard.
Frequently Asked Questions
How do you query a CSV file stored in AWS S3 using Athena?
You can query a CSV file stored in AWS S3 using Athena following these three steps:
- Prepare a CSV file.
- Create a bucket in Amazon S3.
- Create a table in Athena and populate it with the following code:
CODE
- Connect Athena to your business intelligence tools and develop the dashboard.
What is AWS Athena?
AWS Athena is a serverless query service that can be used to analyze data stored in S3 through SQL.


