

We’re five years into the “AI Revolution.” Cars are starting to drive themselves, fake images and videos are becoming more common on Facebook, and many U.S. cities now have stores without cashiers. Without a doubt, intelligent software has never before permeated so much of our lives or the business world.
As the technology has progressed, a clear trend has emerged: The largest players (Google, Facebook, Amazon) have great success with massive deployments of highly advanced models, while smaller players have struggled with more modest implementations. Countless enterprises have conducted pilot AI rollouts only to be frustrated by delays, missed budgets, and outcomes well below what had been anticipated.
These enterprise challenges have been driven in large part by a lack of understanding of the interrelationships between the data you have, the models you’re using and the results that you can expect. In many cases, corporations set their sights on a problem that requires an advanced deep neural network trained on hundreds of thousands of high-quality data points, even though the organization has literally no data or in-house expertise to develop advanced models.
Enter the AI Sophistication Curve. This model is the recipe for success for organizations beginning to explore intelligent software. It lays out a path for AI implementation success, starting with no data and the most basic of “intelligence.” It provides guidance on how to advance from that basic state to a world-class model. Most importantly, it helps frame the conversation about how far your organization actually needs to progress along the curve for any given model.
The Approach
The idea behind the AI Sophistication Curve is to start from scratch and then improve your results progressively through continuous feedback. “From scratch” means all you need is a basic understanding of the problem you’re trying to address and a team with basic software product deployment capabilities. You don’t need any special AI or data science expertise.
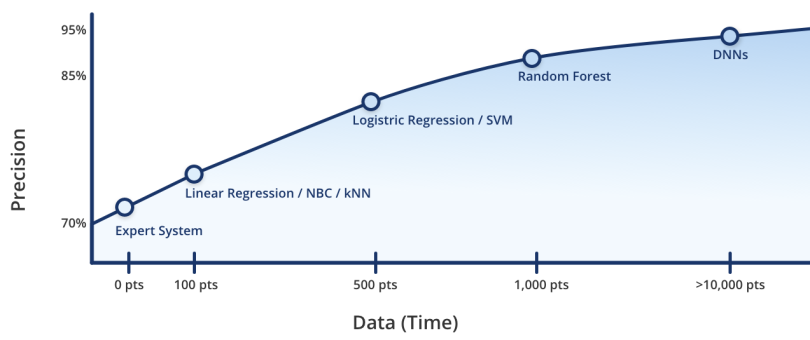
The curve begins with a basic software implementation that any standard team should be able to implement. It then includes some mechanism for effecting progress: a way of gathering feedback about the successes or failures of the implementation. In essence, you’re putting out a basic solution that will allow you to start gathering high-quality, relevant data to drive more sophisticated implementations along the curve. That mechanism most often comes in the form of either feedback on accuracy from the end-user or feedback from an employee paid to train the model who is augmented by the predictions of the basic model.
As you gather data, you can begin implementing progressively more advanced machine learning models. This gradual progression means that your team can learn along the way; as long as they’re willing to learn, there’s no need for specific skillsets in machine learning or AI more broadly.
There is no limit to how far along the sophistication curve you can progress. As time goes by and you collect more data, you should be able to implement more and more advanced models that will generate better outcomes. The gradual progression allows you to be conscious of the investment you’re making, meaning that you can ramp down your efforts once you’ve achieved the optimal performance of your system.
Getting Started: Expert Systems
Artificial Intelligence has been around since the 1950s. For the vast majority of the time since then, “AI” in the business world has referred to expert systems. Some may even remember the first AI renaissance in the 1980s, which was driven entirely by this type of software.
An expert system is the codification of human (“expert”) knowledge into software. For instance, triage software in a hospital may use manually programmed rules around levels of pain and degrees of infectiousness to assess which patients need most immediate care from doctors and nurses.
Among CTOs, there is some debate as to whether or not expert systems qualify as artificial intelligence at all. In the modern AI revolution, machine learning technologies (that get “smarter” as you feed them more data) are all the rage. Still, expert systems have a lot to offer every enterprise and are a great place to get started when implementing intelligent models.
The advantage of these systems is that they require no special AI expertise or data set. You can just get together your business expert(s) with a standard software development team and get a model working in production.
It’s worth noting that these basic implementations of expert systems will almost never perform as well as an advanced machine learning model. At my own company, 4Degrees, we typically shoot for accuracy around the 70-75 percent range: For every four guesses the model makes, it’s going to get one wrong. Accordingly, you should set expectations for the end-consumer of the model to not expect perfect results.
Basic Machine Learning Models
Once you’ve had a chance to implement a basic expert system and begin to collect data from the real world, you can begin thinking about implementing a basic machine learning model. Examples of basic models include linear regression, naive Bayes classifiers, and k-nearest neighbors. These models generally have only basic relationships between input variables and do not require much data to get running.
At 4Degrees, we typically start seeing decent results (i.e. around the level of expert systems) at 100-300 data points. Depending on your use case, this may be a trivial amount that can be collected in a matter of hours.
Intermediate Models
After you implement the most basic of ML models, you can start thinking about how you’re going to make your model more advanced and improve performance. In many cases, this means “upgrading” the model when you get more data. At around 500 data points, you can implement a logistic regression or support vector machine (SVM) model. Intermediate models allow for more complex relationships between variables and can generate higher accuracy predictions, assuming you have the data to feed them.
Generally, around this time, your team can also invest in non-model methods of improving accuracy. One of the best examples is data engineering: putting a bit of work into cleaning and/or augmenting the data you’re collecting so that it’s better suited to the model(s) you’re using. Data engineering is a massive domain on its own and offers ample opportunity for your team to experiment and learn.
In our experience at 4Degrees, the intermediate model step typically allows for prediction accuracy levels of 75-80 percent, meaningfully better than what can be achieved through a basic expert system implementation.
Advanced Models
As time goes by and you collect more data, you can begin to think about some of the more complex machine learning models. Decision trees and random forests may become relevant around 1,000 data points. Eventually, you may get into the domain of deep neural networks (also called deep learning), which often requires tens or hundreds of thousands of data points.
While experimentation with more advanced models is important as your data set grows, oftentimes, the best results come with a more intense focus on the meaning, cleanliness, and quality of your model’s input data. In fact, this understanding and manipulation of the data is probably more important than the model itself.
There is no known ceiling to the performance of advanced models in any domain. In many areas, these models outperform humans at predictions. It is theorized that they will outperform humans generally in the not-too-distant future. The only barrier to your continued progress along the curve is the capabilities of your team and the resources you’re willing to invest.
Knowing When to Stop
The magic of the AI Sophistication Curve is that it’s a gradual slope: Each step requires investment and planning for progress. This progression means there’s ample opportunity to evaluate whether or not you’ve achieved the objective you set out for.
Where you should stop on the curve depends a lot on the problem you’re trying to solve. If your model is a low-criticality input into a larger, more complex system that can handle some standard error, then you may be fine at the expert system or basic model level. On the other hand, if your predictions are being handed directly to an end user with a low tolerance for error, then you may want to keep investing indefinitely.
The key to the curve is having a solid understanding of the effort you’re putting in and the reward you’re getting out. That understanding should be based on historical efforts and can be forecasted to make fairly accurate predictions about the relative cost (or profit) of continued investment.


