

Open-source software is the backbone of machine learning. The rapid advancements in this field wouldn’t be possible without the contribution of the open-source community. Many of the most widely used tools in machine learning are open source and every year more and more libraries get added to this ecosystem. In this article, I present a quick tour of some of the libraries that could be a great supplement to your machine learning stack.
5 Machine Learning Libraries for Your Stack
- Hummingbird
- Top2Vec
- BERTopic
- Captum
- Annoy
1. Hummingbird
Hummingbird is a library for compiling trained traditional machine learning models into tensor computations. This means you can take advantage of hardware acceleration like GPUs and TPUs, even for traditional machine learning models. This is beneficial on several levels.
- Users can benefit from current and future optimizations implemented in neural network frameworks.
- Users can benefit from native hardware acceleration.
- Users can benefit from having a unique platform to support both traditional and neural network models.
- Users don’t have to re-engineer their models.
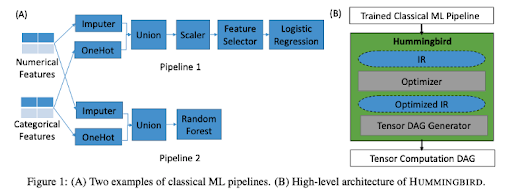
Additionally, Hummingbird also provides a convenient uniform inference API following the Sklearn API. This allows swapping Sklearn models with Hummingbird-generated ones without having to change the inference code.

Demo
Hummingbird's syntax is intuitive and minimal. To run your traditional ML model on DNN frameworks, you only need to import hummingbird.ml and add convert(model, 'dnn_framework') to your code. Below is an example using a scikit-learn random forest model and PyTorch as the target framework.
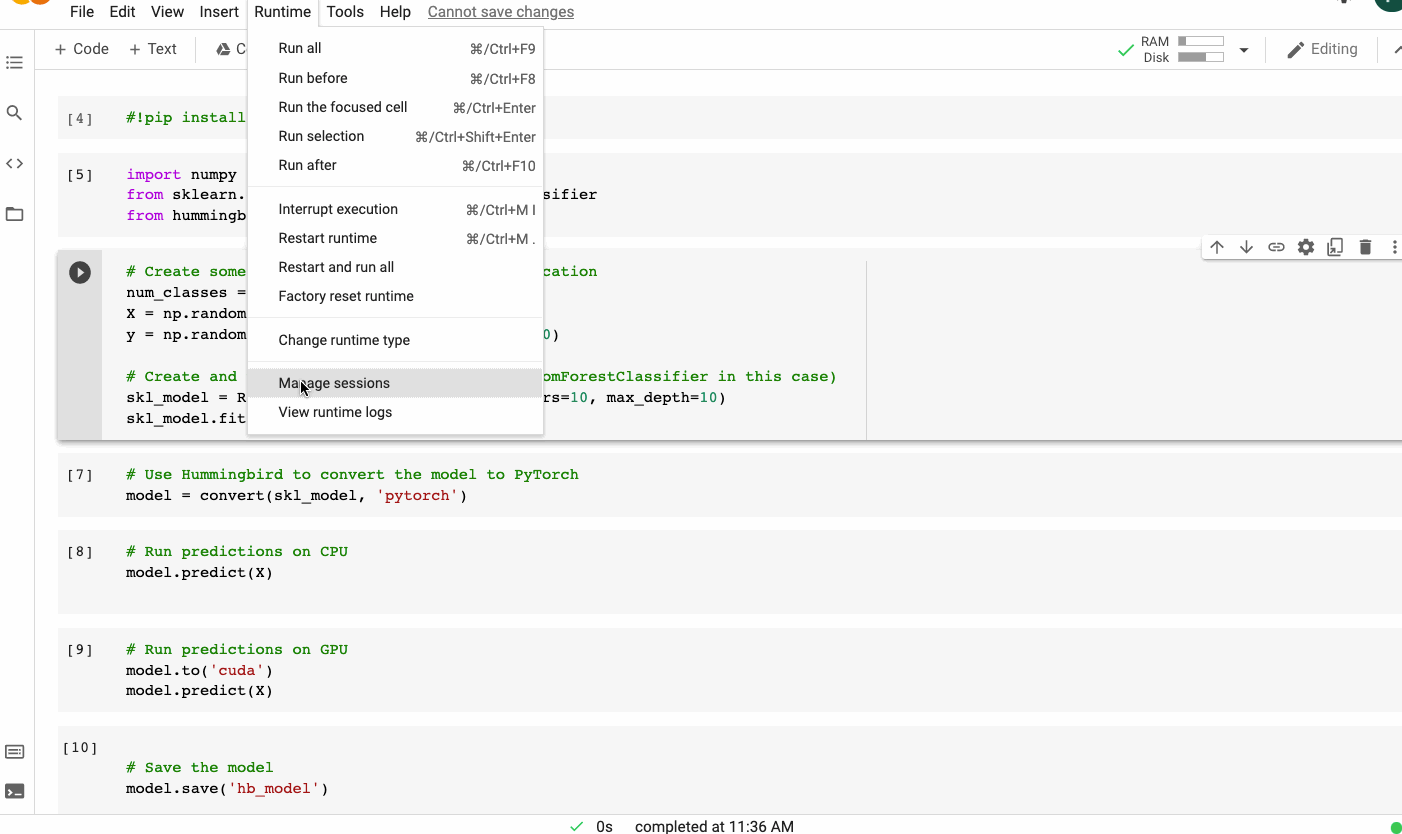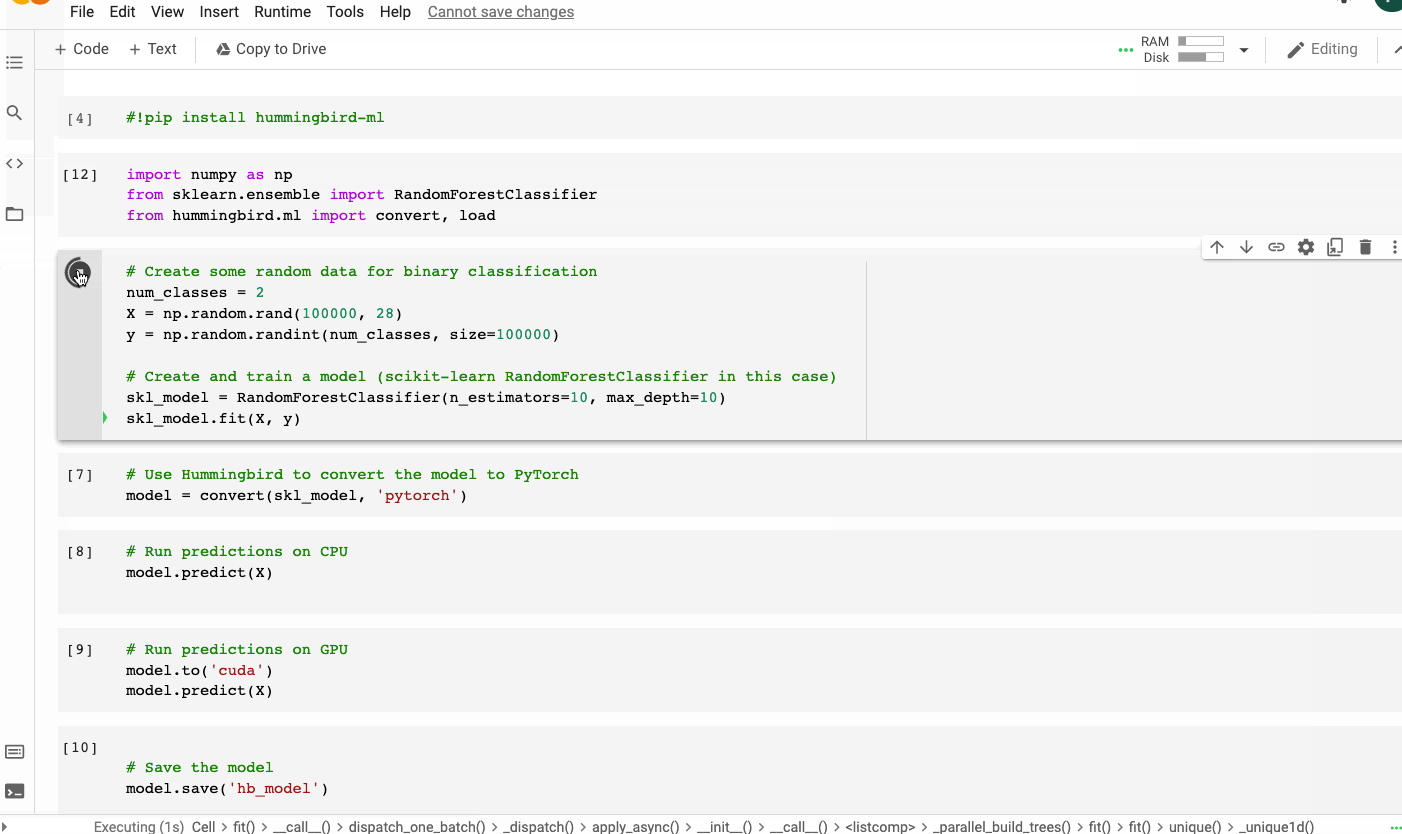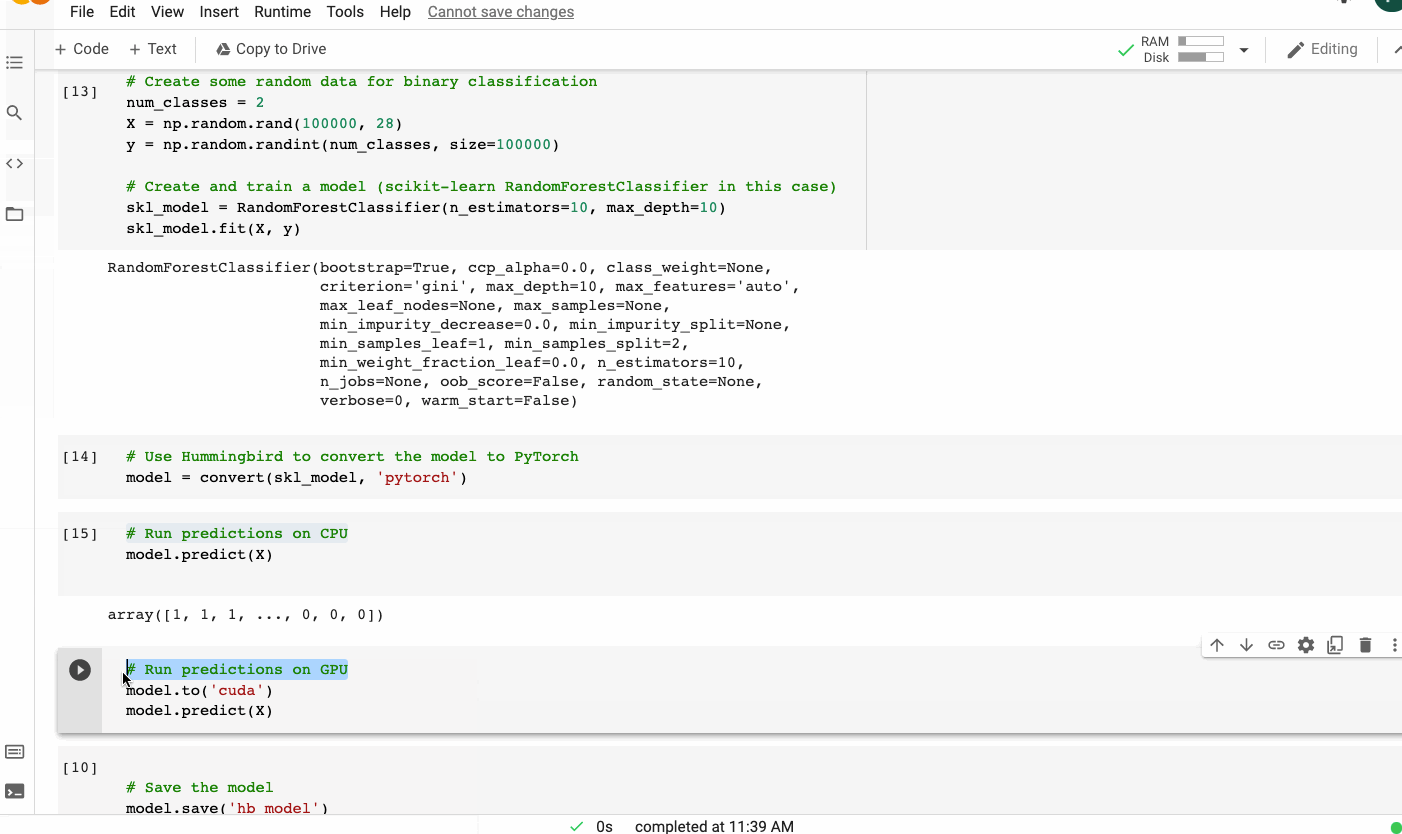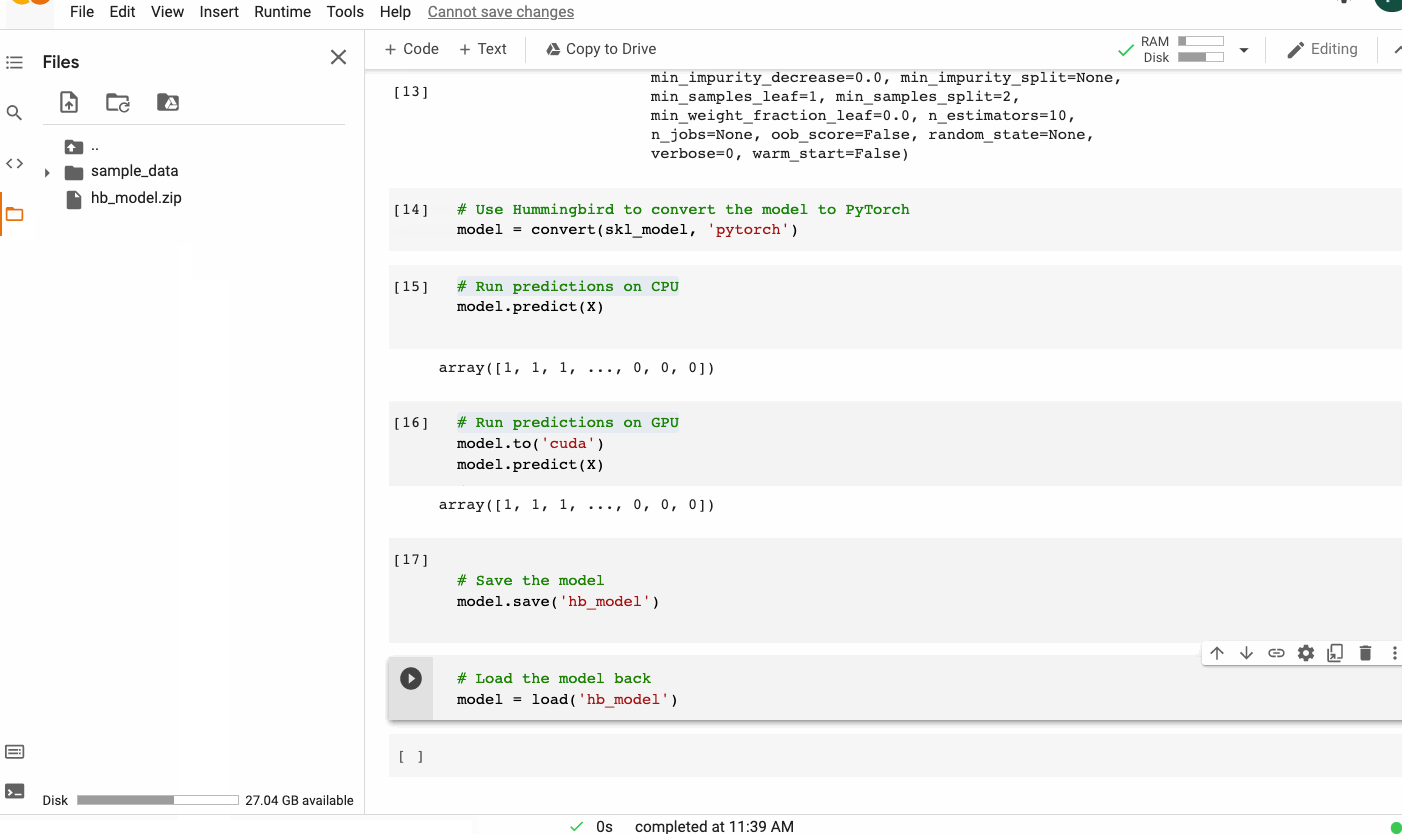
2. Top2Vec
Text documents contain a lot of information. Sifting through them manually is hard (and time consuming). Topic modeling is one technique widely used in industry to discover topics in a large collection of documents automatically. Some of the traditional and most commonly used methods are Latent Dirichlet Allocation (LDA) and Probabilistic Latent Semantic Analysis (PLSA). However, these methods suffer from drawbacks like not considering the semantics or ordering of the words. Top2vec is an algorithm that leverages joint document and word semantic embedding to find topic vectors. Here’s an excerpt from the paper:
“This model does not require stop-word lists, stemming or lemmatization, and it automatically finds the number of topics. The resulting topic vectors are jointly embedded with the document and word vectors with distance between them representing semantic similarity. Our experiments demonstrate that Top2vec finds topics which are significantly more informative and representative of the corpus trained on than probabilistic generative models. Even, Pre-trained Universal Sentence Encoders and BERT Sentence Transformer are available in encoding.”
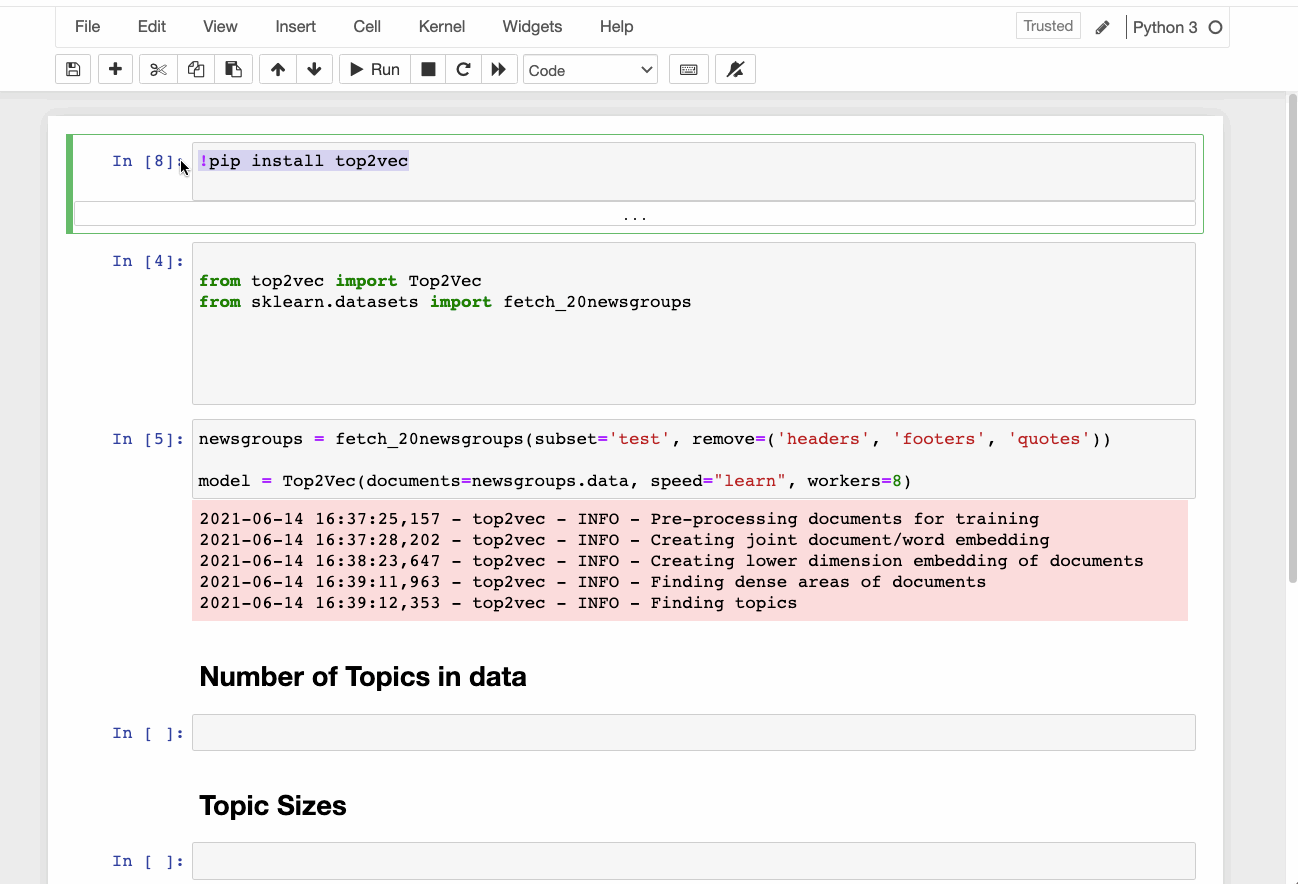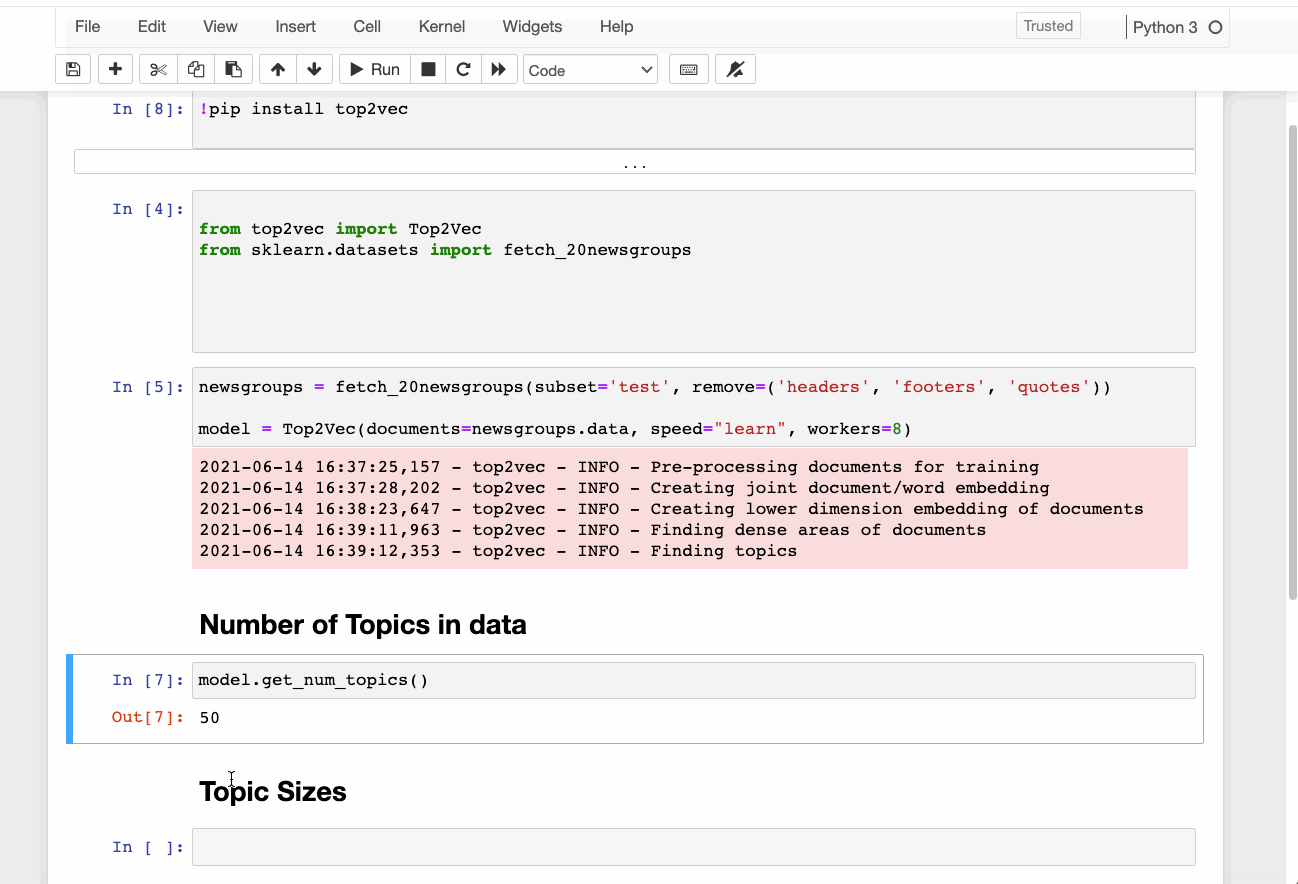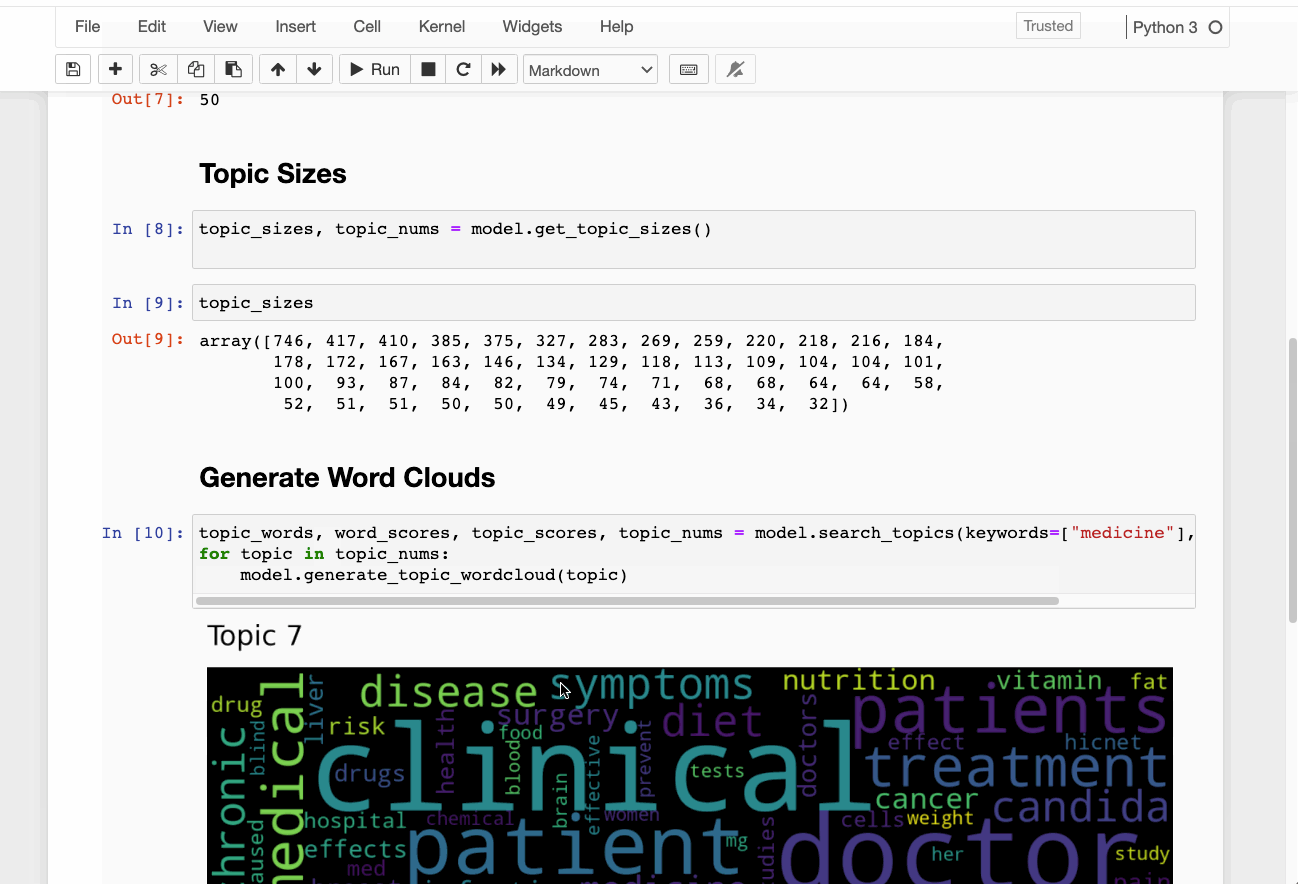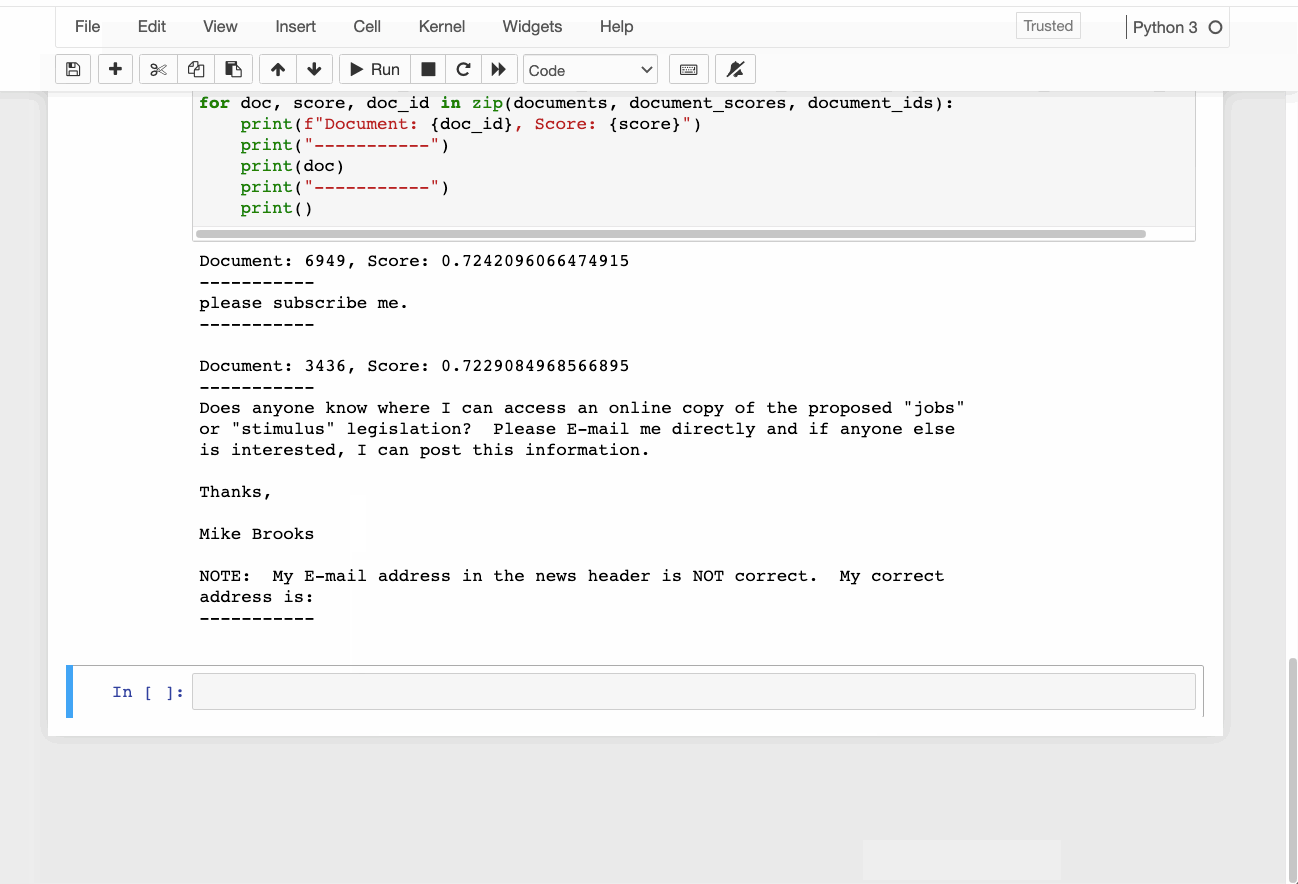
Once we’ve trained a Top2Vec model, we can do the following:

Demo
Here is a demo of training a Top2vec model on the 20newsgroups data set. I’ve taken the example has been taken from their official Github repo.
3. BERTopic
BERTopic is another topic modeling technique that leverages BERT embeddings and a class-based TF-IDF to create dense clusters allowing for easily interpretable topics while keeping important words in the topic descriptions. It also supports visualizations similar to LDAvis. Here’s a quick summarization of the capabilities of BERTopic.

Demo
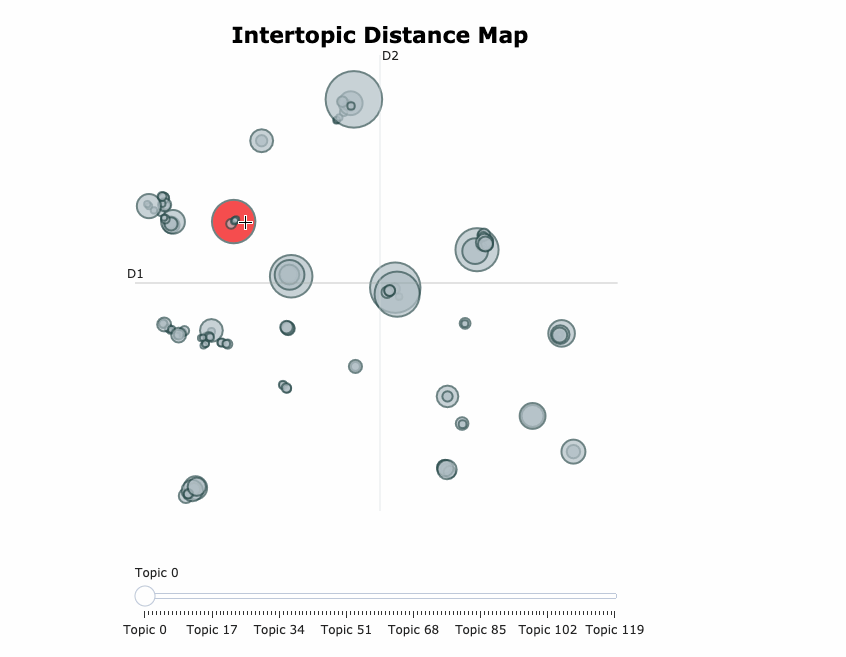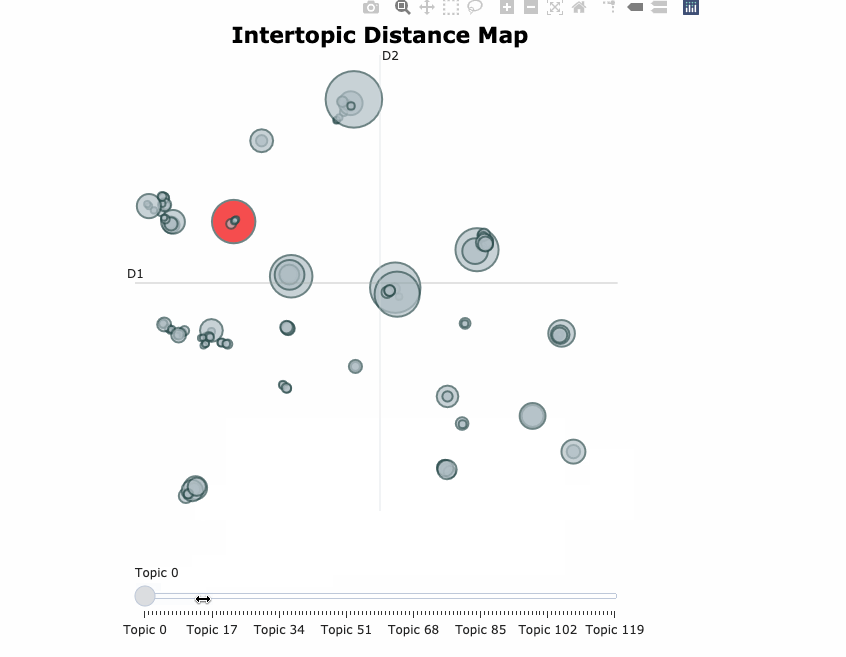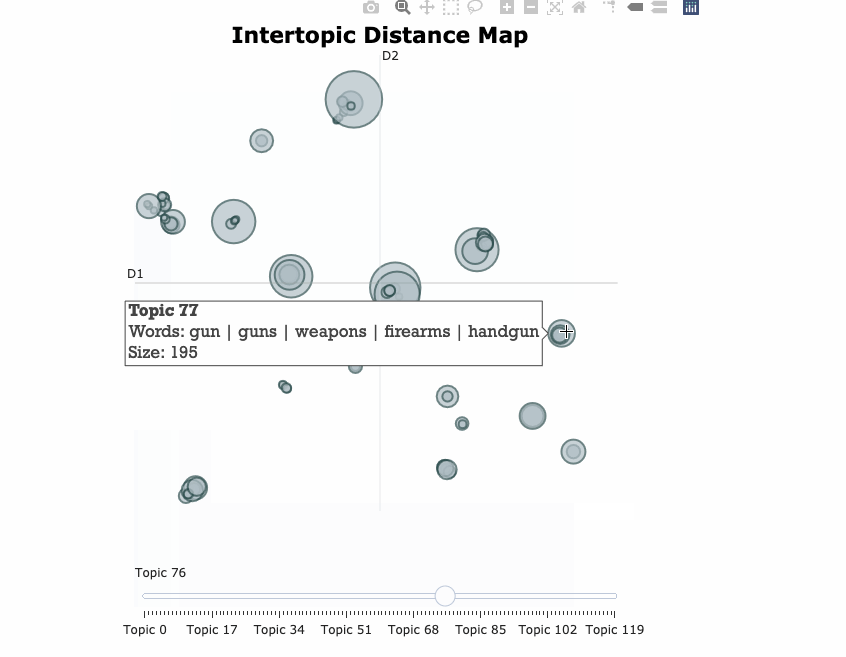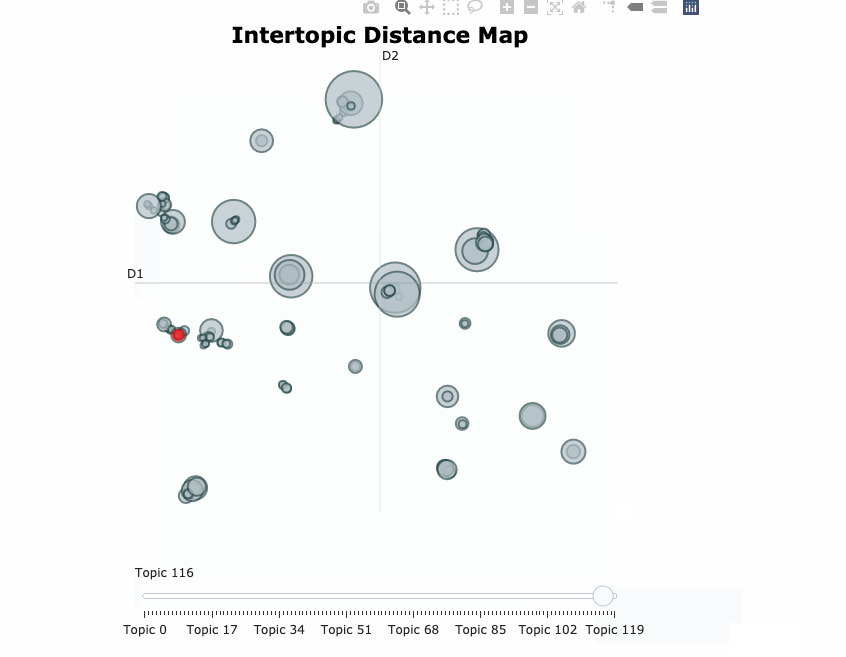
Here’s a visualization of the topics generated after training a BERTopic model on 20newsgroups data set.
4. Captum
Captum is a model interpretability and understanding library for PyTorch. Captum means comprehension in Latin, and it contains general-purpose implementations of integrated gradients, saliency maps, smoothgrad, vargrad and others for PyTorch models. In addition, Captum has quick integration for models built with domain-specific libraries such as torchvision, torch text and others. Captum also provides a web interface called Insights for easy visualization and access to a number of our interpretability algorithms.
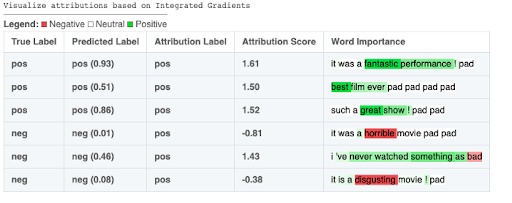
Note: Captum is currently in beta and under active development!
Demo
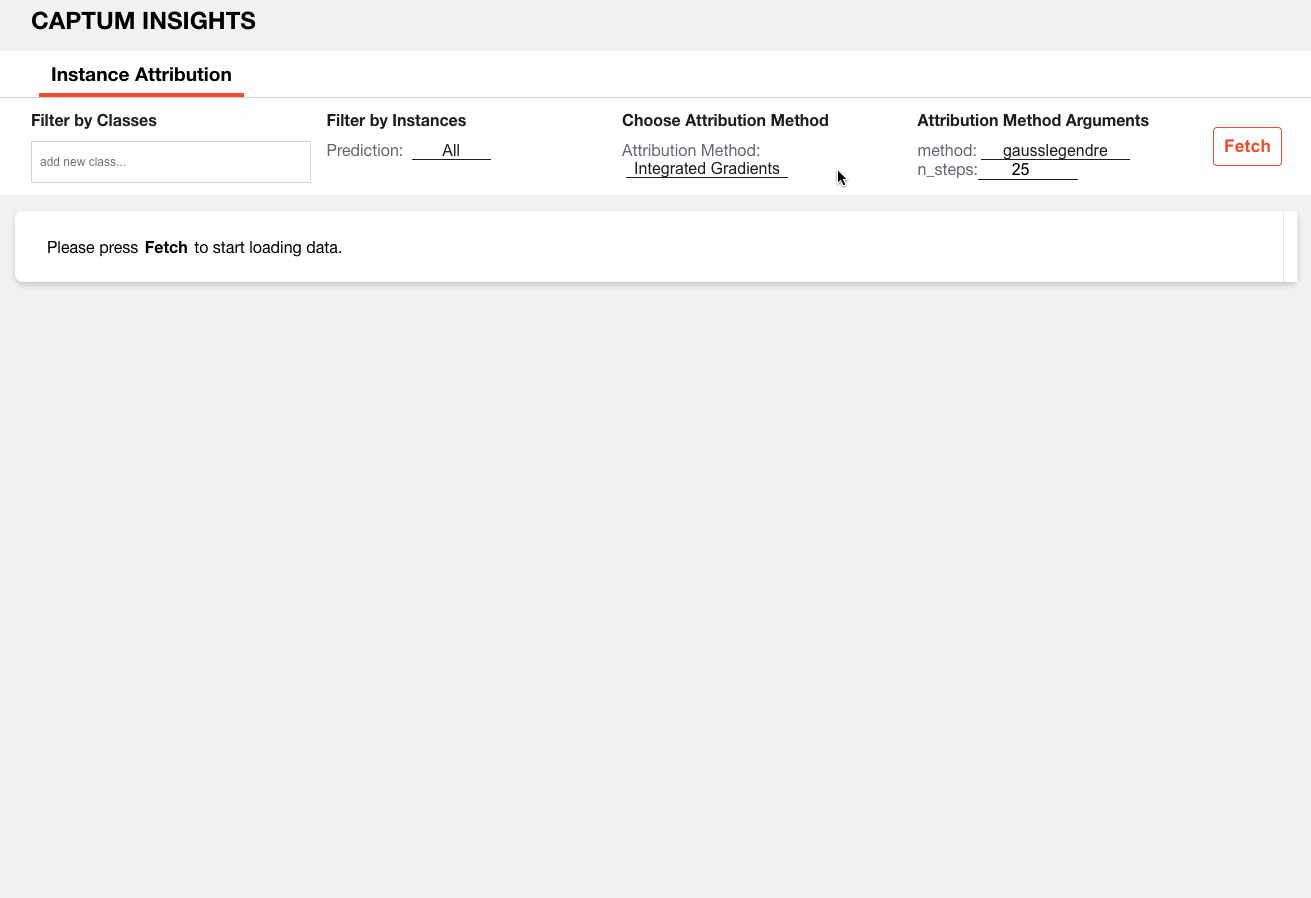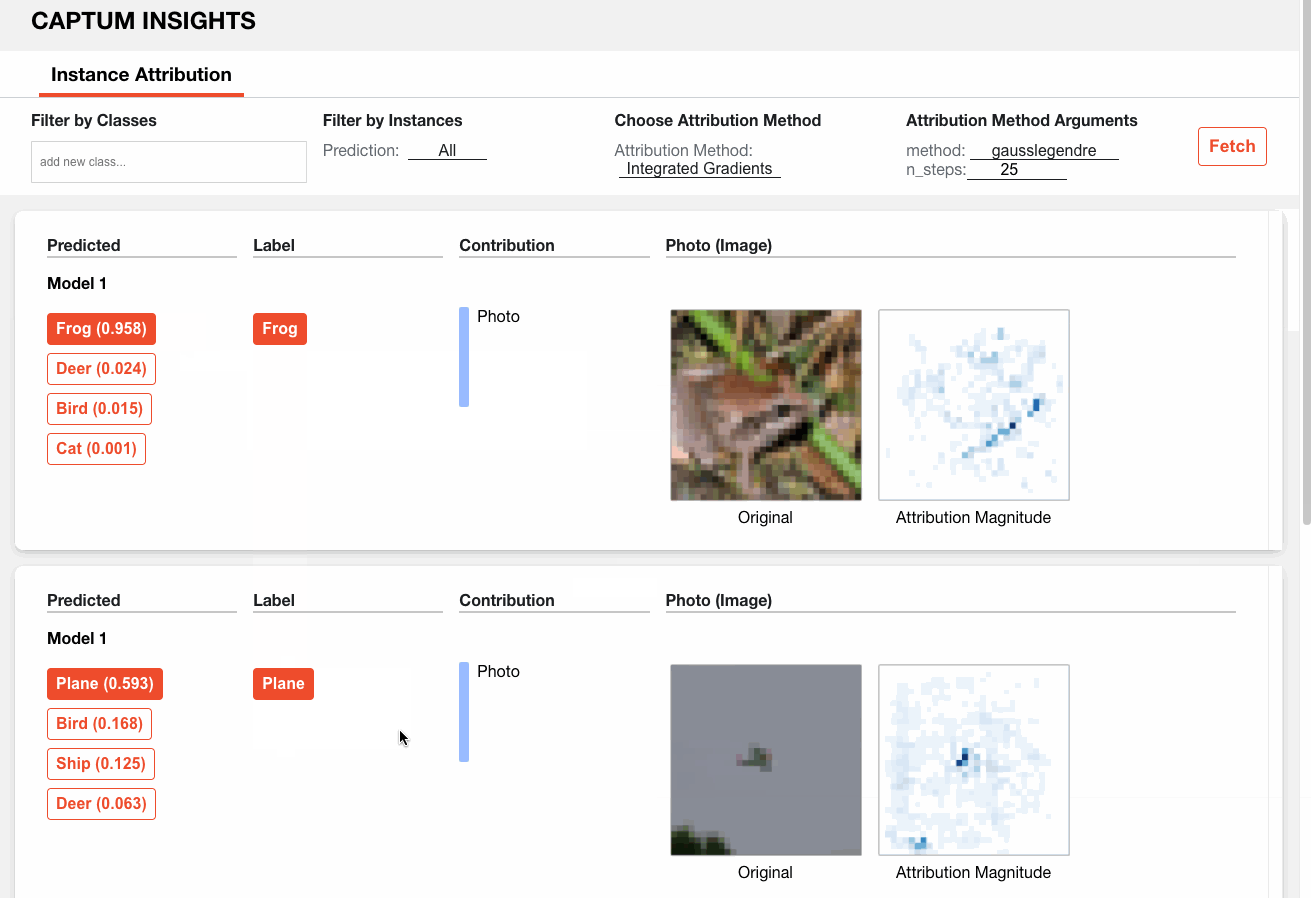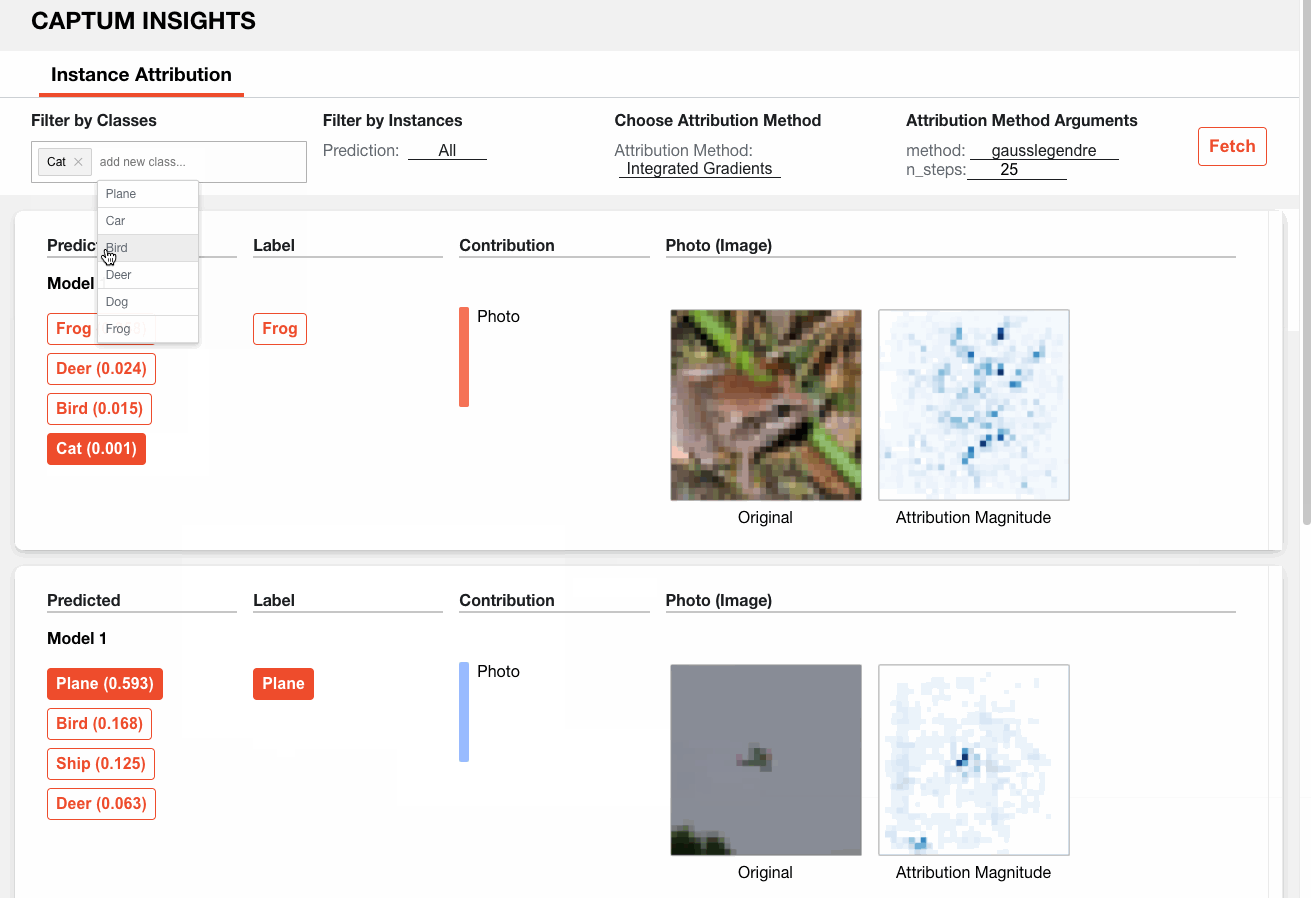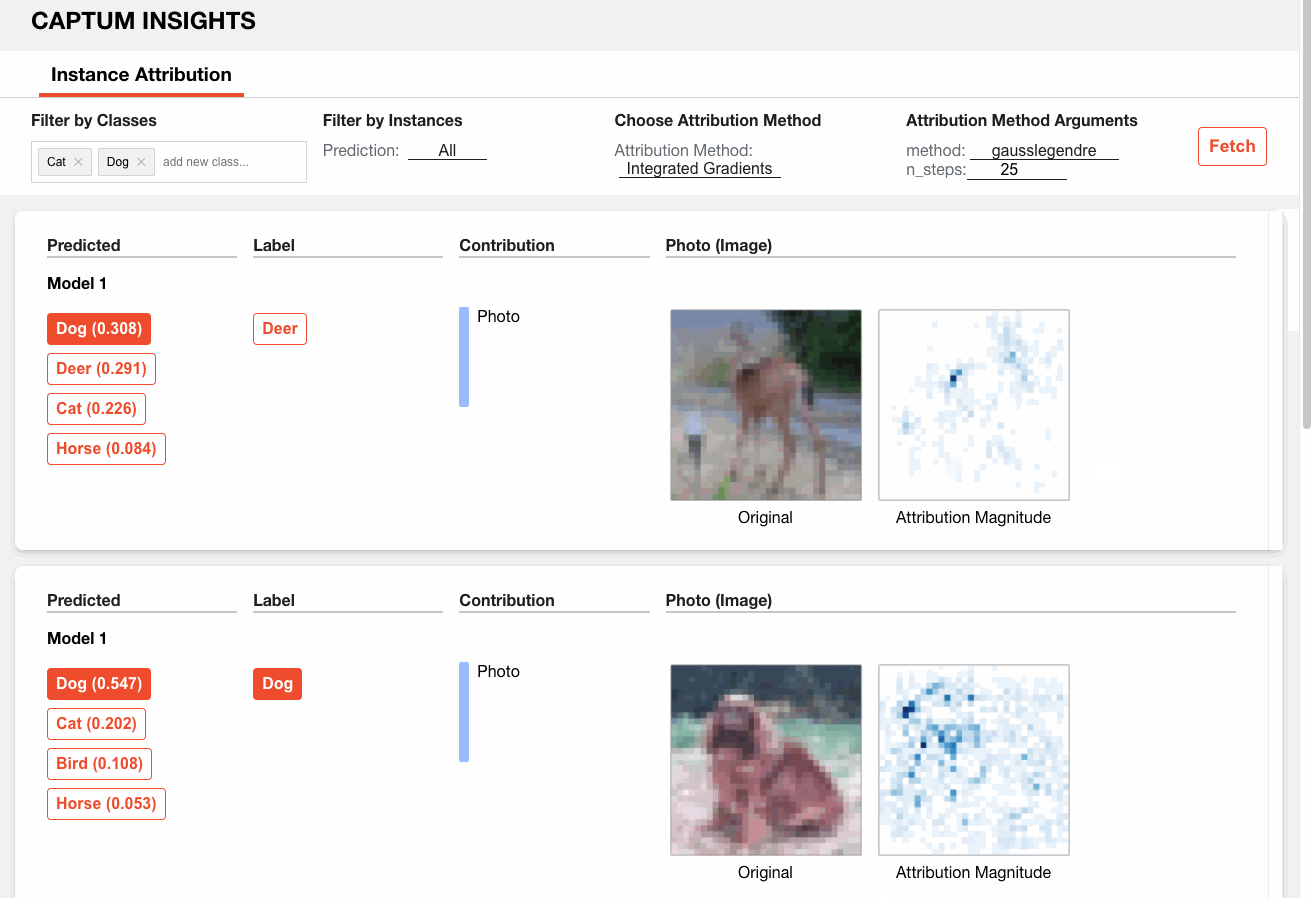
Here is how we can analyze a sample model on CIFAR10 via Captum Insights:
5. Annoy
Annoy stands for Approximate Nearest Neighbors. It’s built in C++ but comes with bindings in Python, Java, Scala, R and Ruby. Annoy is used to do (approximate) nearest neighbor queries in high-dimensional spaces. Even though many other libraries perform the same operation, Annoy comes with some great add ons. It creates large read-only file-based data structures that are mapped into memory so that many processes may share the same data. Annoy, built by Erik Bernhardsson, is used at Spotify for music recommendations, where it is used to search for similar users/items.
Demo
Here’s how we can use Annoy to find the 100 nearest neighbors.
These are the libraries that I find most interesting, useful and worth sharing. I’m sure you would like to explore them and see how you could use them in your area of expertise. Even though we already have innumerable libraries to tinker with, exploring new ones is a great way to develop as data science professionals.



